






YOLO网络结构
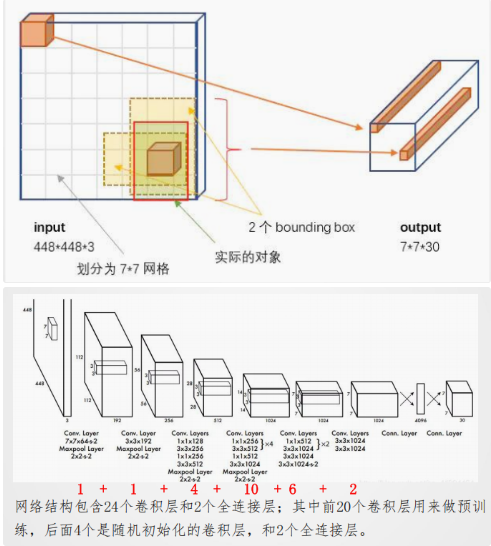
YOLO模型处理
-
YOLO网络输入:图片尺寸448*448*3
-
YOLO模型处理:网格划分
-
YOLO模型输出:7*7*30cell
- 每个cell对应两个包围框,对应检测不同的目标
- 物体中心位置x、y(需要归一化)
- 框的高度h、宽度w(需要归一化)
- 预测置信度
c
=
P
r
(
O
b
j
)
×
I
o
U
p
r
e
d
t
r
u
t
h
c=\mathrm{Pr}(\mathrm{Obj})\times\mathrm{IoU}^{truth}_{pred}
c=Pr(Obj)×IoUpredtruth
- c c c :代表边界框的置信度(Confidence) ,它反映了该边界框包含目标的可能性大小,以及边界框预测的准确程度。取值范围通常在0 - 1之间 。
- P r ( O b j ) \mathrm{Pr}(\mathrm{Obj}) Pr(Obj) :表示该网格内存在目标的概率。如果网格内有目标, P r ( O b j ) = 1 \mathrm{Pr}(\mathrm{Obj}) = 1 Pr(Obj)=1 ;若网格内没有目标,则 P r ( O b j ) = 0 \mathrm{Pr}(\mathrm{Obj}) = 0 Pr(Obj)=0 。
-
I
o
U
p
r
e
d
t
r
u
t
h
\mathrm{IoU}^{truth}_{pred}
IoUpredtruth :是预测边界框(pred)与真实边界框(truth)之间的交并比(Intersection over Union,IoU ) 。IoU用于衡量两个边界框的重叠程度,通过计算两个边界框交集面积与并集面积的比值得到,取值范围也是0 - 1 ,值越大说明预测框和真实框越接近。
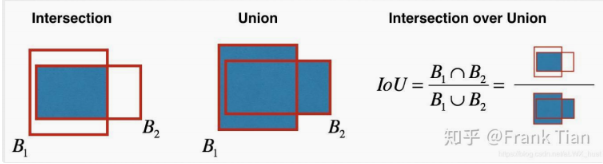
- 每个cell对应两个包围框,对应检测不同的目标
-
YOLO模型损失函数(V1)

YOLO关键技术细节
1. 非极大值抑制(NMS)
- 作用:剔除重复边界框,保留最优预测。
- 步骤:
- 按置信度降序排序所有边界框。
- 选择置信度最高的框作为输出,计算其与剩余框的 $ IoU $,剔除 $ IoU $ 超过阈值(如0.4)的框。
- 重复直至所有框处理完毕。
2. 训练集训练
- YOLO先使用ImageNet数据集对前20层卷积网络进行预训练,然后使用完整的网络,在PASCAL VOC数据集上进行对象识别和定位的训练和预测。
