






这篇文章比较少见地讨论了weakly-and-semi-supervised setting下的混合标签训练问题,即如何高效地把少量精确标签和大量粗糙标签混合起来,训练出性能更高的语义分割网络。文章作者发现,现有的weakly-and-semi-supervised semantic segmentation网络采取同等的方法对待与处理strong label和weak label来训练一个single-branch network,这样做的后果是训练出来的网络性能比仅仅采用strong label时还要差,如原文图2所示:

可以看到,采用weakly-supervised网络DSRG进行实验,最终发现在strong label的基础上额外增加weak label训练single-branch network比单纯采取strong label有大幅度的性能下降,且也仅仅比全部采用weak label有略微的提升。对于这样的实验现象,作者认为主要的原因来自于strongly labeled data和weakly labeled data之间有着天然的不一致性,后者天然比前者的精度更低;此外,weakly labeled data的数量通常要比strongly labeled data要多得多,这就存在所谓的采样不平衡(sample imbalance)问题,若在训练时不采用额外的措施,网络将很容易对weakly labeled data产生过拟合,而忽略了本身精确度更高的strongly labeled data。
针对采样不平衡的问题,作者对过采样(oversampling)的方法进行了实验研究,实验表明,对strongly labeled data进行过采样的确能够提升混合训练网络的性能,然而相比单纯采用strongly labeled data仍然难以令人满意。
作者提出的核心部分是一个dual-branch network的结构,即在原有的backbone网络后面加上一个共享的neck module和两个并行独立的branch,整体架构如原文图3所示:
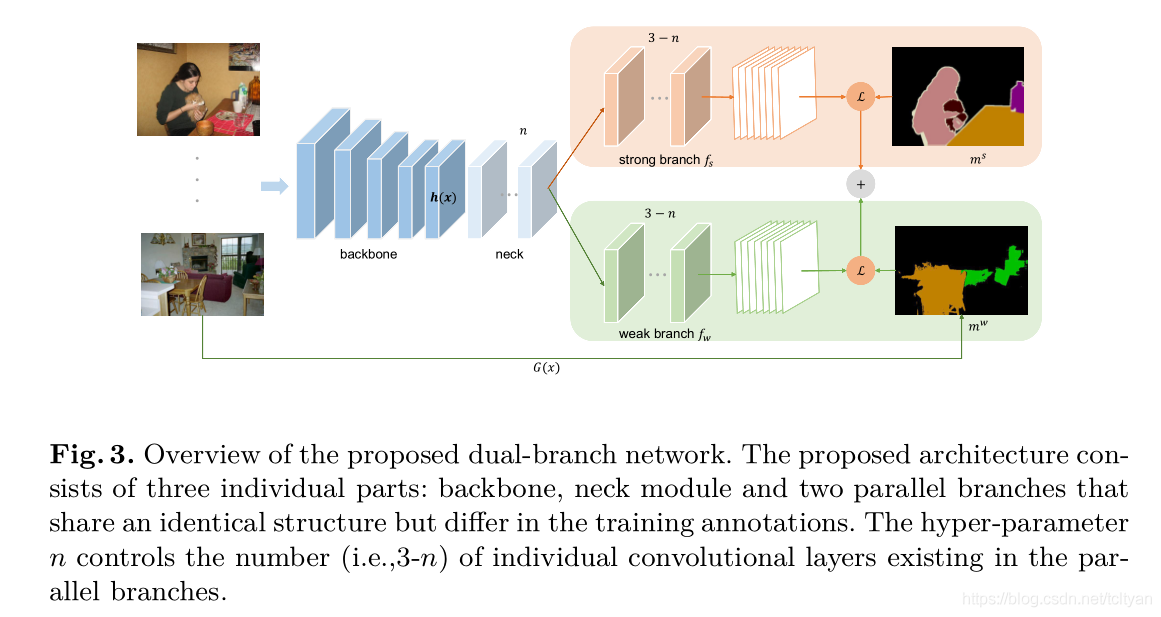
作者采用超参数n来控制strong-weak dual-branch的共享参数模块,即neck module的卷积层数量,通过调节n可以得到更灵活的网络配置。网络整体的架构还是比较清晰明了的,主要的思想在于分别用独立的paralleled branch来处理strongly labeled data和weakly labeled data,这样就能避免在sample imbalance和supervision inconsistency影响下后者带来的负面影响,从而充分利用额外数据带来的监督信息。

如原文图5所示,把网络输入的batch分为两半,前一半由strong branch处理,后一半由weak branch处理。具体是通过把strong branch output 的batch dimension前一半和weak branch output的batch dimension后一半连接在一起,再进行最终的交叉熵损失计算。在推理时,仅采用dual-branch网络的strong branch进行inference输出。

如原文表2所示,采用oversampling的dual-branch network取得了远超其他weakly-and-semi-supervised网络的性能,并且在性能上接近了fully-supervised网络。值得一提的是,把weak branch的数据标签换为gt后,网络性能仍然取得了一部分提升,这或者表明PASCAL VOC 2012的原生训练集和增加的扩增数据集之间仍然存在一定的inconsistency。














 2271
2271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









