








人类社会正在加速数字化。一个显而易见的事实是,人们生活、工作的方方面面都离不开各种各样的软件。不久以前,人们还不知道什么是软件;从今往后,软件正在吞噬整个世界[https://a16z.com/2016/08/20/why-software-is-eating-the-world/]。当我们仔细考察当今大多数软件的结构时,令人惊讶的是绝大多数软件都依赖开放源代码(简称“开放源码”,Open Source Code)。开放源码并不是人们通常想的那样,由类似微软、甲骨文等这样的专业软件公司开发和维护,并像其他商品那样销售。它们完全是由一些软件开发者和专业人士组织起来的社群来负责开发和维护,而且完全免费给用户使用。除此之外,开放源码完全是公开的,用户可以自由的更改和完善代码,并无限的拷贝和再发行。
鉴于开放源码的诸多好处[Why Open Source Software / Free Software (OSS/FS, FLOSS, or FOSS)? Look at the Numbers! ],越来越多的人和组织都在使用这些开放源码来构建各种软件,同样越来越多的公司也开始投入到开放源码的项目中来。在数字世界,“用的人多了,也就成了基础设施”。就像公路、铁路和桥梁等基础设施在物理世界所起的功能类似,开放源码构建了数字世界的基础设施(Digital Infrastructure)。
在数字世界,开放源码以非常独特的方式、低廉的成本创造出来一种全新的基础设施范式。开源也从一项运动逐渐演变为开源经济学(Open Source Ecnomics),它为数字基础设施建设的投融资提供了一种变革的方案。大数据、人工智能、云计算和区块链技术更成为加速器,使得这项变革会更持续、更持久的为人类社会的数字化和数字经济增长提供强劲的动力。
本文尝试将软件(software)作为一种特殊的商品,来建立一个针对软件的经济学分析框架,并运用这个框架来分析开源软件的经济学特性。
一、软件的经济学分析简化模型
以经济学的视角,人们越来越倾向于将处理数据(Data Processing)的软件(Software)与数据(Data )分开来考察。这两者完全是不同属性、具有不同效用的商品。由此,可以基于经济学研究目的,来定义软件[The Economic Properties of Software,Sebastian von Engelhardt, 2008]和数据的概念。在数字经济中,软件和数据的关系示意图[基于DIKW体系以及数字经济价值链关系构建]如下。
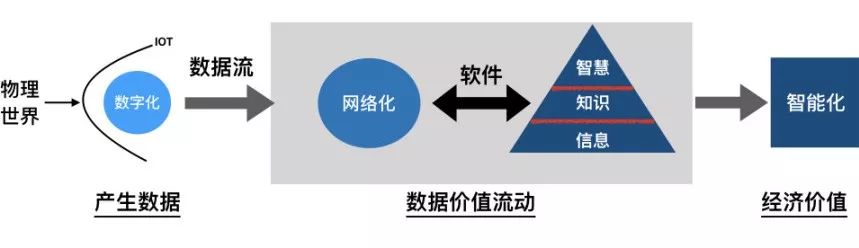
软件是为了处理数据的目的,而按照特定顺序组织/重组的指令和命令的集合。
数据是指所有能作为输入并被软件处理的符号的介质的总称;是作为输入,能够被软件进行处理,具有一定意义的数字、字母、符号和模拟量等的通称。
由于人们对数据安全和数据隐私的关切日益增长,数据权利和权益已经被独立的进行规范[https://gdpr-info.eu]。将数据与处理数据的软件进行分离,在技术层面上,也能很好的界定责任边界。
将数据独立于软件之外的另一个好处是可以建立比较好的微观数字经济学分析框架。因为数据和软件是构建数字世界的原子级要素,因此,微观数字经济学的研究首先要从数据和软件开始。
一个软件 ,待处理的数据
,待处理的数据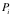 作为其输入,数据的价值记为
作为其输入,数据的价值记为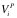 。经过软件处理后,输出数据
。经过软件处理后,输出数据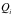 ,其价值记为
,其价值记为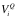 。在第i级处理后的输出数据可以作为更高阶(第j级)的输入,经过另外的软件
。在第i级处理后的输出数据可以作为更高阶(第j级)的输入,经过另外的软件 的处理,输出数据
的处理,输出数据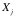 …这样的过程可以一直循环下去(见下图)。
…这样的过程可以一直循环下去(见下图)。
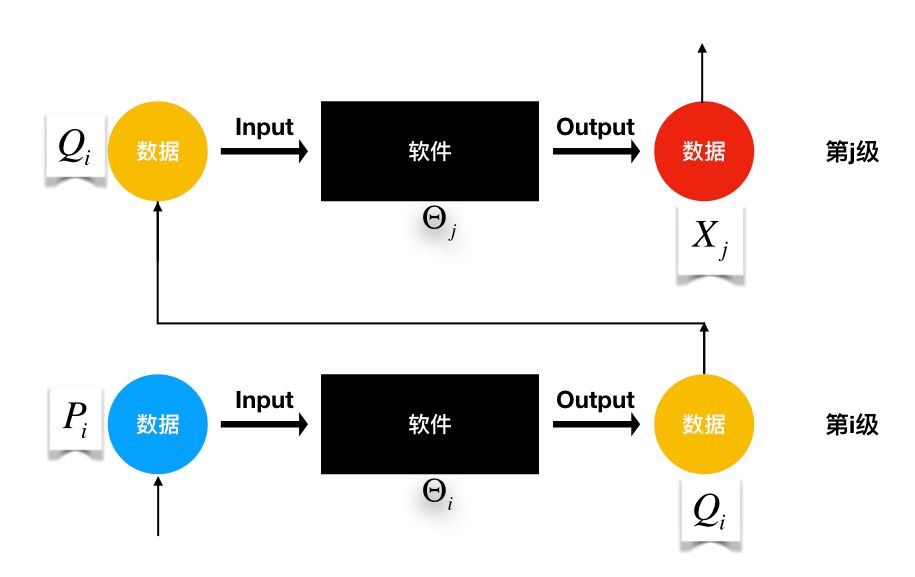
对于软件而言,首先它可以被重复使用,每次输入数据也可以是不同的,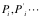 。即便是相同类型的数据,本身也存在敏感性、重要性等个性化差异。通常情况下,软件本身也会有对不同数据采用相适配的处理方法,这就会导致不同的输出数据
。即便是相同类型的数据,本身也存在敏感性、重要性等个性化差异。通常情况下,软件本身也会有对不同数据采用相适配的处理方法,这就会导致不同的输出数据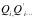 。为了分析简便,我们暂时不考虑这些因素,而认为对于软件本身而言,数据是无差别的。由此,我们可以认为软件的价值就是处理无差别数据的价值增值。
。为了分析简便,我们暂时不考虑这些因素,而认为对于软件本身而言,数据是无差别的。由此,我们可以认为软件的价值就是处理无差别数据的价值增值。
数据的价值我们可以表示为数据对其用户(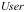 )的效用函数,由此
)的效用函数,由此
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









