






深度学习框架TF的feature map的数据摆放格式是CHWC,onnx格式是HCHW,最近看到格式是HC4HW4不知道是什么意思?
作者:梁德澎
链接:https://www.zhihu.com/question/337513515/answer/768632471
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简单来说NC4HW4的数据排布其实就是和RGBA这种交织的数据排布类似。下面简单描述下NCHW如何转换成NC4HW4,首先batch维度就是N不变,然后把每个样本所有feature map按每四个通道为一组分成C/4个组,如果通道数不能整除4则补齐到4的倍数,补上的feature map全填0,然后把每组内的4个feature map按照RGBA交织的形式重新排列一下就得到NC4HW4的数据了。
为了解释更清晰,简单画个示意图:
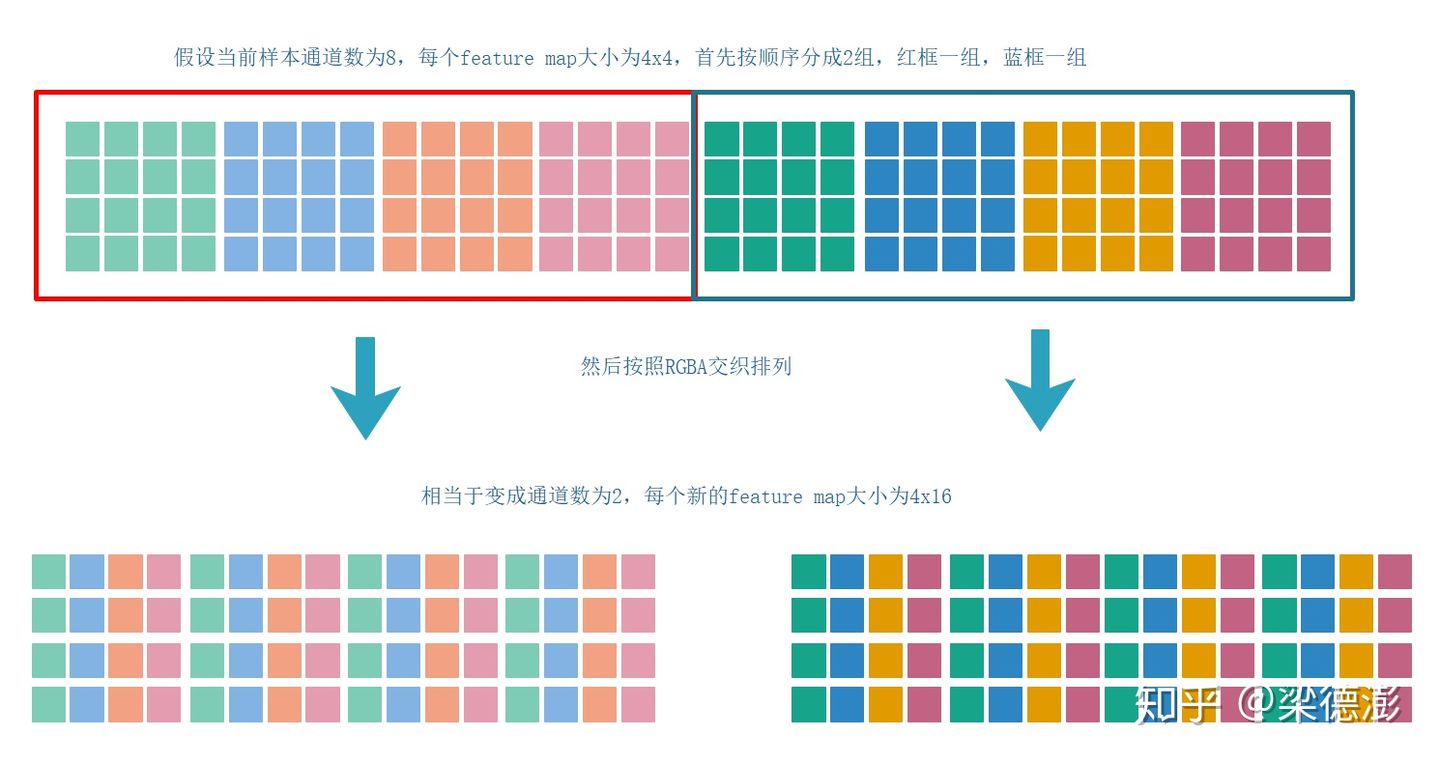
这种数据排布我也是最近接触mnn这个框架才了解到的。
看到有回答提到NC4HW4格式对于性能优化的好处,我这里也根据自己不多的优化经验补充一下对于NC4HW4这种格式的数据对于移动端上的卷积操作优化有什么好处吧。
不同的数据排布对应各自的优化方式,并不是说NC4HW4格式的数据排布算起来就一定比NCHW快,这还得看写代码的人的功力和根据实际问题去做实验,只能说NC4HW4优化起来相对更加的直观也更容易实现一点。不过NC4HW4这种格式的排布看起来对于网络剪枝这类的操作看起来就不太友好了。
下面用简单的1x3卷积来描述下NC4HW4格式数据在做卷积的时候相对于NCHW格式数据的优势,这里为了描述简单,假设就直接做卷积操作,不考虑gemm或者winograd等加速算法。
然后这里假设输入feature map通道数是4,空间大小是4x4,然后输出通道数也是4,所以权值的shape就是(4, 4, 1, 3),下面简单看看NCHW格式的数据的卷积怎么做:
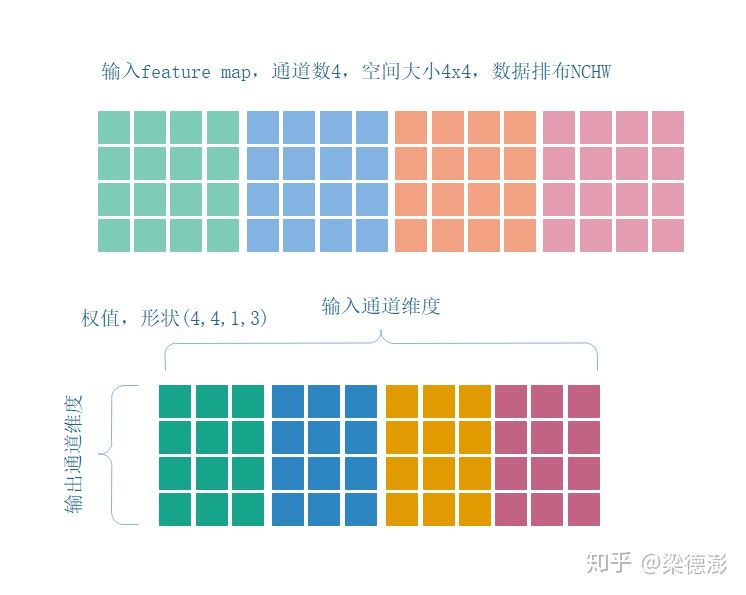
这里简单画下图,这样子解释起来更加直观,在NCHW排布下,计算第一个输出通道的第一个输出点的卷积计算过程如下:

可看到,从输入feature map每个channel对应位置取3个点(红框),然后同第一个输出通道对应的权值(蓝框)作点乘,然后再累加,这样子很直观,有什么问题呢,很明显,如果feature map空间size很大的话,这样子跳feature map通道取数据就会造成cache miss严重影响运行性能,当然实际要是真的去优化是不会这么做的,我这里只是为了突出下面要介绍的C4格式的运算。而且,由于每次乘法是3个数乘3个数,移动端上加速的话又不好用neon加速指令。但是如果转成C4格式的话,就好办多了:

然后计算输出feature map第一个位置的输出的时候,因为输出也是C4结构,所以优化的时候肯定要考虑,需要同时计算出4个输出通道的值,然后pack在一起:
