







来源:人工智能前沿讲习
本文共3300字,建议阅读6分钟
对于模型推理性能的提升来说,什么有效?什么无效?「推理」已成为语言模型的下一个主要前沿领域,近期学术界和工业界都取得了突飞猛进的进展。
在探索的过程中,一个核心的议题是:对于模型推理性能的提升来说,什么有效?什么无效?
DeepSeek - R1 论文曾提到:「我们发现将强化学习应用于这些蒸馏模型可以获得显著的进一步提升」。3 月 20 日,论文《Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't》再次验证了 RL 对于蒸馏模型是有效的。
尽管这些论文的结论统统指向了强化学习带来的显著性能提升,但来自图宾根大学和剑桥大学的研究者发现,强化学习导致的许多「改进」可能只是噪音。

论文标题:
A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility
论文链接:
https://arxiv.org/pdf/2504.07086
「受推理领域越来越多不一致的经验说法的推动,我们对推理基准的现状进行了严格的调查,特别关注了数学推理领域评估算法进展最广泛使用的测试平台之一 HuggingFaceH4,2024;AI - MO。」
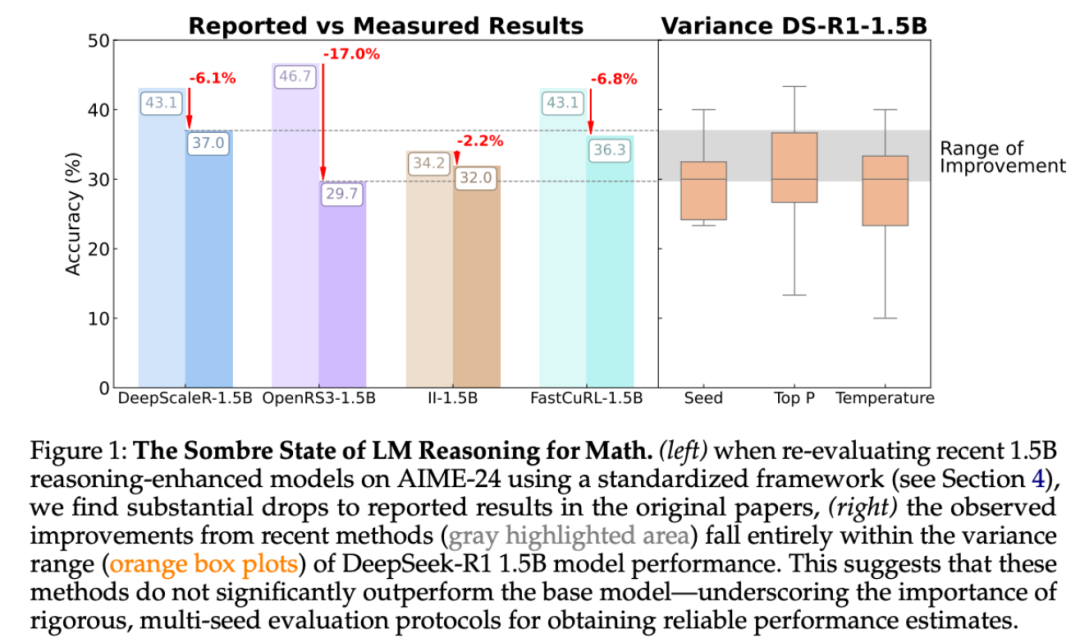
论文指出,在 AIME24 等小型基准测试中,结果极不稳定:仅仅改变一个随机种子就足以使得分发生几个百分点的变化。当在更可控和标准化的设置下评估强化学习模型时,其收益会比最初报告的要小得多,而且通常不具有统计显著性。
然而,一些使用强化学习训练的模型确实表现出了适度的改进,但这些改进通常比监督微调所取得的成果更弱,而且它们通常不能很好地推广到新的基准。
研究者系统分析了造成这种不稳定性的根本原因,包括采样差异、解码配置、评估框架和硬件异质性。我们表明,如果不仔细控制,这些因素会严重扭曲结论。与此同时,研究者提出了一套最佳实践,旨在提高推理基准的可重复性和严谨性。
AI 研究者 Sebastian Raschka 表示:「尽管强化学习在某些情况下可能有助于改进较小的蒸馏模型,但它的好处被夸大了,需要更好的评估标准来了解哪些方法真正有效。此外,这不仅仅是强化学习和推理模型的问题,我认为 LLM 研究整体上都受到了影响。」

探索推理的设计空间:什么最重要?