- 训练中采用了dropout和数据增强来防止过拟合。
- YOLO的最后一层采用线性激活函数,其它层都是采用Leaky ReLU激活函数:
{ x , if x > 0 0.1 x , otherwise \begin{cases} x, & \text{if } x > 0 \\ 0.1x, & \text{otherwise} \end{cases} {x,0.1x,if x>0otherwise
语义分割
一、语义分割基础
- 目标:对图像中每个像素进行分类,标注其所属类别(如天空、树木、猫等),实现像素级的密集预测。
- 与其他任务的区别
- 目标检测:用边界框定位目标(输出矩形框)。
- 实例分割:区分同一类别的不同实例(如多个猫的个体)。
二、FCN(全卷积网络)
1. 网络结构
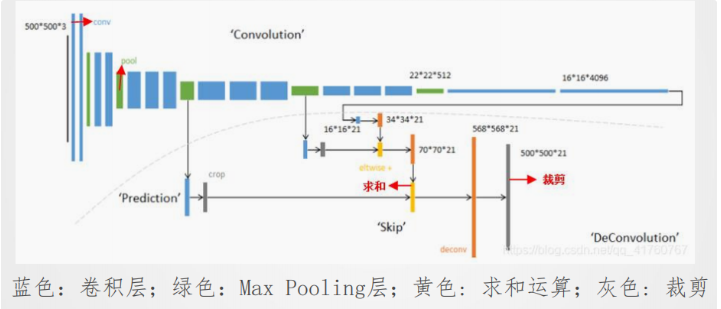
- 卷积部分:
- 基于经典CNN(如VGG16),将全连接层替换为卷积层,提取多尺度特征图,形成热点图。
- 输出特征图尺寸随卷积和池化逐渐缩小(如输入500×500,经多次池化后变为16×16)。
- 反卷积部分:
- 将小尺寸的热点图上采样得到原尺寸的语义分割图像。
- 跳级结构:融合浅层高分辨率特征与深层高语义特征,提升分割精度。
三、评价指标与标注工具
1. 评价指标
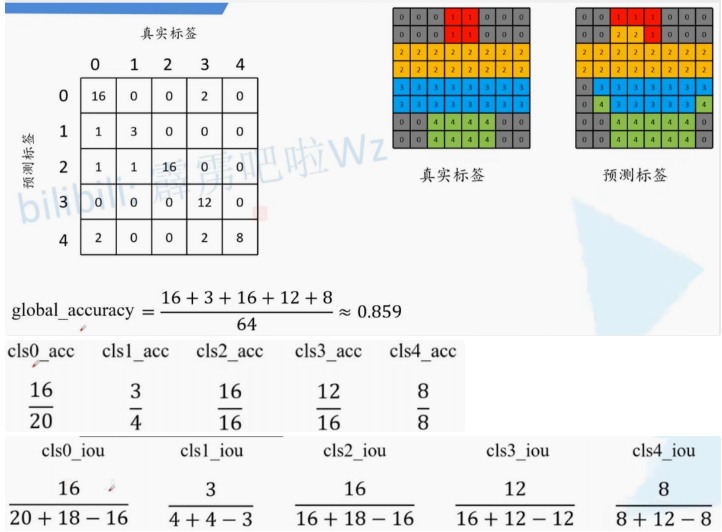
符号说明:
- n i j n_{ij} nij:类别 i i i被预测成类别 j j j的像素个数
- n c l s n_{cls} ncls:目标类别个数(包含背景)
- t i = ∑ j n i j t_{i} = \sum_{j}n_{ij} ti=∑jnij:目标类别 i i i的总像素个数(真实标签)
- 像素精度(Pixel Accuracy, PA): ∑ i n i i ∑ i t i \frac{\sum_{i}n_{ii}}{\sum_{i}t_{i}} ∑iti∑inii 正确分类的像素数占总像素数的比例。
- 平均精度(Mean Accuracy, mAcc): 1 n c l s ⋅ ∑ i n i i t i \frac{1}{n_{cls}} \cdot \sum_{i}\frac{n_{ii}}{t_{i}} ncls1⋅∑itinii ,各类别精度的平均值。
- 平均交并比(Mean IoU, mIoU):
1
n
c
l
s
⋅
∑
i
n
i
i
t
i
+
∑
j
n
j
i
−
n
i
i
