






本篇学习笔记对应深度学习入门课程 第四课 损失函数
前向传播之-损失函数

损失函数:在前面一节咱们介绍了得分函数,就是给定一个输入,对于所有类别都要给出这个输入属于该类别的一个分值,如上图所示,对于每一个输入咱们都有了它属于三个类别的得分,但是咱们光有这个得分却不知道如何来评判现在的一个分类效果,这节课咱们就要用损失函数来评估分类效果的好坏,而且不光是好坏还要表现出来有多好有多坏!

我们接下来就拿SVM的损失函数来说事吧。什么?你不知道SVM是啥?没关系,我会用很简单的语言来说这个损失函数的。对于SVM来说它的损失函数如上图的公式所示,我们要算的就是对于一个输入样本,这个样本的正确分类的分值和其他所有错误分类的分值的差值,再把这些所有的差值进行求和。我们拿这个小猫来举例吧,就是用它正确分类的分3.2与其它错误分类的得分5.1和-1.7求差值,再把求得的差值和0进行对比,如果大于0就加在最终的LOSS值上。细心的同学可能发现了上面的公式还加了一个数值1,那么这个数值代表着什么呢?它的意思啊就是说咱们求出的得分差异值还要去和咱们的满意程度进行比较,这个1就代表了咱们的满意程度有多大,这个值越大呢就说明咱们的要求越高。

图中红色的区域就是咱们的满意程度,一旦错误分类的得分(绿色区域)超过了红色值,就是说没达到咱们设定的满意程度值,LOSS值就要开始增加了。
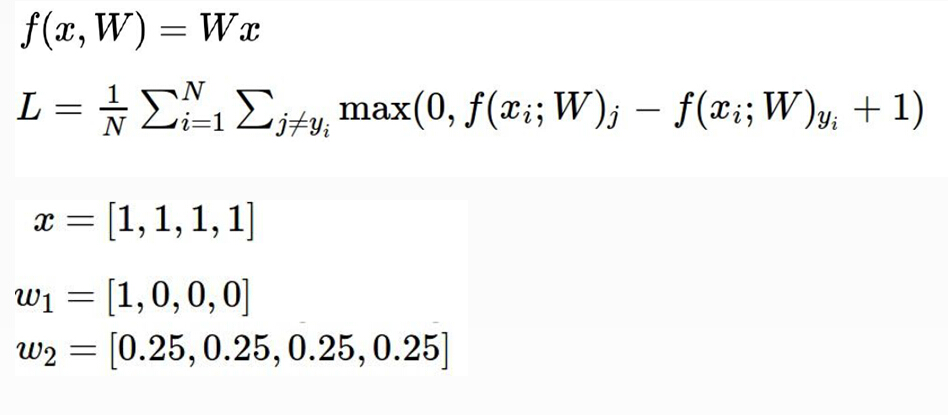
正则化:假设有一个样本x=[1,1,1,1],现在咱们有两组权重参数W1和W2如上图所示,这样对于得分值WX,两组权重参数得出的结果都一样,但是分值一样能说明这两个参数模型的分类效果一模一样吗?接下来就引入了咱们的正则化项来解决这个问题,正则化就是对权重参数进行惩罚,目的就是找到一组更平滑的参数项。正则化项的结果就是对于不同权重参数W进行不同力度的惩罚,惩罚也就是增加其LOSS值。正则化对于整个分类模型来说非常重要,可以很有效的抑制了过拟合现象。
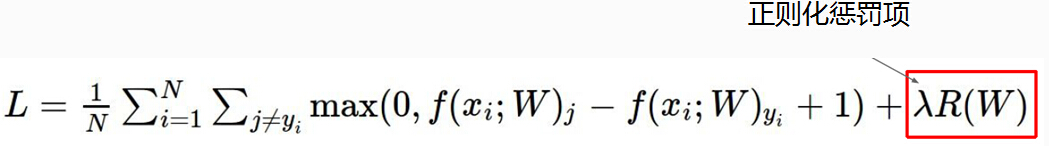
LOSS终极版:由LOSS最终版的公式可以看到。LOSS是由两部分组成的,一部分是得分函数对应的LOSS值另一个部分是正则化惩罚项的LOSS值。
















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











