







来源:专知
本文约1000字,建议阅读5分钟本文深入探讨伪标签不平衡现象,并识别出两大关键诱因:概念不匹配与 概念混淆。
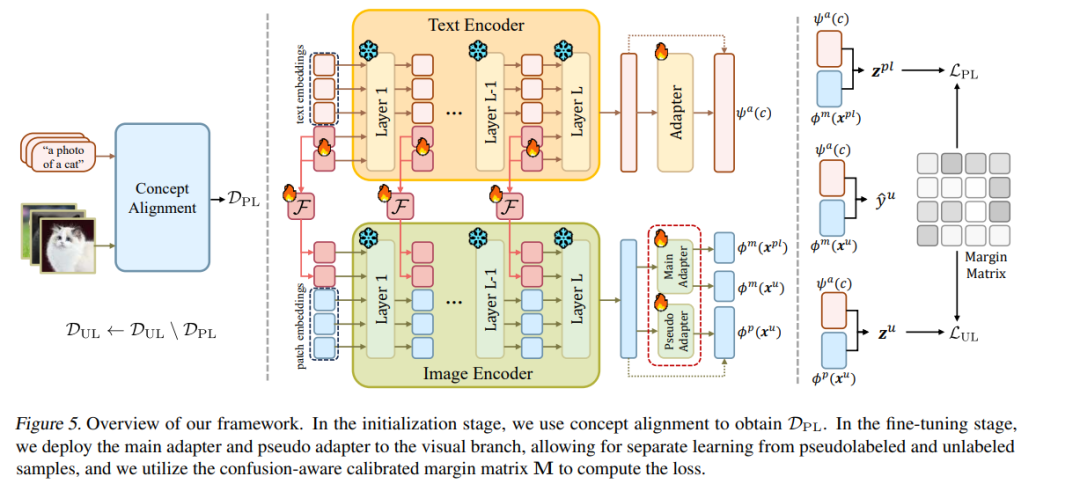
近年来,利用伪标签将视觉-语言模型(VLMs)适配至下游任务,逐渐引起了广泛关注。然而,VLMs 所生成的伪标签通常存在类别不平衡问题,进而导致模型性能下降。尽管现有方法已尝试采用多种策略缓解这一问题,但对其根本原因的研究仍显不足。为填补这一空白,本文深入探讨伪标签不平衡现象,并识别出两大关键诱因:概念不匹配与 概念混淆。
为缓解这两个问题,我们提出了一个新颖的框架,结合了概念对齐机制与混淆感知校准边界机制。该方法的核心在于增强表现较差的类别,并推动模型在各类别间实现更加平衡的预测,从而有效缓解伪标签的不平衡问题。
我们在六个基准数据集、三种学习范式上进行了大量实证实验,结果表明,所提方法在伪标签的准确性与平衡性方面均实现了显著提升,相较当前最先进方法取得了 6.29% 的相对性能提升。
我们的代码已开源,详见:
https://anonymous.4open.science/r/CAP-C642/
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









