







来源:专知
本文为论文介绍,建议阅读5分钟
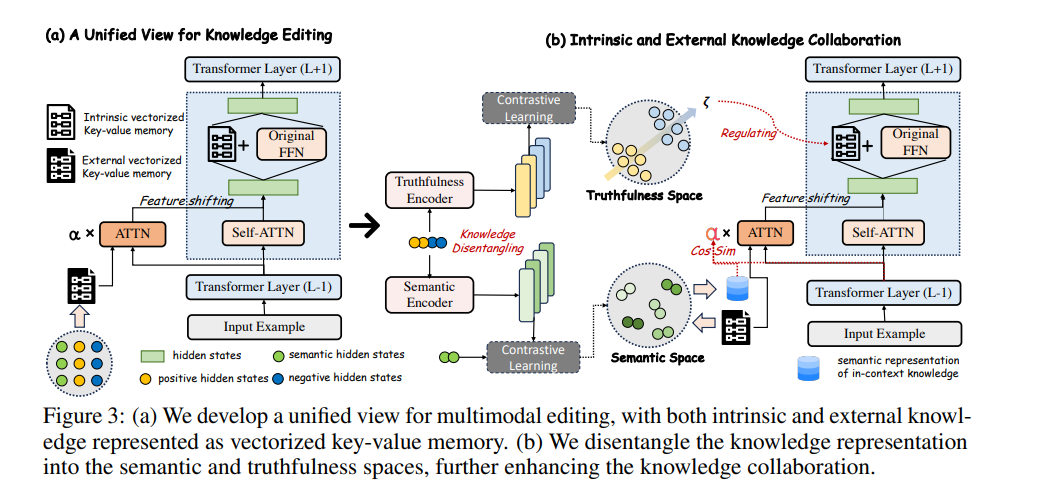
我们进一步通过将知识表示解耦为语义空间和真实性空间来促进知识协作。
随着多模态大语言模型 (MLLMs) 的快速发展,有效的知识编辑也面临着巨大的挑战。现有方法,包括内在知识编辑和外部知识检索,各自具有优缺点,但在应用于 MLLMs 时,难以平衡可靠性、通用性和局部性等理想属性。在本文中,我们提出了一种新的多模态编辑方法 UniKE,它为内在知识编辑和外部知识检索建立了统一的视角和范式。两种类型的知识都被概念化为向量化的键值存储,其相应的编辑过程类似于人类认知中的同化和顺应阶段,且在相同的语义层次上进行。在这样一个统一框架内,我们进一步通过将知识表示解耦为语义空间和真实性空间来促进知识协作。大量实验验证了我们方法的有效性,确保编辑后的 MLLM 同时保持出色的可靠性、通用性和局部性。UniKE 的代码将发布于 https://github.com/beepkh/UniKE。
https://arxiv.org/pdf/2409.19872
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