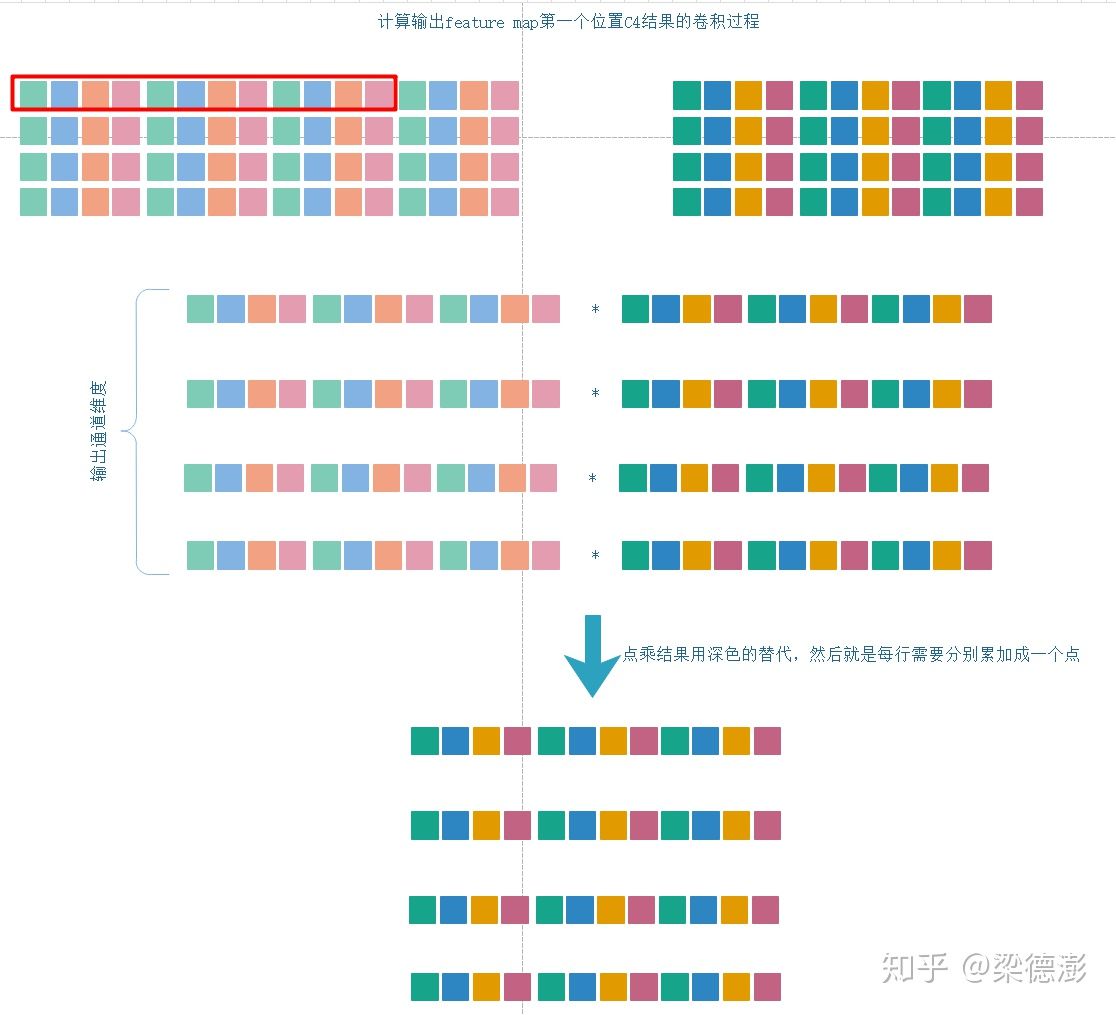
这里由于输出是C4格式,所以取不同通道之间的数据就变成连续的了,不存在cache miss的问题,然后权值也改成C4格式,直接就可以做点乘,很直观,得到结果再用neon的vpadd,做几次就可以很容易得到C4格式的输出。
talk is cheap,show me the code! :)
下面简单写下移动端上用neon加速的话核心代码是怎么样的:
作者:梁德澎
链接:https://www.zhihu.com/question/337513515/answer/768632471
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
float *src = ...; // 输入指针
float *dst = ...; // 输出指针
float *weight = ...; // 权值指针,连续排布
// 加载输入
float32x4_t src_c4_in0 = vld1q_f32(src);
float32x4_t src_c4_in1 = vld1q_f32(src + 4);
float32x4_t src_c4_in2 = vld1q_f32(src + 8);
// 加载第一个输出通道对应的权值
float32x4_t weight_c4_out0_in0 = vld1q_f32(weight);
float32x4_t weight_c4_out0_in1 = vld1q_f32(weight + 4);
float32x4_t weight_c4_out0_in2 = vld1q_f32(weight + 8);
// 加载第二个输出通道对应的权值
float32x4_t weight_c4_out1_in0 = vld1q_f32(weight + 12);
float32x4_t weight_c4_out1_in1 = vld1q_f32(weight + 16);
float32x4_t weight_c4_out1_in2 = vld1q_f32(weight + 20);
// 加载第三个输出通道对应的权值
float32x4_t weight_c4_out2_in0 = vld1q_f32(weight + 24);
float32x4_t weight_c4_out2_in1 = vld1q_f32(weight + 28);
float32x4_t weight_c4_out2_in2 = vld1q_f32(weight + 32);
// 加载第四个输出通道对应的权值
float32x4_t weight_c4_out3_in0 = vld1q_f32(weight + 36);
float32x4_t weight_c4_out3_in1 = vld1q_f32(weight + 40);
