







来源:时序人
本文约2300字,建议阅读9分钟
研究者为了验证 Fredformer 模型的有效性,设计了一系列的实验。Transformer 模型已在时间序列预测中展现了卓越的性能。然而,在一些复杂场景中,它倾向于学习数据中的低频特征,而忽略了高频特征,表现出一种频率偏差。这种偏差阻碍了模型准确捕捉重要的高频数据特征。
本文介绍一篇来自 KDD 2024 的论文,这是首篇研究时间序列预测中频率偏差问题的文章。其研究者通过实证分析来理解这种偏差,并发现频率偏差源于模型不成比例地关注具有更高能量的频率特征。基于分析,研究者提出了 Fredformer,这是一个基于 Transformer 的框架,旨在通过在不同频率带之间均衡地学习特征来减轻频率偏差。这种方法防止了模型忽视对准确预测至关重要的低幅特征。广泛的实验表明了这种方法的有效性,在实现了可比性能的同时,参数规模更少,计算成本更低。

【论文标题】
Fredformer: Frequency Debiased Transformer for Time Series Forecasting
【论文地址】
https://arxiv.org/abs/2406.09009
【论文源码】
https://github.com/chenzRG/Fredformer
论文背景
现有的 Transformer 模型在时间序列预测任务中,倾向于捕捉低频特征而忽略高频特征,这种频率偏差问题会导致模型无法准确捕捉重要的高频数据特征。而在复杂的时间序列预测场景中,准确捕捉各种时间变化(如趋势、季节性和波动)对于提高预测准确性至关重要。现有的方法在处理这些复杂变化时存在局限性。
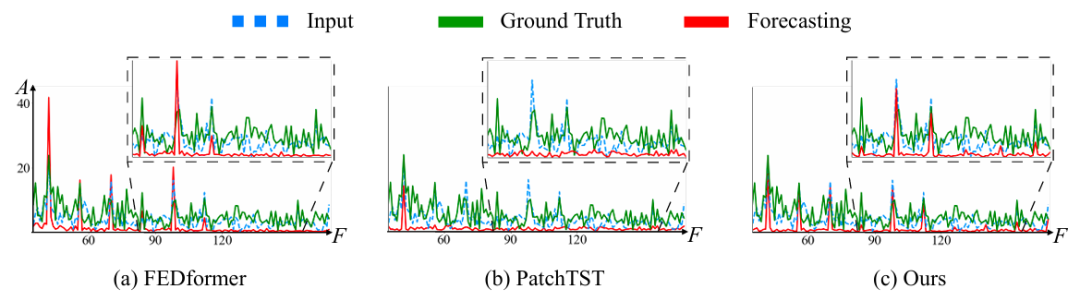
图1:模型效果对比
从模型的角度来看,研究者注意到 Transformer 中普遍存在的一种学习偏差问题,即自注意力机制通常会优先考虑低频特征,而忽视高频特征。这种微妙的问题也可能出现在时间序列预测中,可能会偏向模型结果并导致信息丢失。
研究者探索了通过频率域建模来捕获复杂变化以进行准确时间序列预测的一个方向,进而提出了 Fredformer,这是一个去偏的 Transformer 模型。Fredformer 继承了频率分解的思路,且进一步研究了如何促进 Transformer 在学习频率特征时的使用。为了提高模型方法的有效性,研究者提供了对时间序列预测中频率偏差的全面分析以及去偏策略。该工作的主要贡献在于三个方面:
问题定义:研究者进行了实证研究,以调查这种偏差是如何被引入到时间序列预测 Transformer 中的。文中观察到,主要原因是关键频率成分之间的比例差异。值得注意的是,这些关键成分在预测的历史数据和真实数据中应该是一致的。此外,研究者还调查了影响去偏的目标和关键设计。
算法设计:Fredformer 有三个关键组件:用于频率带的补丁操作、用于减轻比例差异的子频率独立归一化,以及每个子频率带内的通道注意力,用于公平学习所有频率和注意力去偏。
适用性:Fredformer 采用 Nyström 近似来降低注意力图的计算复杂性,从而实现了具有竞争性能的轻量级模型。这为高效的时间序列预测开辟了新的机会。
理论分析
研究者通过两个案例研究来展示时间序列数据的频率属性如何导致 Transformer 模型的预测偏差,以及对潜在去偏策略的实证分析。如下图所示:
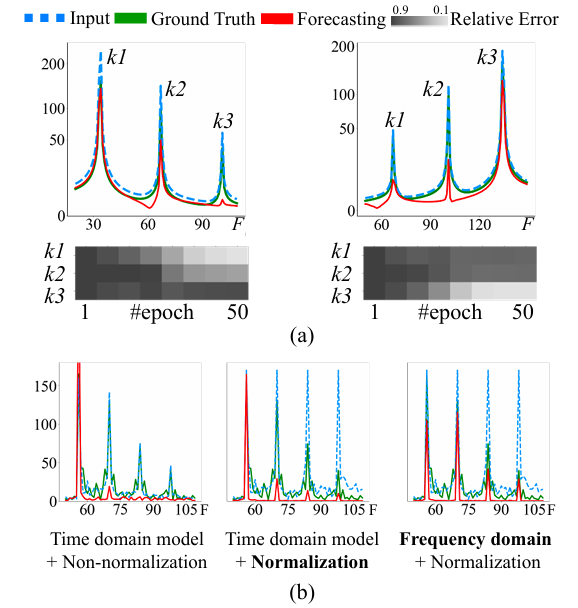
图2:两个案例研究可视化图
案例a:
通过生成具有不同频率成分比例的单通道时间序列数据,并使用 Transformer 模型进行预测,展示了模型在训练过程中对不同频率成分的捕捉情况。结果表明,模型倾向于关注低频成分,而忽略了高频成分。
案例b:
探讨了不同的建模策略对于去偏的影响,包括在频率域进行建模和在时间域进行建模,并引入了频率局部归一化的概念。
研究者引入了一个基于傅里叶分析的相对误差度量方法来量化 Transformer 模型输出的频率偏差。基于上述分析,研究者提出了直接在频率域建模,并结合比例缓解策略来实现去偏的潜力。
模型方法
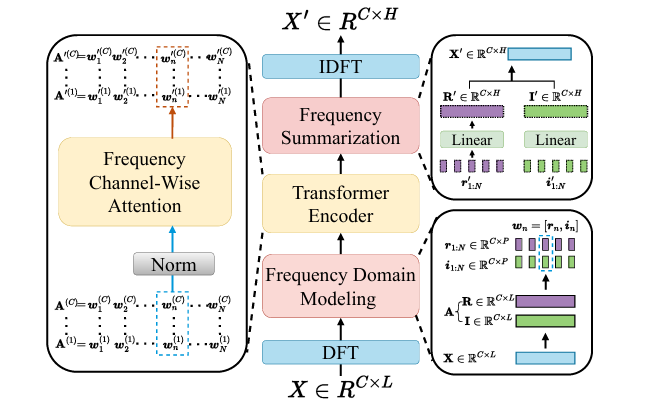
图3:Fredformer模型框架
Fredformer 模型是通过一系列创新的设计来解决时间序列预测中的频率偏差问题,其架构包括以下主要组件:
01 DFT到IDFT的基础架构
使用离散傅里叶变换(DFT)将输入时间序列分解为频率成分,并通过逆离散傅里叶变换(IDFT)重构预测结果。
