






在我上一篇博客《oracle性能优化二——操作系统优化》中介绍了如何操作系统优化,本文将介绍如何使用toad监控数据库的优化。
通过合理的分配内存大小,合理的设置表空间体系和内部空间参数。可以提高磁盘空间的利用率、减少数据段碎片、并且在查询和向数据文件写入数据的时候使用较少的IO,较少的IO也会降低cpu的资源消耗。同时对环境参数的合理配置,可以使数据库中数据顺畅的流动,减少锁存器冲突和各种等待,充分的利用系统资源。
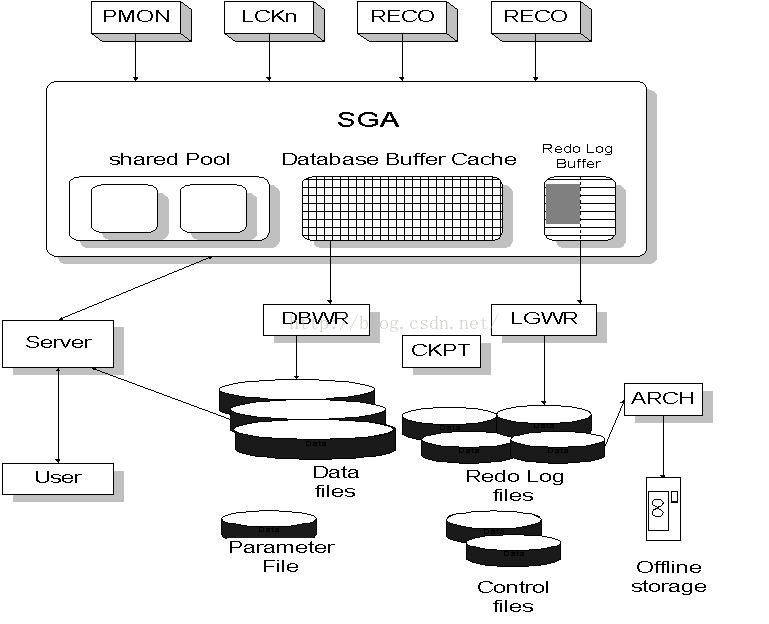
图1
内存结构的优化主要是通过init.ora文件的环境参数来配置,要主要注意下面几个:
db_block_size:数据库中每个数据块的大小,默认是2048字节(2k),一般应该增大到4K、8K,大型数据库也常使用16K和32K,通常SGA也应该增加。
Shared_pool_size:至于shared_pool_size大小是否合适,可以通过对数据库的监控得到,也可以通过一些sql语句实现。我们可以查询v$SGASTAT,查看SGA结构,其中free memory做为一个估计性的指标,如果大于20%可以将shared_pool_size给小些,给其他部分多分配些,如果小于8%,就可以开大些share_pool_size。有一些更精确的sql脚本可以查看其中library_cache,cursor_cache,pl/sql cache大小是否合适,如果数据库规模增长,还需要多少内存,所有这些都可以在附件中找到。
Log_buffer:为了减少LGWR和DBWR冲突,大型数据库的log_buffer一般都是要手工调大些,一般为2M到3M。可以查询V¥SYSSTAT视图中redo log space requests,如果大于0就应该增加log_buffer的值。其他对oracle影响很大的参数有:db_writes、db_file_multiblock_read、sort_direct_writes、sort_area_size讲起来就多了,由于和例子关系不大所以不再叙述。需要注意的是:对oracle9i来说sort_area_size,sort_area_retained_size,hash_area_size,bitmap_merge_area_size等参数都被放弃,由pga_aggregate_target统一动态分配内存区域大小,对于undo(回滚)操作也有些变化:undo_retention表示已提交数据在回滚表空间中保留时间,以秒为单位,缺省900。此选项可使新事务尽可能使用空闲的回滚表空间,这样就减少了查询过程因snapshot too old而失败的几率。undo_tablespace表示系统的回滚表空间。
所有的环境参数,都可以通过系统的监控工具来分析是否适宜。
2.windows下的toad
在windows下可以使用toad 进行监控,toad的监控结果如图2、图3,分别使用了dba 下的databasemonitor和log switch frequence map,toad还有很多工具大家都可以试试,还是很有特色的。
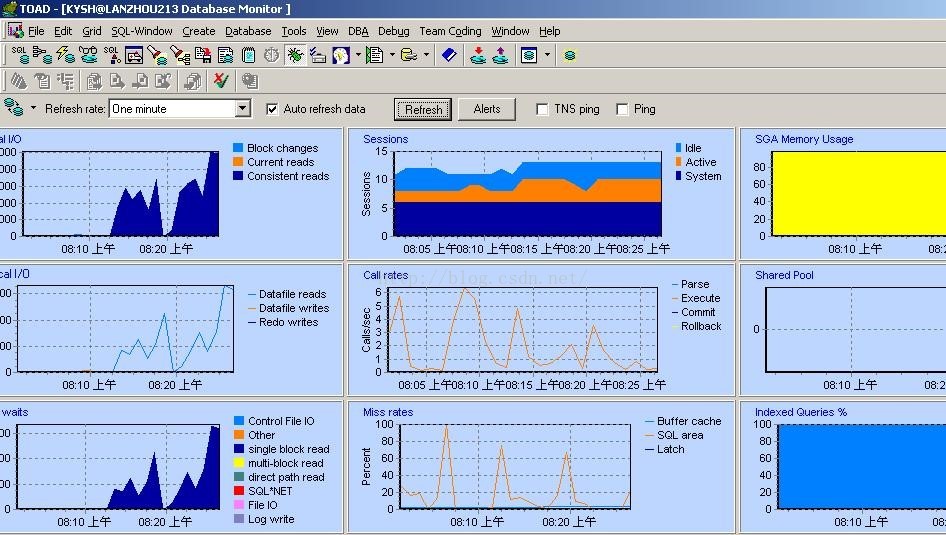
图2
对于logical io:consistent reads表示了逻辑获取,对全表扫描执行一次consistent reads增加1;对通过索引访问表consistent reads的值为索引高度+2*关键字。db_block_change是更新的数据块个数和数据更新的行数之和,表示被修改了的与无效列表连锁的数据块的数目。physical io 是物理读的统计。