最近的以推理为重点的语言模型是在非常不同的条件下进行评估的,包括评估框架和硬件、随机种子数量、温度和核采样参数(top_p)的差异(见表 1)。
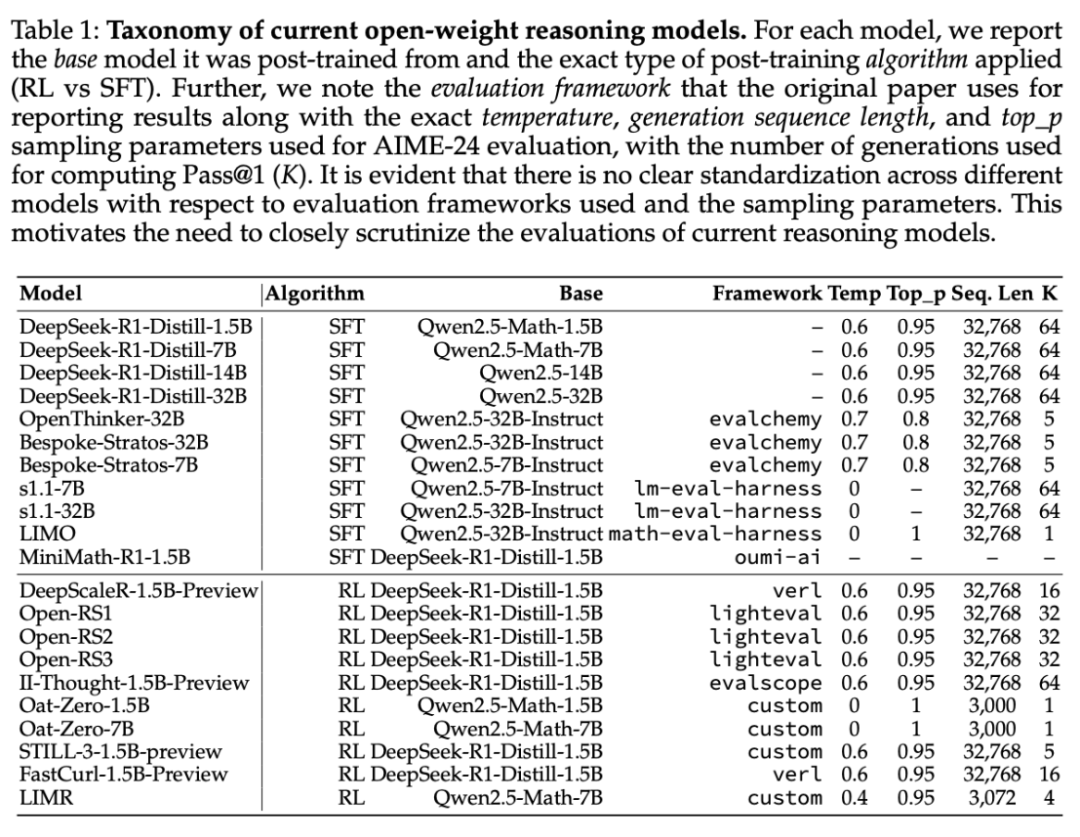
虽然此前的研究已经考察了采样参数在多选题和编码任务中的影响,但这些选择对开放式推理模型(特别是那些用强化学习训练的模型)的影响仍未得到充分探索。
本文的研究者系统地评估了这些设计选择如何影响性能,并强调了对结果可靠性影响最大的变异来源。
评估中的种子方差
研究者首先分析了评估过程中使用的随机种子所引起的方差,这是基准测试实践中经常被忽视的一个方面。近期的工作尽管要求统计的严谨性(如使用误差棒和多次运行),但评估经常依赖于单种子运行,从而掩盖了潜在的变异性。本文评估了九种模型中,每种模型在 20 次独立评估运行中种子引起的变异。结果如图 2 所示。
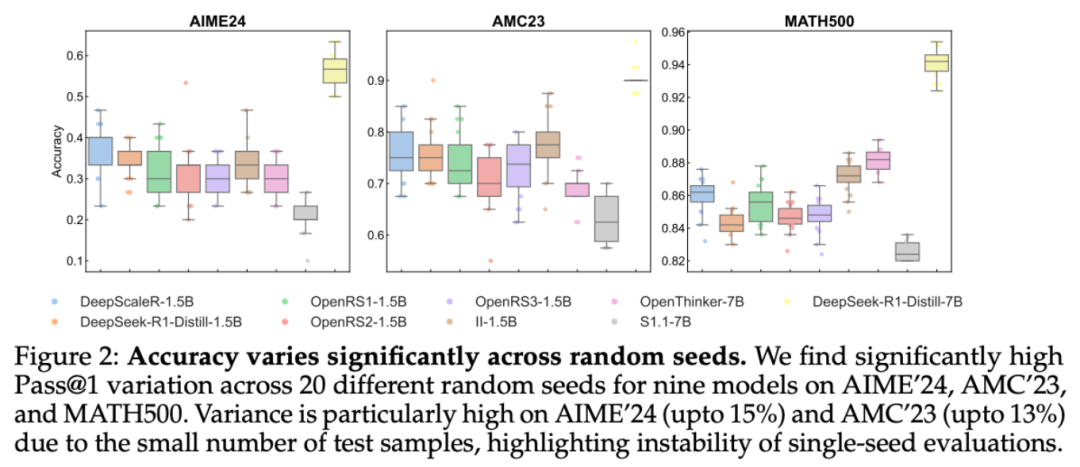
