






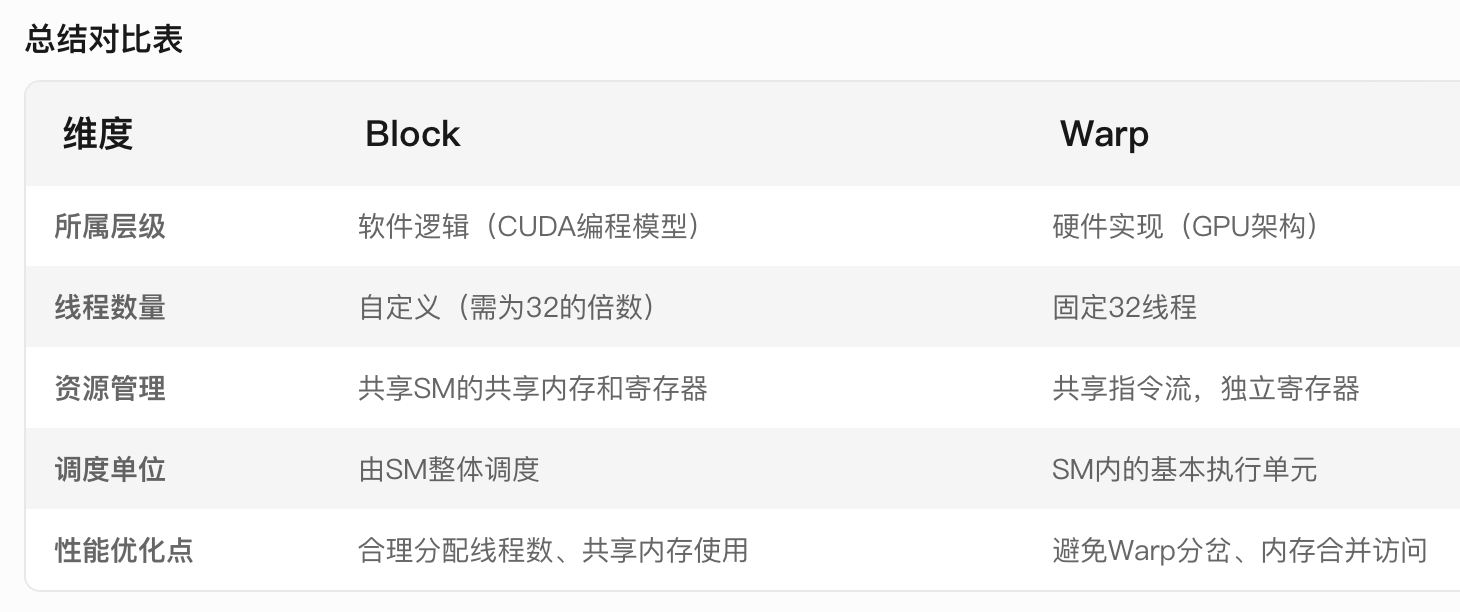
GPU Block和Wrap的区别
- Block 是CUDA编程模型中的逻辑分组单元,由多个线程(Thread)组成,属于软件抽象概念。开发者通过Block划分并行任务,同一Block内的线程可共享共享内存(Shared Memory)并同步操作
- Warp 是GPU硬件层面的基本调度和执行单位,通常由32个线程组成,属于硬件实现机制。Warp的划分由硬件自动完成,程序员无法直接控制。
SM Activity
SM Activity指在特定时间间隔内,GPU中活跃的流多处理器(Streaming Multiprocessors, SM)的百分比。每个SM由多个CUDA核心、寄存器、共享内存等组件构成,负责执行并行计算任务。例如,Nvidia H100 GPU包含132个SM,每个SM有128个CUDA核心,总核心数达16896个。SM Activity反映的是这些硬件资源被实际调用的程度,而非仅监测是否有任务在运行(如传统GPU利用率指标)
SM Activity与GPU利用率的区别
- GPU利用率 :仅显示是否有计算任务(kernel)在执行,无法区分核心的实际使用情况。例如,仅执行内存读写(0浮点运算)时,GPU利用率仍可能显示100%
- SM Activity :更精确地反映SM的并行计算能力是否被充分利用。例如,若仅1个SM持续工作(其他131个闲置),SM Activity仅为0.7%,而GPU利用率仍为100%
影响SM Activity的因素
- 任务并行化不足 :未将计算任务合理分配到多个SM上,导致部分SM闲置。
- Warp分歧(Warp Divergence) :同一Warp(32个线程)中的线程执行不同指令路径时,SM需串行处理分支,降低效率。
- 内存访问延迟 :频繁的全局内存读写会导致SM等待数据,降低活跃时间占比
- 内核(Kernel)设计 :未优化的计算密集型内核(如传统Softmax)可能无法充分利用SM的多个核心或张量核心
优化SM Activity的策略
- 内核融合(Kernel Fusion) :将多个小计算操作合并为单一内核,减少内存读写和调度开销。例如,使用FlashAttention优化Transformer模型中的注意力计算。
- 提升任务并行度 :确保线程块(Block)和网格(Grid)的配置充分利用所有SM。例如,根据GPU型号调整Block大小(如H100建议每个Block包含128-256线程)。
- 减少Warp分歧 :避免条件分支或通过数据预处理统一线程执行路径。
- 使用专用硬件单元 :如利用Tensor Core加速矩阵运算,或通过RT Core优化光线追踪负载
监控工具与指标
- Nvidia DCGM:提供SM活动数据的实时监控,支持细粒度性能分析。
- PyTorch Profiler:可逐层分析SM效率,识别瓶颈操作(如低效的Softmax层)。
- Nsight Compute:深入分析内核的SM占用率(Occupancy)和指令吞吐量
GPU Utilization
对应 DCGM 的 DCGM_FI_PROF_GR_ENGINE_ACTIVE,表示在一个时间间隔内 Graphics 或 Compute 引擎处于 Active 的时间占比。Active 时间比例越高,意味着 GPU 在该周期内越繁忙。该值比较低表示一定没有充分利用 GPU,比较高也不意味着已经充分利用 GPU。如下图所示,表示几个 GPU 的 Utilization 到了 80%-90% 左右:

GPU SM Active
对应 DCGM 的 DCGM_FI_PROF_SM_ACTIVE,表示一个时间间隔内,至少一个 Warp 在一个 SM 上处于 Active 的时间占比,该值表示所有 SM 的平均值,对每个 Block 的线程数不敏感。该值比较低表示一定未充分利用 GPU。如下为几种 Case(假设 GPU 包含 N 个 SM):
Kernel 在整个时间间隔内使用 N 个 Block 运行在所有的 SM 上,对应 100%。
Kernel 在一个时间间隔内运行了 N/5 个 Block,该值为 20%。
Kernel 有 N 个 Block,在一个时间间隔内只运行了 1/4 时间,该值为 25%。
如下图所示为几个 GPU 的 SM Active,可见只有 60% 左右,还有一定提升空间:

GPU SM Occupancy
对应 DCGM 的 DCGM_FI_PROF_SM_OCCUPANCY,表示一个时间间隔内,驻留在 SM 上的 Warp 与该 SM 最大可驻留 Warp 的比例。该值表示一个时间间隔内的所有 SM 的平均值,该值越高也不一定代表 GPU 使用率越高。
如下图所示为几个 GPU 的 SM Occupancy,只有 20% 多:

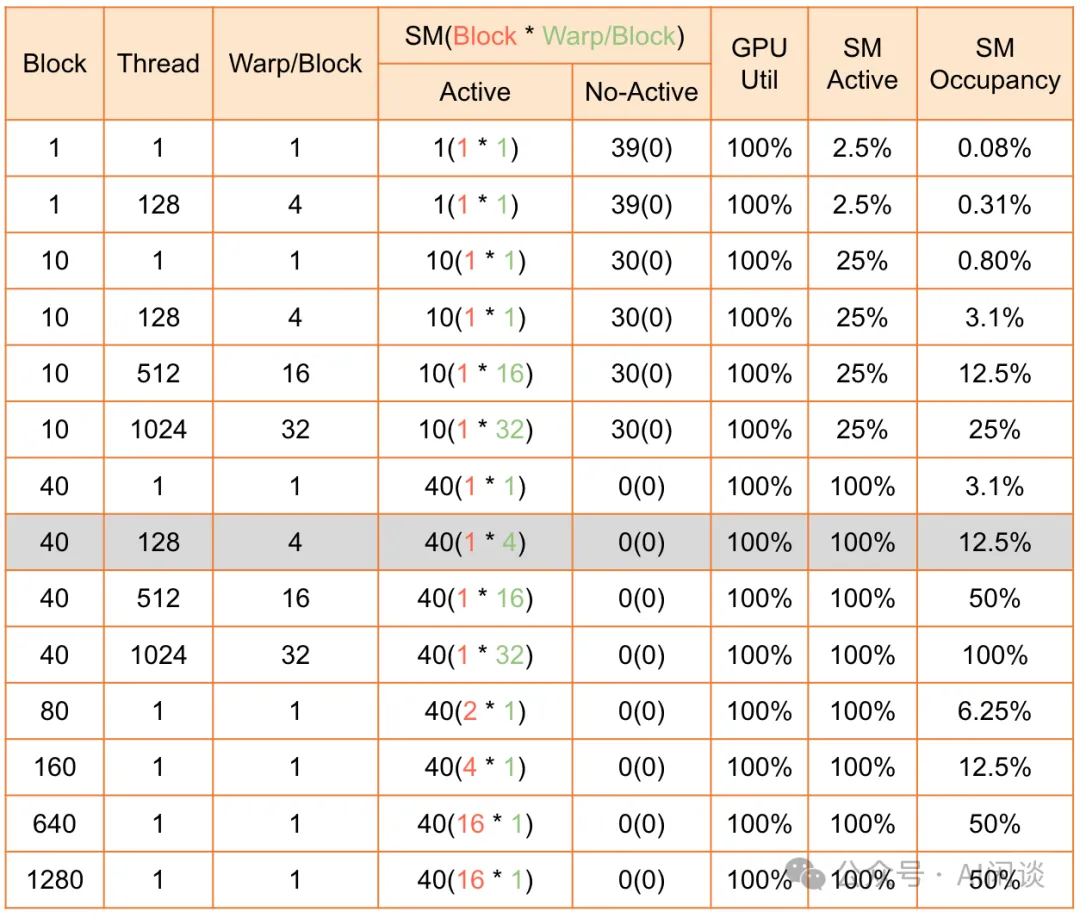
来个例子
如下图所示,我们在 T4 GPU(包含 40 个 SM) 上通过一个小的实验来说明几个指标的关系:
- 当只有 1 个 Block,1 个 Thread 时,GPU Util 也是 100%,因为 GPU 一直在占用,此时 40 个 SM 中只有 1 个一直 Active,所以 SM Active 为 2.5%。
- 当有 40 个 Block,每个 Block 1 个 Thread 时,GPU Util 为 100%,SM Active 也为 100%,因为每个 Block 都会占用一个 SM。
