








思维导图:

2.3.1 在本节中,我们将深入探讨有限自动机(Finite Automata, FA)的概念,这是理解词法分析和更广泛的计算机科学领域中的基础概念。有限自动机是对能够识别模式的机器或软件逻辑的一种理论模型,尤其关注于如何从正规式转化为能够识别特定语言的机器。
有限自动机简介
有限自动机是一种能够从给定输入串中识别出模式(或者说“语言”)的模型。它由一组状态、一个输入符号集合、一个转换函数、一个起始状态以及一个或多个接受状态组成。有限自动机分为两种类型:确定性有限自动机(DFA)和非确定性有限自动机(NFA)。
确定性有限自动机(DFA)
DFA的特点是在任何给定的状态,对于输入符号集合中的每一个符号,都有一个明确的、唯一的后继状态。这意味着,给定一个输入串和一个DFA,存在一个确定的路径通过状态,这个路径要么导致接受状态,表明输入串被识别,要么导致非接受状态,表明输入串不被识别。
非确定性有限自动机(NFA)
与DFA不同,NFA在某些状态下对某个输入符号可能有多个可能的后继状态,或者甚至对某个输入符号没有后继状态。NFA的一个关键特性是它允许所谓的ε转换,即不消耗输入符号就能从一个状态转移到另一个状态。NFA提供了一种更为灵活的方式来描述语言,尤其是在将正规表达式转换为自动机时。
从正规式到有限自动机
转换正规式到FA是词法分析过程中的关键步骤。正规式提供了一种声明式的方法来描述语言,而FA提供了一种机械式的方法来识别语言。虽然从理论上讲,NFA和DFA都能识别正规语言,但从实际应用的角度,通常首先构造NFA,因为它们更直接对应于正规式。然后,如果需要,可以将NFA转换为等价的DFA,因为DFA在实现时通常更高效。
实例分析
考虑正规式(a|b)*ab,它描述了所有以"ab"结尾的由"a"和"b"组成的字符串。为了识别这种模式,我们可以构造一个NFA,其接受状态表示模式匹配的成功。这个NFA将具有一个起始状态,当读入"a"或"b"时保持在初始状态或转移到新状态,直到序列"ab"的出现明确地引导自动机到达接受状态。
构建和理解FA的挑战
虽然FA的概念在理论上是直截了当的,但在实践中,构建一个有效的FA以识别复杂的模式可能会非常具有挑战性。这需要对要识别的语言有深入的理解,以及对FA运作原理的清晰认识。此外,将NFA转换为DFA,以及优化DFA以减少状态数量,都是需要技巧和细致工作的过程。

2.3.2 在本节博客中,我们将详细探讨确定的有限自动机(Deterministic Finite Automata, DFA)的概念、工作原理及其在词法分析中的应用。DFA是编译原理中词法分析阶段的基础,用于识别特定模式的字符串集合,例如编程语言中的保留字、变量名等。
定义与特性
DFA是一种特殊的有限自动机,其中每个状态对于给定的输入符号都最多只有一个可能的转换。这意味着,给定任何输入字符串,DFA都有一个确定的路径通过状态转换。DFA的主要特性包括:
