









最大熵模型就是假设有些条件已知,未知的几个随机变量希望他们是等概率的,这样得到的熵最大,换句话说鸡蛋不要放在同一个篮子里。
先说条件熵为啥定义成这个样子,实际上就是某些条件已知,在这些条件上分别算熵(条件上当然是条件概率),最后加起来,用公式表示就是:
H
(
Y
∣
X
)
=
∑
i
=
1
m
P
(
X
=
x
i
)
H
(
Y
∣
X
=
x
i
)
=
∑
i
=
1
m
P
(
X
=
x
i
)
∑
j
=
1
n
P
(
y
j
∣
x
i
)
l
o
g
(
P
(
y
i
∣
x
i
)
)
H(Y|X)=\sum_{i=1}^mP(X=x_i)H(Y|X=x_i)\\ =\sum_{i=1}^mP(X=x_i)\sum_{j=1}^nP(y_j|x_i)log(P(y_i|x_i))
H(Y∣X)=i=1∑mP(X=xi)H(Y∣X=xi)=i=1∑mP(X=xi)j=1∑nP(yj∣xi)log(P(yi∣xi))
所以,在李航老师书上的定义就是,对于训练集上的数据
T
=
{
{
x
1
,
y
1
}
,
{
x
1
,
y
1
}
,
.
.
.
,
{
x
n
,
y
n
}
}
T=\{\{x_1,y_1\}, \{x_1,y_1\},...,\{x_n,y_n\}\}
T={{x1,y1},{x1,y1},...,{xn,yn}}以及特征函数
f
i
(
x
,
y
)
f_i(x,y)
fi(x,y),定义如下表达式,其中
P
~
(
x
)
\widetilde{P}(x)
P
(x)表示训练集上的经验分布
max
H
(
P
)
=
−
∑
x
,
y
P
~
(
x
)
P
(
y
∣
x
)
l
o
g
P
(
y
∣
x
)
s
.
t
.
E
p
(
f
i
)
=
E
P
~
(
f
i
)
,
i
=
1
,
2..
n
∑
y
P
(
y
∣
x
)
=
1
\max H(P)=-\sum_{x,y}\widetilde{P}(x)P(y|x)logP(y|x) s.t. \\ E_p(f_i)=E_{\widetilde{P}}(f_i), i=1,2..n\\ \sum_yP(y|x)=1
maxH(P)=−x,y∑P
(x)P(y∣x)logP(y∣x)s.t.Ep(fi)=EP
(fi),i=1,2..ny∑P(y∣x)=1
这个上拉格朗日乘数法,最后可以得到
P
w
(
y
∣
x
)
=
e
x
p
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
∑
y
e
x
p
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
P_w(y|x)=\frac{exp(\sum_{i=1}^nw_if_i(x,y))}{\sum_yexp({\sum_{i=1}^nw_if_i(x,y))}}
Pw(y∣x)=∑yexp(∑i=1nwifi(x,y))exp(∑i=1nwifi(x,y))
因此,最终x和y构成了一个最大团,用概率图表示就是
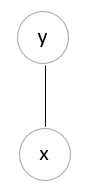
由于最开始建模的时候是直接用条件熵建的,因此还是判别式模型。
对比一下最大熵模型和最小熵原理的关系:任选一个孤立系统,达到平衡的时候它的熵一定是最大的(最大熵原理),达到平衡之后它的熵增一定是最小的(最小熵产生)
以下转载自: https://kexue.fm/archives/5448

朴素贝叶斯由训练数据学习联合概率分布P(X,Y),目标是后验概率P(Y|X)最大化(李航老师书里用条件期望的方式证明了期望风险最小化等价于后验概率最大化),后验概率P(Y|X)=最大似然P(X|Y)*先验概率P(Y)/P(X),X可以看做这次实验的结果,Y可以看做要求的模型的参数。因此先验概率P(Y)一般是某个分布、例如Beta分布等。最大似然P(X|Y)就是给定模型下,最终这事发生的概率最大,挑可能性最大对应的参数。P(X)是这次实验里得到的结果,P(X|Y)*P(Y)=P(X,Y)是联合概率分布,因此朴素贝叶斯是生成式模型。
P(Y|X)=P(X|Y)P(Y)/P(X),但是P(X|Y)太难求了,所以假设了条件独立,也就是
arg max
y
i
P
(
y
i
)
∏
j
P
(
x
j
∣
y
j
)
\argmax_{y_i}{P(y_i)\prod_jP(x_j|y_j) }
argmaxyiP(yi)∏jP(xj∣yj),因此朴素贝叶斯从这个表达式来看,对应的概率图模型是
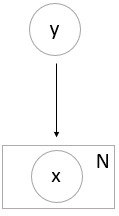















 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