可以看到,Pass@1 值的标准偏差出奇地高,各种子的标准偏差从 5 个百分点到 15 个百分点不等。这一问题在 AIME'24 和 AMC'23 中尤为严重,这两个考试分别只有 30 和 40 个测试样本。仅一个问题的变化就会使 Pass@1 偏移 2.5 - 3.3 个百分点。
硬件和软件因素造成的差异
硬件和评估框架等非显而易见的因素也会造成性能差异,但这一点很少得到承认。模型通常在异构系统上进行测试,并使用不同的工具链进行评估。
硬件差异
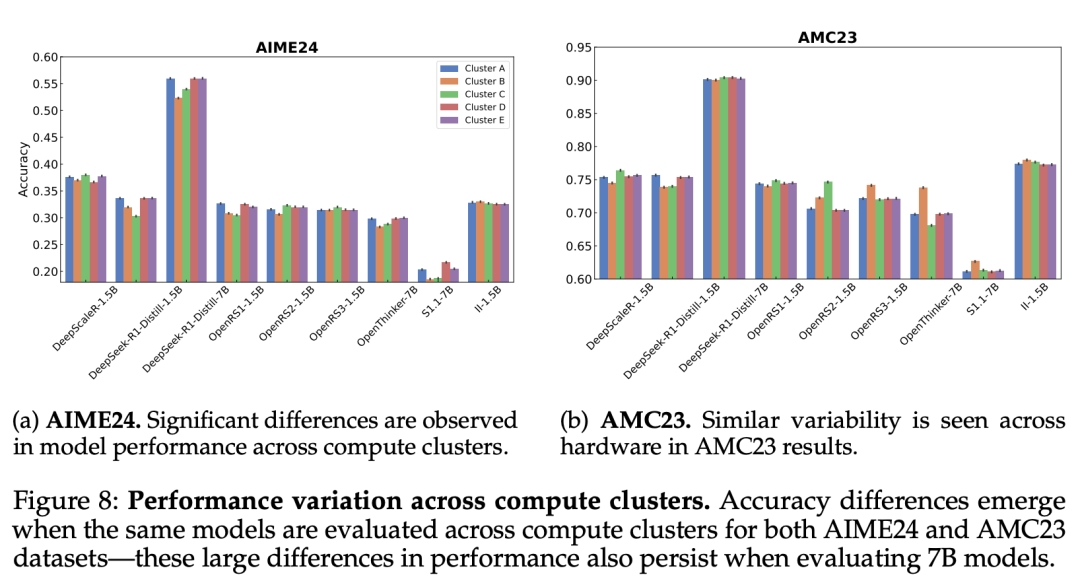
研究者在五个不同的计算集群上对同一模型进行了评估,每个集群的 GPU 类型和内存配置各不相同。
如图 8 所示,在 AIME'24 上,OpenRS - 1.5B 的性能差异高达 8%,DeepSeek - R1 - Distill - 7B 的性能差异为 6%,在 AMC'23 上也观察到了类似的趋势。众所周知,vLLM 等推理引擎对硬件差异非常敏感,而 PyTorch 或 CUDA 中的底层优化可能会引入非确定性,但结果表明,即使对多个种子进行平均,这些影响也会对基准精度产生显著影响。
不同 Python 框架下的评估