- 无ε转换:DFA中不存在ε转换,即所有状态转换都必须消耗输入字符串中的字符。
- 唯一性转换:对于任何状态s和输入符号a,最多只有一条标记为a的边离开s,这使得DFA的行为完全确定。
工作原理
DFA的工作原理基于一组预定义的转换规则,根据输入字符串中的字符顺序进行状态转换。如果DFA在消耗完所有输入字符后达到接受状态,则认为该字符串被DFA接受;否则,该字符串被拒绝。
模拟DFA的算法
模拟DFA的过程可以通过以下步骤实现:
- 初始化:设置当前状态为DFA的开始状态。
- 读取输入:逐个字符读取输入字符串。
- 状态转换:根据当前状态和读取的字符,使用转换函数找到下一个状态。
- 接受检测:如果输入字符串全部读完且当前状态是接受状态,则接受该字符串;否则,拒绝。
实例分析
考虑正规式(a|b)*ab,我们可以构造一个DFA来识别所有以"ab"结尾的字符串。该DFA的转换图简化了从相应的NFA转换来的复杂性,提供了一个高效的识别过程。例如,给定输入串"abab",DFA将按照定义的转换规则,从开始状态经过一系列状态转换,最终到达接受状态,并输出“yes”表示接受该字符串。
DFA与词法分析
在编译器的词法分析阶段,DFA用于识别源代码中的各种词法单元,如标识符、关键字、运算符等。通过为每种词法单元定义相应的DFA,编译器能够将源代码文本转换为一系列标记,为后续的语法分析阶段做好准备。
结论
DFA是理解和实现词法分析的关键概念之一。它们提供了一种精确、高效的方式来识别字符串模式,是构建编译器和其他文本处理工具的基础。通过学习DFA的原理和应用,我们可以更好地理解编译过程中的词法分析阶段,以及如何设计和实现用于模式识别的自动机。
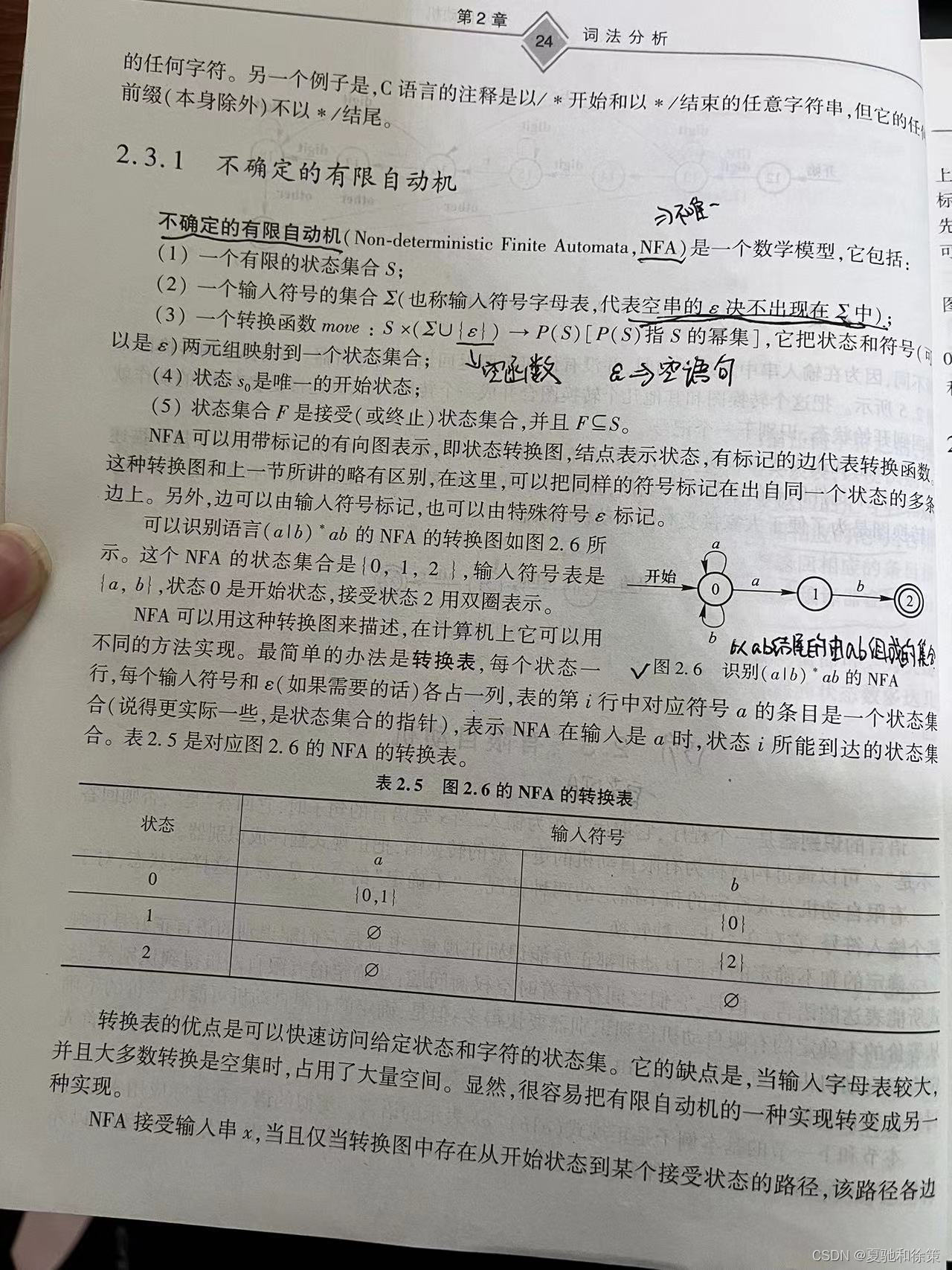
2.3.3 在本节中,我们将探讨从非确定性有限自动机(NFA)到确定性有限自动机(DFA)的转换过程,这是理解词法分析中有限自动机应用的关键一步。这个转换过程,通常称为子集构造法,是将正规式转换为词法分析器实现的基础。
NFA与DFA的区别
在深入了解转换过程之前,重要的是要明确NFA和DFA之间的区别。NFA在给定状态和输入符号下,可能存在多个转换或ε转换(无输入转换)。这种非确定性虽然提供了表示能力上的灵活性,但直接用计算机程序模拟NFA却是困难的。相比之下,DFA对于每个状态和输入符号,都有唯一确定的下一个状态,不存在ε转换,这使得DFA更易于通过计算机程序实现。
子集构造法的基本思想
子集构造法的核心思想是将NFA的状态集合转换为DFA的状态。具体来说,DFA的每个状态实际上代表了NFA可能处于的状态集合。通过这种方式,DFA能够“并行”地跟踪NFA在面对同一输入串时所有可能的状态转换路径。
子集构造法的步骤
- 初始化:以NFA的起始状态的ε闭包(即从起始状态出发,仅通过ε转换能到达的所有状态的集合)作为DFA的起始状态。