首先,模型使用 DFT 将输入的时间序列数据分解成频率系数。然后,通过一个 Transformer 编码器对频率系数进行处理,学习去偏的频率特征。最后,使用 IDFT 将处理后的频率输出重构回时域信号。
02 频率细化与归一化
对频率谱进行细分,使用非重叠的补丁操作将频率成分分为多个子频率带,以避免不同频率成分之间的相互影响。通过对频率补丁进行归一化,消除不同频率成分之间的比例差异,确保模型对所有关键频率成分的均等关注。
03 频率局部独立建模
在归一化后的子频率分块上,模型部署了 Transformer 编码器来独立学习每个分块的特征。通过这种方式,模型能够专注于相同频率带内跨通道的相关性,而不是不同频率成分之间的幅度差异,从而实现去偏。
04 频率汇总
在学习到每个子频率带的特征之后,模型通过线性变换和 IDFT 将这些特征信息汇总,形成最终的预测输出。
实验效果
研究者为了验证 Fredformer 模型的有效性,设计了一系列的实验。研究者选择了八个真实世界的时间序列数据集,包括天气、电力变压器温度(ETT)、电力消耗、交通和太阳能等数据。
研究者将 FredFormer 与多个现有的最先进(SOTA)模型进行比较,包括但不限于iTransformer、PatchTST、Crossformer、FEDformer等。也包括了一些非 Transformer 模型,如线性模型和 TCN 模型。实验结果如下表所示:
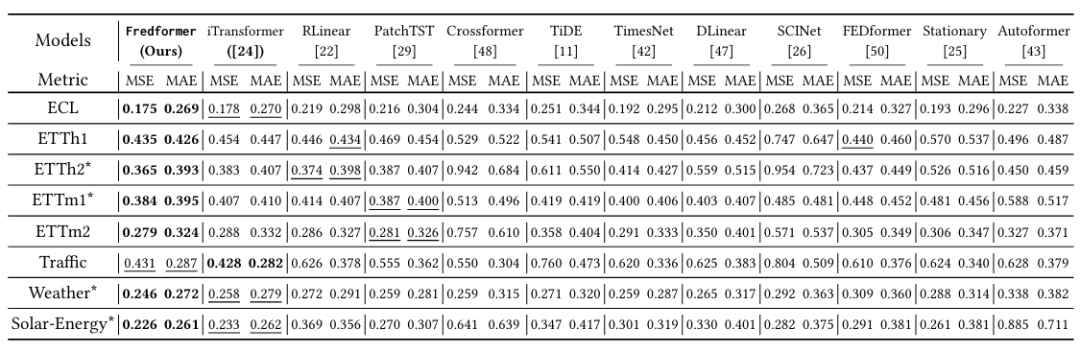
表1:多变量预测下不同预测长度的表现
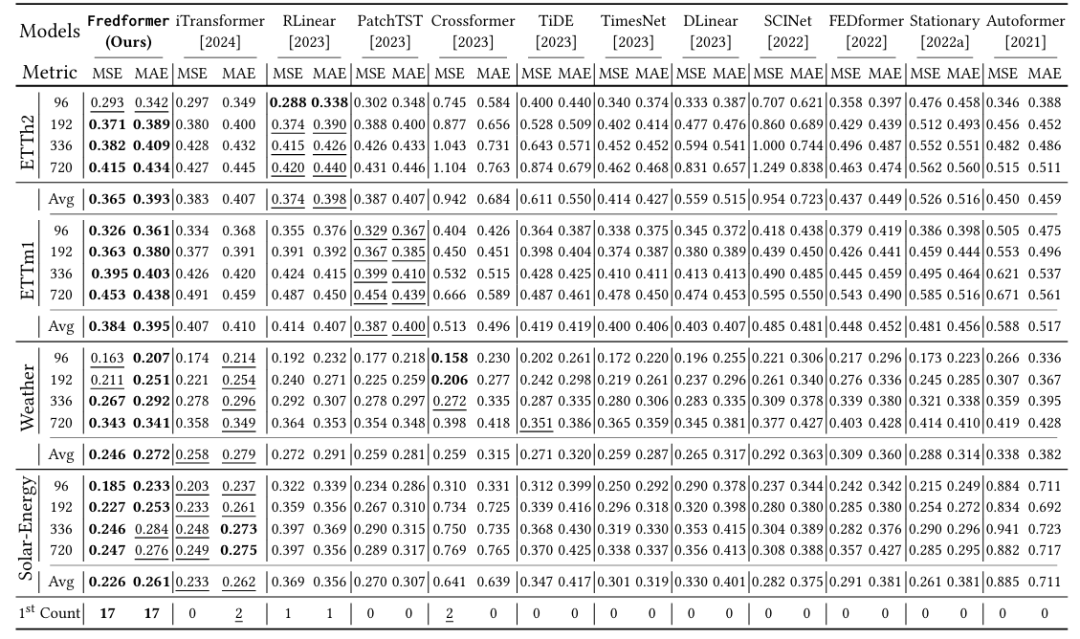
表2:所有数据完整测试结果
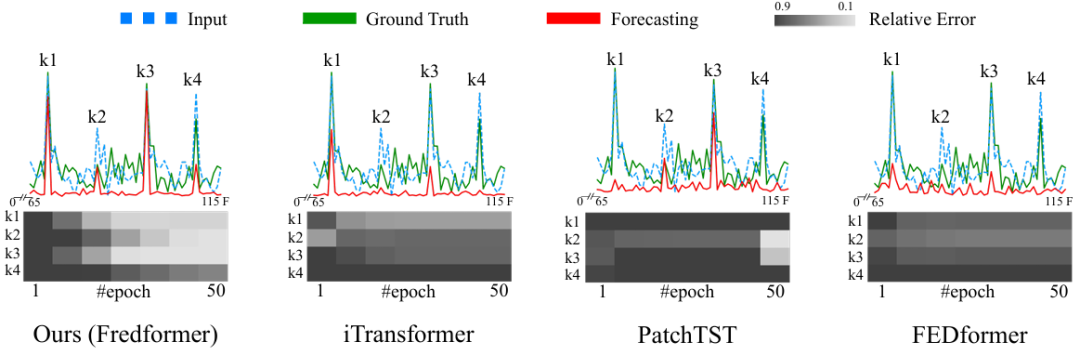
使用 DFT 可视化模型输出、输入和真实数据之间的频率偏差。通过热图展示了不同模型在训练过程中对特定频率成分的捕捉情况。
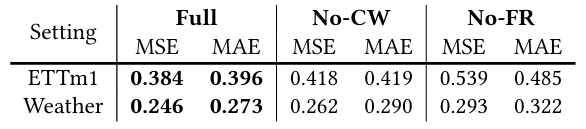
通过移除 Fredformer 模型中的特定组件(如通道注意力和频率细化)来评估这些组件对性能的影响。展示了不同配置下模型的预测准确性,以证明模型设计的合理性。
编辑:黄继彦
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