为了评估这种影响,研究者对 lighteval 和 evalchemy 进行了比较,同时保持所有其他变量固定不变:模型、数据集、硬件、解码参数和随机种子(每个模型 3 个)。
为了进行公平比较,研究者在单个 GPU 上以默认温度和 top_p 参数值对 DeepSeek - R1 - Distill - 1.5B 和 S1.1 - 7B 这两个模型进行了评估。为了提高鲁棒性,本文给出了三个种子的平均结果。
如表 2 所示,框架引起的差异通常很小(1 - 2pp),但在紧密聚类的情况下仍会影响模型排名。

Prompt 格式和上下文长度的影响
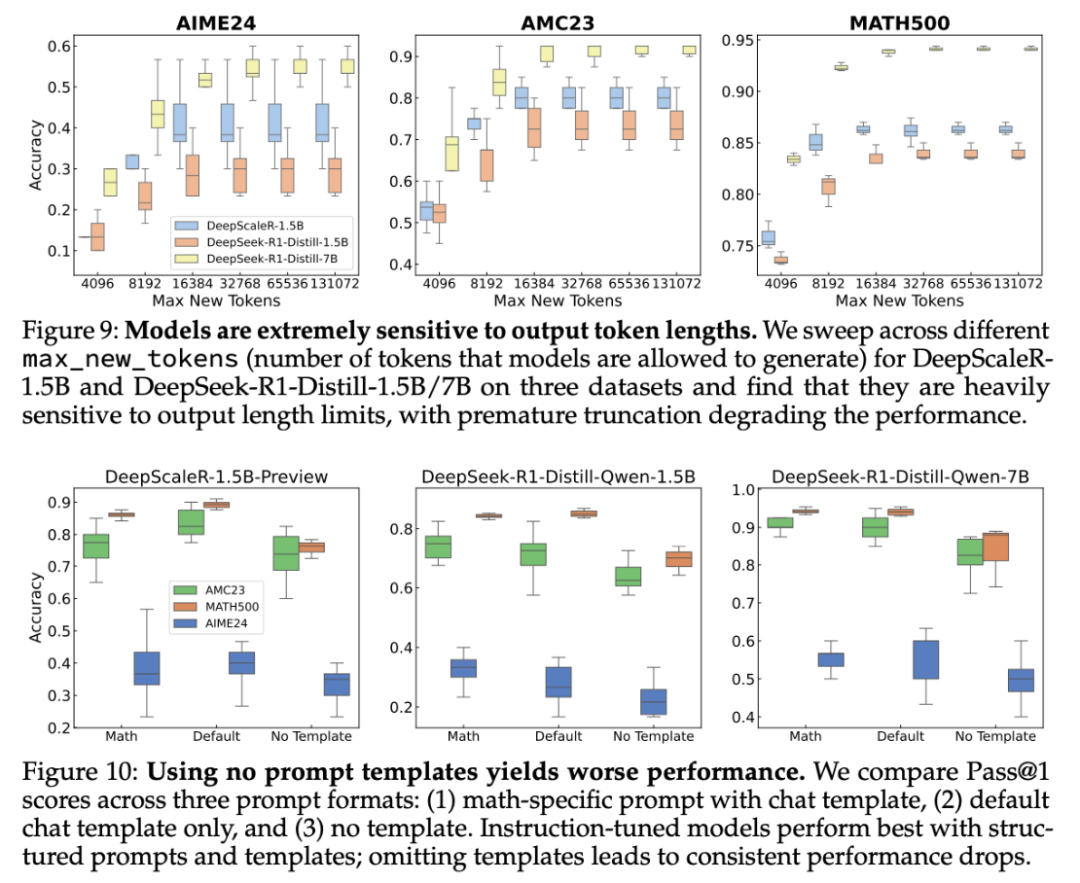
最大输出 token。如图 9 所示,减少 max_new_tokens 会降低性能,尤其是在长表单问题上。这种敏感度因模型和数据集而异。虽然减少这一设置可以降低成本,但可能会导致过早停止,从而导致错误答案。
Prompt 格式。提示格式对准确性有显著影响。如图 10 所示,模型在使用数学特定 Prompt 及其本地聊天模板时表现最佳。省略模板会导致性能下降,特别是对于经过指令调优的模型。