\frac{1}{n_{cls}} \cdot \sum_{i}\frac{n_{ii}}{t_{i} + \sum_{j}n_{ji}-n_{ii}}
ncls1⋅∑iti+∑jnji−niinii ,各类别预测与真实区域交集与并集之比的平均值,常用作核心指标。
2. 标注工具
- Labelme:开源标注工具,支持多边形、矩形等标注方式,生成JSON格式标签。
- EISeg:基于飞桨的智能标注工具,支持自动分割与交互式标注,提升效率。
循环神经网络
一、序列模型基础
1. 核心概念
- 序列模型:处理具有时序依赖的数据(如时间序列、文本),输入输出可为不定长序列。
- 时间序列预测:需结合历史输入预测当前输出。
- 自回归模型:
- 假设当前时刻数据依赖过去有限时段的数据: x t ∼ P ( x t ∣ x t − 1 , … , x t − τ ) x_t \sim P(x_t | x_{t-1}, \dots, x_{t-\tau}) xt∼P(xt∣xt−1,…,xt−τ)。
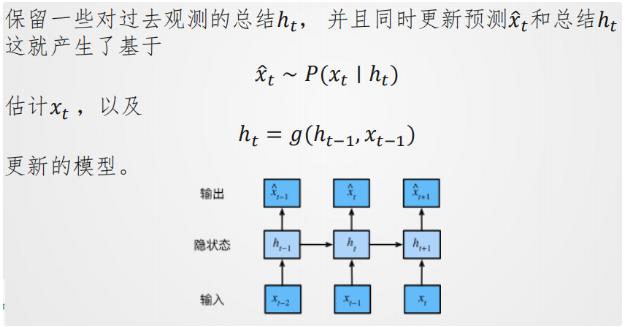
- 引入状态向量
h
t
h_t
ht总结历史信息,通过
h
t
=
g
(
h
t
−
1
,
x
t
−
1
)
h_t = g(h_{t-1}, x_{t-1})
ht=g(ht−1,xt−1)更新状态,实现对序列的建模。
二、数据预处理
1. 特征编码
- 数值特征:直接使用原始数值(如年龄)。
- 类别特征:
- 独热编码(One-Hot Encoding):将类别映射为高维二进制向量(如国籍:197个国家→197维向量)。
- 问题:维数过高,无法捕捉类别间语义关联(如“中国”和“美国”均为国家,但独热向量无相关性)。
2. 文本处理
- 步骤:
- 加载文本:读取数据集
- 分词(Tokenization):将文本切分为单词或字符序列(如“to be or not”→[‘to’, ‘be’, ‘or’, ‘not’])。
- 构建词典:为每个词元分配唯一索引(如‘the’→1,‘time’→19)。
- 转换为索引序列:将文本转换为数字序列,便于模型处理。
三、词嵌入(Word Embedding)
- 将独热向量映射为低维稠密向量(如从 v v v维→ d d d维, d ≪ v d \ll v d≪v),通过训练学习映射矩阵 d × v d \times v d×v。
- 效果:相近语义的词在向量空间中距离更近(如“good”“fun”“fantastic”聚簇,“boring”“poor”聚簇)。
四、循环神经网络(RNN)
模型结构
- 核心组件:
- 输入层
- 隐藏层
- 输出层
- 特点:参数共享,适合处理不定长序列。
关键问题:长距离依赖
- 遗忘问题:RNN难以捕捉长序列中相隔较远的依赖关系(如“中国”与“语言”在长句中关联时, h 100 h_{100} h100可能遗忘 x 1 x_1 x1的信息)。
- 原因:误差反传时梯度随时间步呈指数衰减(梯度消失),导致早期时间步的参数更新极慢。
五、RNN误差反传

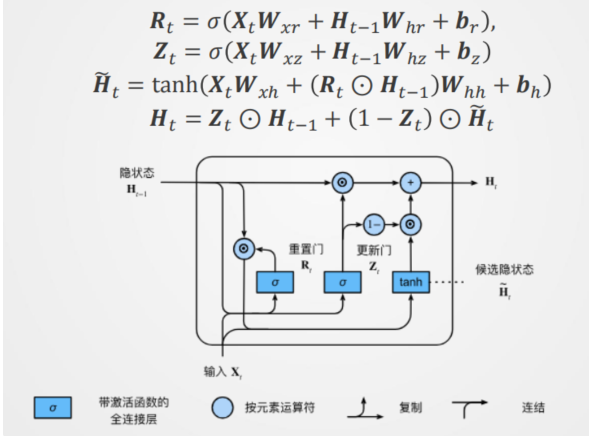
一、门控循环单元(GRU)
1. 基本思想
- 核心:通过“门控机制”控制信息的流动,区分不同观察的重要性。
- 关键要素:
- 更新门(Zₜ):【关注机制】决定保留多少过去的隐藏状态信息。
- 重置门(Rₜ):【遗忘机制】控制前一隐藏状态对当前候选隐藏状态的影响程度。
2. 模型结构与公式
-
重置门与更新门计算
(σ为Sigmoid函数,输出介于0和1之间,表示门控开启程度)
-
候选隐藏状态计算
(Rₜ与Hₜ₋₁逐元素相乘,控制历史信息的遗忘程度)
-
隐藏状态更新
(Zₜ决定前一状态Hₜ₋₁的保留比例,1-Zₜ决定候选状态H̃ₜ的更新比例)
二、长短期记忆网络(LSTM)
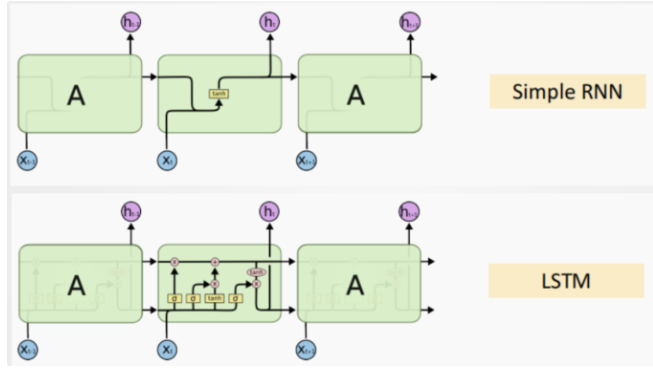
1. 核心结构:记忆状态(传送带)
- 引入记忆状态Cₜ,用于存储长期信息,通过多个门控机制控制其更新和输出。
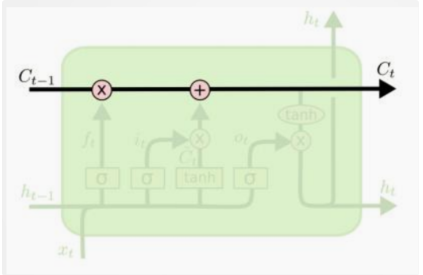
2. 门控机制
-
遗忘门(fₜ)
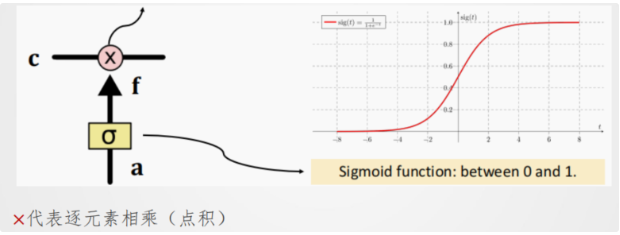
(决定从记忆状态Cₜ₋₁中遗忘哪些信息,输出0-1之间的值,0表示完全遗忘,1表示完全保留)。
-
输入门(iₜ)与候选记忆状态(C̃ₜ)
(iₜ控制候选状态C̃ₜ的更新比例,C̃ₜ通过tanh生成新的候选值)。
-
记忆状态更新
(结合遗忘和输入门,更新记忆状态)。
-
输出门(oₜ)
(oₜ控制记忆状态Cₜ的输出比例,生成最终隐藏状态hₜ)。
3. 模型特点
- 参数量:是传统RNN的4倍,因包含4个门控的权重矩阵。
- 输入输出:与RNN相同,输入为词嵌入序列,输出为隐藏状态或预测结果。
4. 模型实现与训练结果
- 训练结果对比:LSTM与GRU在损失下降趋势上相近,但LSTM因结构更复杂,可能在某些长序列任务中表现更优。

















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