float32x4_t weight_c4_out3_in2 = vld1q_f32(weight + 44);
// 这里加载完刚好用满15个q寄存器
// 点乘
float32x4_t mul_out_c0_0 = vmulq_f32(src_c4_in0, weight_c4_out0_in0);
float32x4_t mul_out_c0_1 = vmulq_f32(src_c4_in1, weight_c4_out0_in1);
float32x4_t mul_out_c0_2 = vmulq_f32(src_c4_in2, weight_c4_out0_in2);
float32x4_t mul_out_c1_0 = vmulq_f32(src_c4_in0, weight_c4_out1_in0);
float32x4_t mul_out_c1_1 = vmulq_f32(src_c4_in1, weight_c4_out1_in1);
float32x4_t mul_out_c1_2 = vmulq_f32(src_c4_in2, weight_c4_out1_in2);
float32x4_t mul_out_c2_0 = vmulq_f32(src_c4_in0, weight_c4_out2_in0);
float32x4_t mul_out_c2_1 = vmulq_f32(src_c4_in1, weight_c4_out2_in1);
float32x4_t mul_out_c2_2 = vmulq_f32(src_c4_in2, weight_c4_out2_in2);
float32x4_t mul_out_c3_0 = vmulq_f32(src_c4_in0, weight_c4_out3_in0);
float32x4_t mul_out_c3_1 = vmulq_f32(src_c4_in1, weight_c4_out3_in1);
float32x4_t mul_out_c3_2 = vmulq_f32(src_c4_in2, weight_c4_out3_in2);
// 然后通道间累加,这里用第一个输出通道举例
float32x2_t mul_out_c0_0_padd = vpadd_f32(vget_low_f32(mul_out_c0_0), vget_high_f32(mul_out_c0_0));
float32x2_t mul_out_c0_1_padd = vpadd_f32(vget_low_f32(mul_out_c0_1), vget_high_f32(mul_out_c0_1));
float32x2_t mul_out_c0_2_padd = vpadd_f32(vget_low_f32(mul_out_c0_2), vget_high_f32(mul_out_c0_2));