- 状态转换:对于DFA的每个状态(即NFA的一个状态集合),以及对于所有输入符号,计算状态集合在该输入符号下的转移。这涉及到计算ε闭包,以包括所有可能通过ε转换进入的状态。
- 接受状态的确定:如果NFA的接受状态出现在某个DFA状态所对应的NFA状态集合中,则该DFA状态被标记为接受状态。
示例分析
让我们通过一个具体的例子来说明这个过程:考虑一个简单的NFA,它接受正规式(a|b)*ab的语言。根据子集构造法,我们可以构造一个等价的DFA,其状态表示NFA在读入字符串后可能处于的所有状态的集合。
- 起始状态:DFA的起始状态对应NFA起始状态的ε闭包。
- 状态转换:对于每个输入符号,计算NFA的状态集合在该符号下可能达到的所有状态,再加上这些状态的ε闭包,形成新的DFA状态。
- 完成转换:重复上述过程,直到不再产生新的DFA状态。
实现挑战
尽管理论上直接,子集构造法在实践中可能遇到的挑战包括状态爆炸问题,即DFA可能有极大数量的状态。幸运的是,许多实际情况下,并不需要构造出所有理论上可能的状态,因为许多状态可能永远不会被实际访问。
结论
从NFA到DFA的转换是理解和实现词法分析器的关键步骤。通过子集构造法,我们能够将正规式转换成易于计算机模拟的DFA,为文本模式匹配提供了强大的工具。尽管转换过程可能面临一定的实现挑战,但通过优化和简化,能够有效地实现高效且准确的词法分析器。

2.3.4 在这一节中,我们将探讨如何将确定性有限自动机(DFA)化简为状态数最少的DFA,同时保持其识别同一语言的能力。这个过程不仅有助于提高词法分析的效率,还有助于理解正规语言的本质。通过化简DFA,我们可以得到一个最小的DFA,这个最小的DFA在识别特定语言方面是最优的,即无法通过减少状态数来达到同样的识别能力。
DFA的化简过程
DFA的化简基于一种称为状态等价的概念。如果两个状态对于所有输入字符串的反应(即接受或拒绝)都相同,则这两个状态是等价的。化简的目标是识别这些等价的状态,并将它们合并,从而减少DFA的总状态数。
步骤概述
-
初始划分:将DFA的状态分为两个子集,一个是接受状态集,另一个是非接受状态集。这是基于这样一个事实:接受状态和非接受状态至少在空字符串ε上的反应不同,因此它们不能是等价的。
-
细化划分:对每个子集,基于状态在输入符号上的转移能否达到同一子集中的状态来进一步细分。如果一个子集中的某些状态在某个输入符号下的转移结果落在不同的子集中,那么这些状态不是等价的,应该被分到不同的子集中。
-
重复细化:重复上述细化过程,直到不能进一步细分为止,即每个子集内的所有状态都对于所有输入符号的反应完全相同。
-
构建最小DFA:每个最终的子集代表最小DFA中的一个状态。原DFA中的转移在最小DFA中通过子集之间的转移来表示。
实现注意事项
-
死状态处理:如果DFA的转换函数不是全函数,即某些状态对某些输入没有定义的转移,可以引入一个“死状态”,并将未定义的转移指向这个死状态,从而保证转换函数是全函数。
-