Call rate和miss rate、waits也是应该关心的地方,可以看到通常在执行什么工作时系统出现等待。
我们现在一起分析上面的图:在早上8:05至8:25分的监测结果表明Consistent_Get(逻辑读) 的峰值为每秒5000个数据块;phsical read(物理读)的峰值:600个数据块/每秒;主要发生在single block read上,那么应该是通过索引的方式访问表。这里single block read出现大量等待,可能存在没有充分索引的大表、或者使用了选择性低的索引。提醒我们在优化sql语句时要留意。注意,这里的块是oracle数据块,现在数据库块大小是2k,所以每秒传递的数据量为2k/数据块*600数据块/秒=1200k/秒。但是刚才我们在iostat里看到,不是每秒从磁盘传输5M左右的数据吗,为什么每秒向读如SGA的数据是1M呢?这是因为本操作系统的的块大小为8k,对来自oracle的每个读块要求,操作系统取一个8k的块放在系统缓冲区里,然后oracle只从中取2k的块存到SGA里,只使用了操作系统1/4的io读取能力,所以监控结果会出现数据不一致。这正是造成硬盘io瓶颈的原因之一啊,看来必须要调整数据库块的大小,下面有一个章节介绍了如何修改数据库块大小。
再来看另外的部分:最多的call rate 是execute,最多的miss rate是sql area,miss rate中sql area存在峰值说明,部分时间段内sql的命中率较低,需要进一步查看是否是因为不良sql引起的,还是因为sql缓冲区太小。使用toad的health check 可知db_block_buffers的命中率为97%,通过v$sgastat视图可查知shared_pool_size中free mem有只4%左右,看来shared_pool_size太小了,结合上面存在大量页面交换的事实,得出结论:系统需要增加内存或者减少整体SGA,为系统留下更多的缓冲内存,同时还需要增加shared_pool_size的值。由于后面用utlestat脚本监控到sort disk始终为0,为排序分配的内存可以少留些,所以将sort area size从75M降低到了32M,这部分内存就划分给了shared_pool_size。接下来看图3,图3监测的是(redo log file)重做日志文件的使用情况。
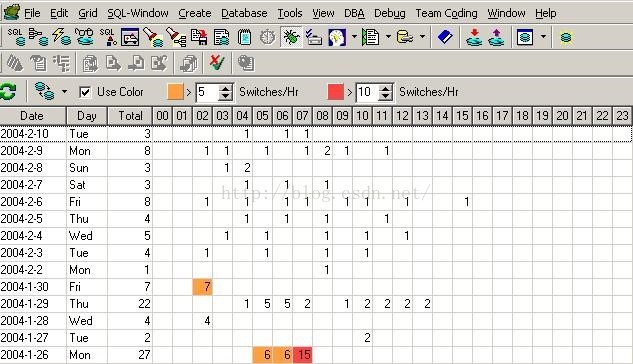
图3
可以看到未优化前redo log 频繁发生,说明需要增加重写日志缓冲区和重写日志,看来LGWR和DBWR的竞争也是硬盘io瓶颈的原因之一。优化的措施是Log buffer增加到2M,redo log file修改为100M,在以后的监测中,即使是事务高峰期也能控制日志文件的交换每小时最多1到2次。一般log buffer开到2M—3M就可以了,如果太大会有负面影响,有可能在redo操作时会丢失数据。
当然也可以使用sql语句分析oracle,许多人也喜欢这样做。感兴趣的朋友可以在附录的文件中找到对自己有用的sql直接使用。还有许多人是自己开发软件来分析数据库的,据说这是最有效的方法。毕竟oracle已经提供了使用方便的许多视图,toad也是如此实现的。
















 460
460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