float32x2_t mul_out_c0_01_padd = vpadd_f32(mul_out_c0_0_padd, mul_out_c0_1_padd);
float32x2_t mul_out_c0_012_padd = vpadd_f32(mul_out_c0_01_padd, mul_out_c0_2_padd);
// 其他三个通道类似的操作,最后可以得到
// float32x2_t mul_out_c0_012_padd
// float32x2_t mul_out_c1_012_padd
// float32x2_t mul_out_c2_012_padd
// float32x2_t mul_out_c3_012_padd
// 得到最后的输出结果,一个输出点的C4格式结果
float32x4_t out_c4 = vcombine_f32(vpadd_f32(mul_out_c0_012_padd, mul_out_c1_012_padd), vpadd_f32(mul_out_c2_012_padd, mul_out_c3_012_padd));
vst1q_f32(dst, out_c4);作者:jianyang
链接:https://www.zhihu.com/question/337513515/answer/769063787
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
会问提问题的都是好同学。这种格式针对16bits ,8bits极大减少内存读指令,提高cacheline利用率,从而获得较高的峰值性能。对32bits数据也可能有1-3个百分点的性能提高,但是不明显。
假设你已经明白卷积可以变换为矩阵运算。那么tensorcore的矩阵运算是4*4的矩阵A和4*4的矩阵B,如果为16bits FP 16,NCHW需要产生4条显存读指令去读4个FP 16,GPU系统设计为32bits的数据单元,那么读效率降低一半,还需要计算4个读地址,64位的读写地址计算相当耗费valu,然后使用8条指令把这4个FP 16拼成2个32bits,或者4条共享存储指令做拼接,或者shuffle指令做拼接。如果变成vector =4,那么之需要一条显存读指令就可以完成了。
另外,由于一个缓存块是128bytes, 如果遇到缓存边界元素,那么NCHW缓存的利用率只有1/64,而且需要读4个缓存块。而NCHW 4 vector =4可以只读一个缓存块,极大降低对二级缓存到一级缓存带宽,而且降低延迟。24kB一级缓存只有192个缓存块。缓存块的资源相当有限。
还有,tensorcore需要在共享存储之间不停地搬运数据,NCHW 4的结构搬运效率高。
绝大部分的Channels是8的倍数,NCHW 4可以比较好地适应大多数情况。















 2324
2324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