(一级)怎么解决?答案是「评估的标准化」
在本节中,研究者将对评估框架进行标准化,并对现有方法进行全面评估。关键结论如下:
大多数通过强化学习(RL)训练的 DeepSeek R1 - Distill 模型的变体未能显著提高性能(DeepscaleR 除外),这表明仍缺乏可靠和可扩展的强化学习训练方案。
尽管通过强化学习训练的方法通常能显著改善基础模型的性能,但指令调优依然优于强化学习训练的方法(Open Reasoner Zero 除外),这再次表明仍缺乏可靠和可扩展的强化学习训练方案。
在较大模型的推理轨迹上进行监督微调可在基准测试中获得显著且可推广的提升,且随着时间推移进展得以成功复制——这突显了其作为训练范式的稳健性和成熟性。
当前基于强化学习的方法非常容易过拟合,强调了需要更严格的异域基准测试。相比之下,SFT(监督微调)模型表现出更强的泛化能力和韧性。
较长的响应与较高的错误概率相关联,响应长度在 consensus@k 中是识别低置信度或失败生成的一种实用启发式思路。
准解码策略似乎足以捕捉模型在有效推理路径上的完整分布,反驳了多样性坍缩假说。
清醒的观察:结果
表 3 展示了实验结果,并对结果的不同方面进行了分析。
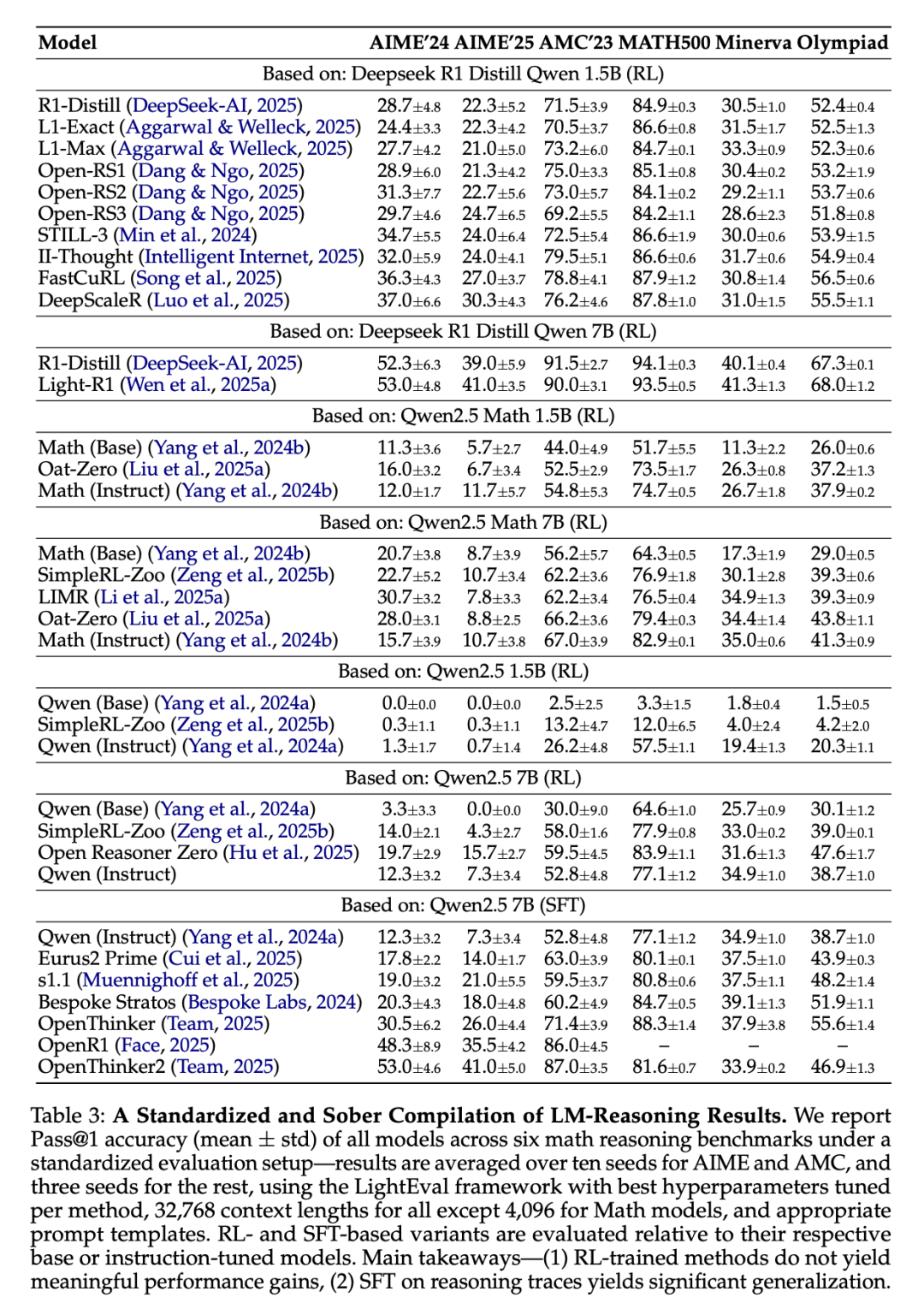
研究者在标准化评估环境中,对六个数学推理基准测试进行了模型评估,并针对这些模型的 Pass@1 准确率(均值 ± 标准差)进行了报告。在 AIME 和 AMC 基准测试中,结果采用了十个随机种子的平均值,而其他基准测试则使用了三个随机种子的平均值。研究者采用了 LightEval 框架,并为每种方法调试了最佳超参数。
需要指出的是,除了数学模型的上下文长度为 4096 之外,其他模型的上下文长度均设定为 32768,并使用了适宜的提示模板。同时,基于强化学习(RL)和监督微调(SFT)的模型变体分别针对各自的基础模型或指令调优模型进行了评估。
主要结论如下:
通过强化学习训练的方法未能显著提升性能。
在推理路径上,SFT 展现了显著的泛化能力。
发现的现象是否可复现?详细分析
研究者进一步调查了最近注意到的两种现象,以验证它们是否在实验中得以复现:
响应长度与性能之间的关系。
以推理为重点的训练后,响应的多样性是否有所下降。
1、错误响应是否更长?
