






核心概念解析
-
功能权限(Functional Permission)
定义用户可访问的系统功能边界,通常基于RBAC模型实现。通过角色-菜单映射机制,实现用户功能可见性的层级控制,是权限体系的基础层。
-
数据权限(Data Permission)
控制用户在功能边界内可访问的数据粒度,其本质是通过动态数据过滤实现的访问控制。典型实现方式为数据库查询条件注入,例如限制区域经理仅能访问属地数据:
SELECT * FROM orders WHERE region_code = 'HF'; -
数据范围(Data Scope)
用户实际可访问的数据子集,具有多维特征。例如:"华东区域+教育产品线"构成的数据交集,反映业务实体在空间和产品维度的双重约束。
-
控权维度(Control Dimension)
数据权限的具体实施载体,直接映射业务特征。常见的维度包括但不限于:
-
地理维度(区域、门店)
-
商业维度(渠道商、经销商层级)
-
产品维度(产品线、SKU分类)
-
流程维度(销售通路、业务单元)
方案一:基于角色-菜单绑定的权限控制
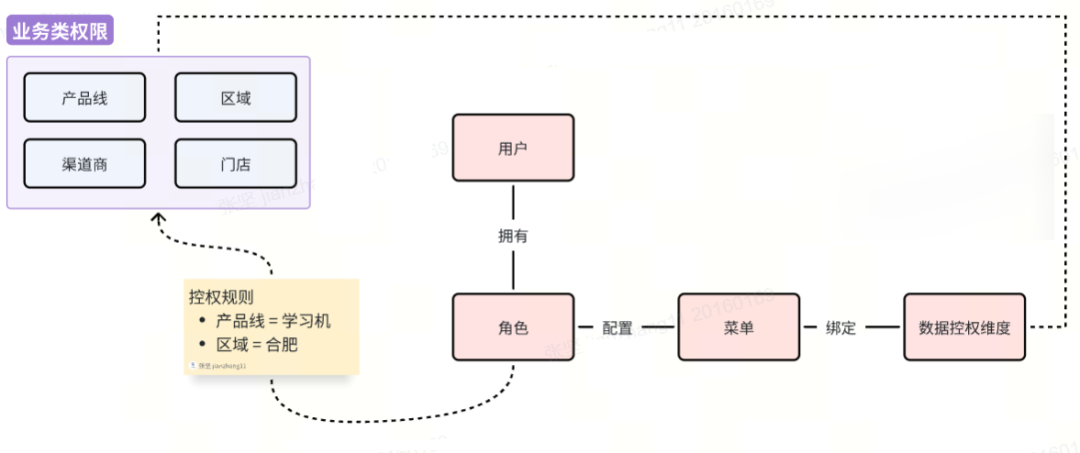
第一种方案采用经典的权限管理方式,通过将菜单与权限维度绑定、角色与菜单实例关联来实现权限控制。这种设计能够实现精确到菜单级别的权限管理,每个菜单都可以灵活配置不同的权限维度,具有较好的通用性。然而其最显著的缺陷在于会引发"角色爆炸"问题。
以区域管理场景为例,虽然业务上只需要"城市经理"这一个角色概念,但在实际系统中却需要为每个区域创建独立角色实例:合肥城市经理、阜阳城市经理等。这种设计导致角色数量与权限维度取值呈正比增长,当系统需要管理300个区域时,就必须维护300个对应的角色实例。
更严重的是,这种架构会给系统运维带来巨大负担。例如当需要为所有城市经理新增一个功能菜单时,管理员不得不对300个角色逐一进行配置更新。这种线性增长的维护成本不仅降低了系统灵活性,也大大增加了出错概率,在大型企业系统中这一问题尤为突出。