- 当有 40 个 Block,每个 Block 128 个 Thread 时,GPU Util 为 100%,SM Active 也为 100%,因为每个 Block 都会占用一个 SM。此时 SM Occupancy 到了 12.5%。

TensorCoreUtility
- TensorCore Utility指代与Tensor Core硬件加速单元相关的软件工具或编程接口。这类工具通常用于优化深度学习中的矩阵运算,例如通过混合精度(FP16/FP32)计算加速GEMM(通用矩阵乘法)和卷积操作。
- 例如:在CUDA编程中,通过调用特定库(如cuBLAS或cuDNN)利用Tensor Core的硬件加速能力。
- 优势:相比传统CUDA Core,Tensor Core可在一个时钟周期内完成4x4x4的矩阵乘法(64次FMA运算),显著提升计算吞吐量。
- SMActivity
- 可能指与流多处理器Stream Multiprocessor, SM相关的任务调度或执行活动。SM是GPU的核心处理单元,负责管理线程束(Warp)的指令分发、寄存器分配等。
- 例如:在Volta架构中,每个SM包含多个Tensor Core和CUDA Core,其调度器需协调不同类型运算(如矩阵乘法与标量计算)的资源分配。
- 特点:SM活动更偏向底层的线程管理和通用计算任务,而非专用硬件加速。
原文
https://mp.weixin.qq.com/s?__biz=Mzk0ODU3MjcxNA==&mid=2247487054&idx=1&sn=fd540ee08fc40211d51856a146d22ac8&chksm=c364c90bf413401dc34fb9944f511a2960d4c532ea9bd8e4f88c696a5a7a6c58e549c73a8e27&scene=21#wechat_redirect

















 3276
3276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