较长的响应是否意味着错误答案的可能性更高?他们比较了在六个数据集(AIME24、AIME25、AMC23、MATH500、Minerva 和 OlympiadBench)中正确和错误答案的响应长度分布,并在每个模型的随机种子上进行了平均。
图 11 展示了按响应长度分组的每个种子的平均响应数量直方图。
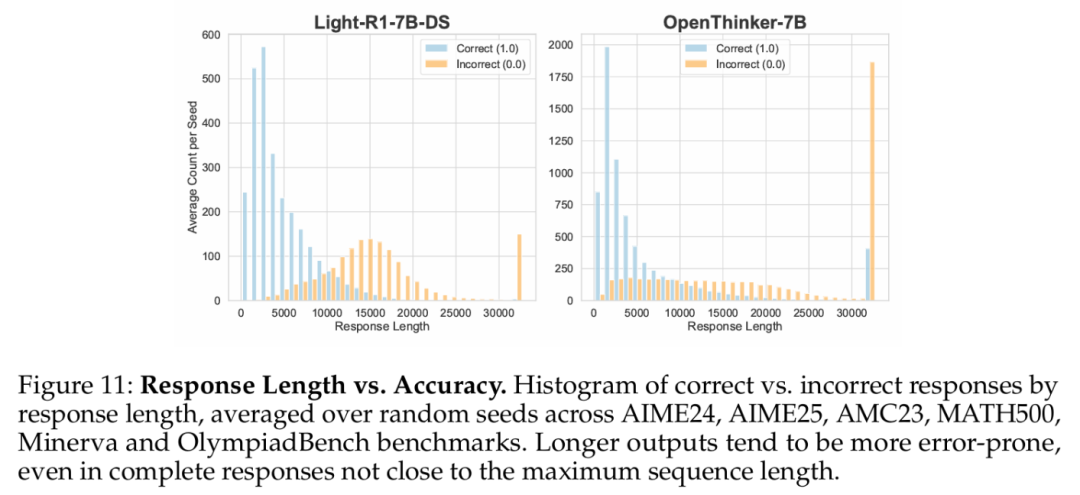
数据显示了一个明显趋势:较短的响应更可能是正确的,而较长的响应则逐渐表现出更高的错误率。这一模式在所有种子中都保持一致,特别是在超过 10000 个 token 的响应中表现得最为显著。研究者就此提出两个关键问题:
Q1:这一模式是否同时适用于基于 RL 和 SFT 训练的模型?
分析结果表明,这一趋势在 RL 和 SFT 训练的模型中均存在。具体而言:
RL 训练模型(左侧显示)中这一效应更为显著
SFT 训练模型(右侧显示)中这一效应相对较弱
Qwen 2.5 Math 基础模型也表现出轻微的长度相关性,但这种相关性在 R1 - distill 及后续的 RL 训练模型中更为突出
Q2. 这种现象是否主要由截断或不完整的响应导致?
尽管接近 32000 token 限制的响应几乎总是错误的(由上下文长度限制所致),但即便是较短的完整响应,这一趋势依然存在——较长的响应与较高的错误概率相关。
2、在推理训练中是否存在多样性坍缩?
为了验证这些主张,研究者比较了 RL 训练模型在所有数据集中的 Pass@k 性能(对于 k∈1, 5, 10)与其相应的基础模型(如 DeepSeek - R1 - Distill - Qwen - 1.5B)。表 4 呈现了各方法的 Pass@k 相对于基础模型的变化情况。
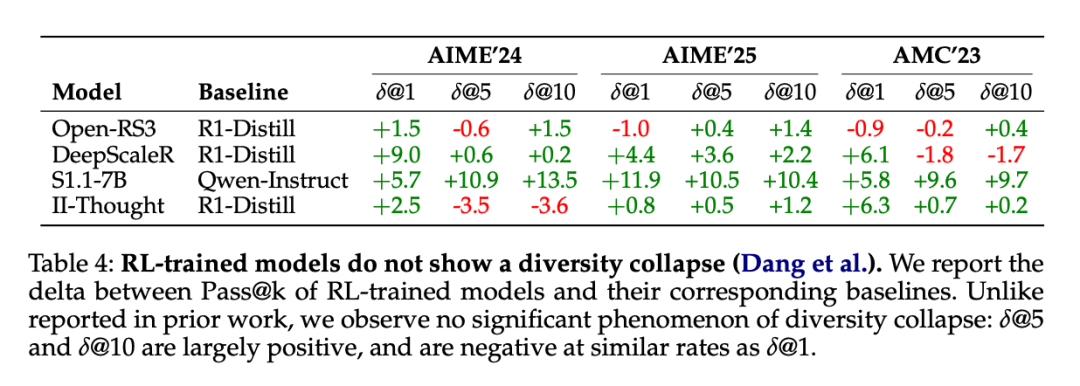
结果显示,并未观察到一致的多样性坍缩现象。Pass@1 的提升通常伴随着 Pass@k 的整体改善,尽管不同指标的提升幅度存在差异。在 Pass@k 性能下降的情况下,这种下降往往与 Pass@1 的偶发性下降同时出现,而非独立发生,这一发现并不支持多样性坍缩的假设。
编辑:于腾凯
校对:林亦霖
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