方案二:基于用户-角色-范围的权限控制
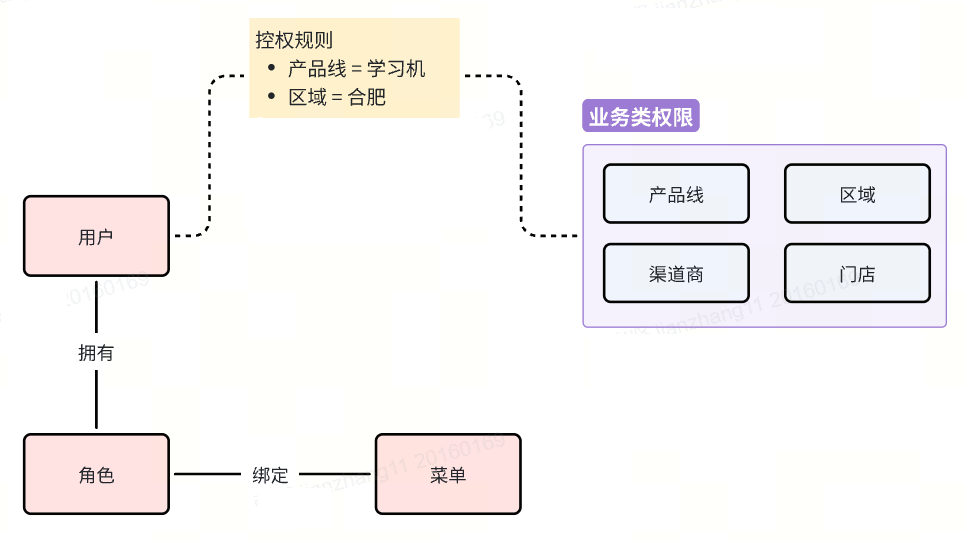
第二种方案采用用户-角色-数据范围绑定的权限管理模式,虽然解决了角色数量膨胀的问题,却带来了新的局限性。该方案的核心思路是让用户直接关联数据权限范围,而非通过角色间接控制。例如,用户张三拥有"销售经理"角色,同时被赋予"华东区域"的数据访问权限。
这种设计虽然减少了角色数量,但存在明显的灵活性缺陷。由于数据权限维度与用户直接绑定,导致所有功能模块必须共享同一套数据过滤规则。在实际业务中,不同模块往往需要采用不同的权限维度:销售模块可能需要按区域管控,而产品模块则需要按品类管控。这种多维度的权限需求在该方案下无法得到满足,造成业务适配性不足的问题。
更具体地说,如果系统规定用户的数据权限维度是"区域",那么即便是需要按"产品线"管控的零售模块,也不得不强制使用区域维度进行过滤。这种一刀切的权限控制方式,严重制约了复杂业务场景下的精细化权限管理需求。
方案三:菜单绑定控权维度,用户绑定数据权限
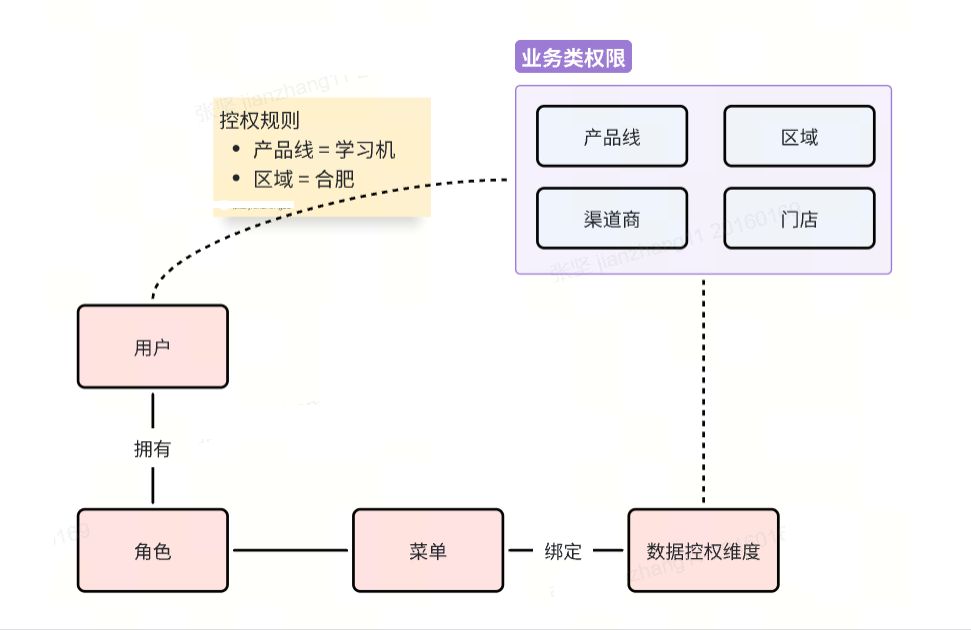
第三种方案结合了前两种方案的优点,采用"菜单绑定控权维度+用户设置权限范围"的混合模式。这种设计虽然解决了角色数量膨胀的问题,却带来了新的挑战——权限范围放大效应。
具体来说,当用户在某个维度(如区域)拥有多个权限值时,这些权限会自动应用到所有相关菜单。例如:
-
业务要求:张三在采购订单中只能查看合肥数据,在销售订单中只能查看阜阳数据
-
实际效果:由于张三被同时授予合肥和阜阳的权限,导致他在两个订单模块中都能看到合肥+阜阳的全部数据
这种设计虽然简化了权限管理,却造成了严重的数据权限越界问题。根本原因在于:
1)权限范围是全局性的,无法按功能模块进行隔离
2)同一维度下的细粒度权限控制缺失
3)业务场景的特殊性无法得到体现
