






OCRNet原文链接:https://arxiv.org/pdf/1909.11065.pdf
OCRNet是今年新提出的Image Semantic Segmentation网络。整篇论文读下来,最大的感受就是文章内容非常充实,可以看出作者团队在很多个benchmark和baseline都做了大量对比实验,而且论文的思路清晰,创新点比较合理,值得认真品读和借鉴。
对于语义分割这种精细的像素级图像分类任务而言,每个像素的上下文信息都是极其重要的。现有的大量基于Context的文章,大致可以分为multi-scale context和relational context两种,DeepLab系列均属于前一种类型,旨在提取每个像素不同范围内的上下文信息来改善模型的性能;而OCRNet属于后一种类型,旨在通过当前pixel position与contextual pixel的相关关系来整合上下文信息,得到增强的pixel representation。
文章里提到,DANet、CFNet和OCNet这些Relational Context Model都是基于self-attention scheme, 通过pixel representation之间的相关性去整合信息;一些更好的模型,例如Double Attention、ACFNet,借鉴了superpixel方法的分区域分类思想,把图片像素分成若干个区域,采用region representation的形式去代表区域的信息,并利用pixel-region relation去进行context aggregation。

顺着region representation aggregation的思路和方法思考,作者认为仅仅将区域均匀划分是不足够充分的。如原文图2所示,ASPP方法中对multi-scale context进行整合,然而这些context的位置却杂乱地分布在不同的物体身上;文章提出的OCR方法按照物体划分区域,那么每个region context都代表一个物体,这使得context具有了很明确的语义含义,这是OCR方法比基于multi-scale context的ASPP和基于relational context的Double Attention等等都要更优秀的一个地方。

如原文图3所示,OCR module先从Backbone网络中提取intermediate feature maps,并将它们处理为(上采样)到与输入图片相同resolution,作为OCR module的输入pixel representation;同样地从Backbone中提取intermediate feature maps,通过上采样和1*1 convolution得到一组coarse segmentation maps。OCR module会根据每个pixel被分为某个类的概率对pixel representation进行weighted sum,得到各个类的region representation,这一步被称为gathering。接着,OCR module会求取每个position上的pixel representation每个region representation的相关权重系数,并通过每个位置上的相关权重系数对region representation进行weighted sum,得到该位置的contextual representation,这一步被称为redistribution。最后,把contextual representation与输入的pixel representation在通道维度上进行concatenation,通过一个1*1 conv后得到最终的augmented representation。这里的一个细节是,coarse segmentation maps也要受到loss function的监督,即是说整个loss function包括最后的fine segmentation loss和中间的coarse segmentation loss两项。
OCRNet主要还是对relational context scheme下的区域划分策略做出了改进,它的relation计算过程与主流的sota模型类似,如原文式(3)、(4)所示:
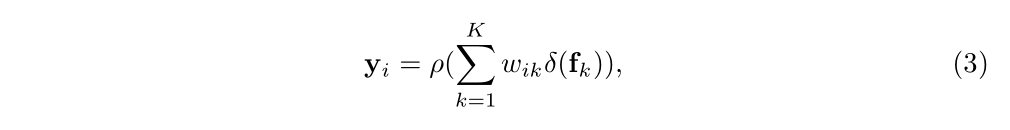
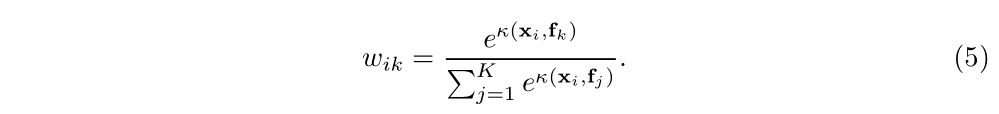
可以看到,对于region representation的计算设计(gathering)得较为简单,仅仅通过每个pixel分到各个区域的normalized degree of confidence去对pixel representation做weighted sum;后续的redistribution设计得比较复杂,每个region representation要先做一个变换;每个相关权重系数通过对pixel representation和region representation分别做变换后的cosine similarity再softmax后得到。注意这里的变换函数都是通过1*1 conv ->BN->ReLU完成的,这也给予了redistribution更好的学习能力和灵活性。
关于OCRNet模型的performance,原文做了翔实的对比实验,充分说明了OCRNet的优越性,这里只看其中的一部分,如原文T.2、T.3、T.4所示:

可以看到在Cityscapes、ADE20K以及LIP数据集上,OCRNet从性能和复杂度上都要优于现有的multi-scale context scheme和relational context scheme。与OCRNet最接近的是Double Attention模型,两者的计算复杂度和运算效率相差无几,但OCRNet从性能上全面优于Double Attention,成为了新的SOTA模型。















 273
273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