状态等价的证明:本质上,两个状态是等价的,意味着不存在任何字符串能够区分这两个状态。证明最终划分中的状态不能被任何字符串区分是通过不断的细化过程实现的,这保证了化简后的DFA与原DFA等价。
示例说明
考虑一个识别语言 (a|b)*ab 的DFA。通过应用上述步骤,我们可以发现某些状态只在遇到特定序列时才能达到接受状态,而其他序列则不可能。通过合并这些功能相似的状态,我们可以得到一个状态数更少的DFA,它仍然能准确识别相同的语言。
结论
DFA的化简是理解正规语言和自动机理论的一个重要方面。通过最小化DFA,我们不仅能够提高词法分析的效率,还能更深入地理解语言的结构。最小化DFA的过程展示了如何通过系统化的方法从复杂的自动机中提取出本质的模式识别能力,这对于编译器设计以及其他应用自动机理论的领域都是非常重要的。







2.3 有限自动机的重点、难点和易错点总结
这一大节深入探讨了有限自动机(FA),包括其两种形式:非确定性有限自动机(NFA)和确定性有限自动机(DFA),以及如何从NFA到DFA的转换,最后讨论了DFA的化简方法。下面是这一节的重点、难点和易错点的总结。
重点
-
NFA与DFA的基本概念:理解NFA和DFA的定义及其工作原理是这一节的基础。NFA允许多条出边对应同一个输入符号,包括ε转换;而DFA对于每个状态和输入符号,有且只有一个明确的转移状态。
-
NFA到DFA的转换(子集构造法):将NFA转换为等价的DFA是理解自动机理论中一个重要的过程。这一过程涉及到创建状态子集来代表NFA中可能的状态配置。
-
DFA的化简:化简DFA到最小状态数的过程,以保持其识别相同语言的能力,同时提高效率。
难点
-
子集构造法的理解和应用:理解如何从NFA的状态集合出发,通过ε闭包和状态转移来构造DFA的状态,这一过程在概念上可能比较抽象。
-
DFA化简过程的实现:理解如何通过分割状态集合来化简DFA,尤其是如何确定哪些状态可以合并,哪些状态必须保持分开,这需要对状态等价性有深刻理解。
易错点
-
忽视ε转换:在NFA到DFA的转换过程中,易错地忽略ε转换的影响,导致未能正确计算状态的ε闭包。
-
混淆NFA和DFA的状态:在进行NFA到DFA的转换时,可能会混淆两种自动机的状态,尤其是在将NFA的状态集合转换为DFA的单个状态时。
-
化简过程中的状态等价性判断错误:在DFA化简过程中,错误地判断了状态的等价性,导致合并了不应合并的状态或未能合并应合并的状态。
结论
有限自动机是理解词法分析和正规语言理论的核心,涉及到NFA和DFA的定义、操作和转换。掌握NFA到DFA的转换和DFA的化简技术是编译原理和计算机科学中的基本技能。虽然这些概念在开始时可能看起来既抽象又复杂,但通过实际的练习和例子,可以逐渐理解和应用这些重要的理论知识。

















 7712
7712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