这种方案比较适合权限要求相对宽松的场景,但对需要严格数据隔离的业务系统来说,仍存在明显缺陷。后续需要引入更精细的权限控制机制来解决这个问题。
方案四:菜单绑定授权维度,角色实例绑定数据权限
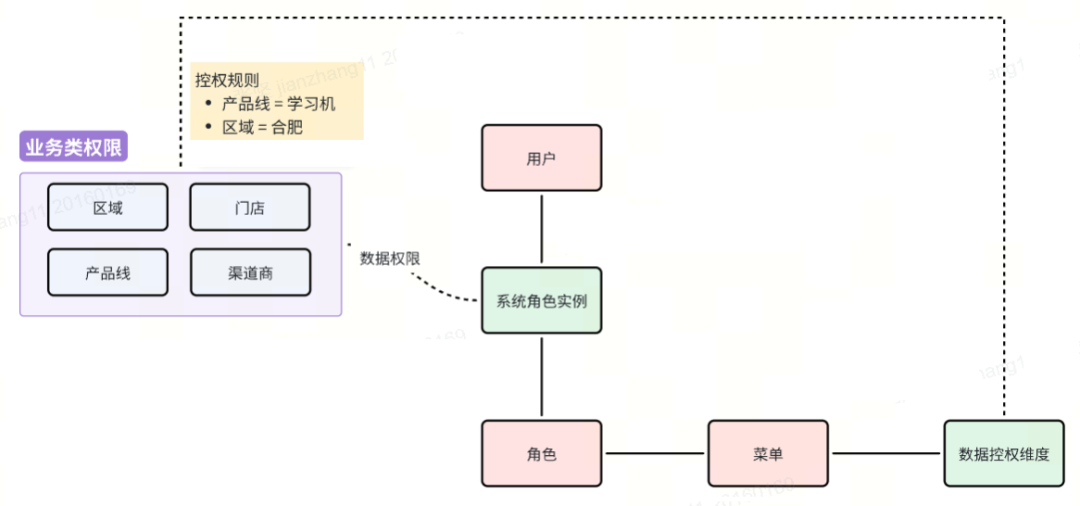
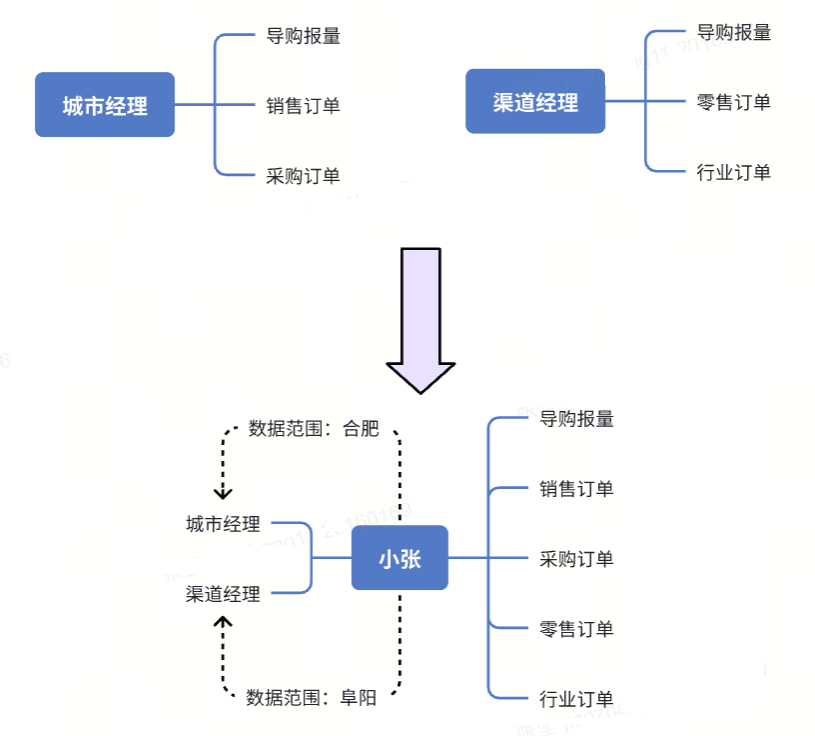
这是我们正在使用的权限控制方案,它解决了功能权限与数据权限的精细化管理问题。该方案的核心在于:菜单预先定义管控维度,用户通过角色获取功能权限,而数据权限则精确绑定到具体角色实例上。
举个例子,系统设有城市经理(导购报量、销售订单、采购订单)三个功能权限和(导购报量、零售订单、行业订单)渠道经理两个角色。当用户小张同时担任这两个角色时,给城市经理时分配合肥的数据范围,给渠道经理时分配阜阳的数据范围。此时小张进入系统后会智能处理权限:功能权限取并集,可访问全部5个功能菜单;数据权限则根据当前访问的菜单自动切换 - 访问销售订单时仅显示合肥数据,访问行业订单时仅显示阜阳数据。对于两个角色共有的导购报量功能,系统则会取合肥和阜阳数据的并集。
这种设计具有三大突出优势:一是实现了功能权限与数据权限的精准匹配,二是支持多角色灵活配置且互不干扰,三是通过自动识别菜单归属角色来智能应用对应数据范围。相比传统方案,它既避免了角色数量膨胀的问题,又解决了权限范围扩散的隐患。实际应用中只需注意明确菜单与角色的绑定关系,并制定好多角色共有菜单的默认数据处理规则即可。
小结
在数字化系统的权限管理演进中,我们探讨了四种典型的数据权限控制方案,第一种基于角色-菜单绑定的方案虽然实现了精确控制,却面临角色爆炸的困境;第二种用户-数据范围绑定的方案简化了管理,却牺牲了业务灵活性;第三种的混合方案也会面临权限放大的问题,我们采用的第四种通过菜单绑定控权维度和角色实例化设计,既解决了角色数量膨胀问题,又实现了数据权限的精准控制。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









