









具体的网络结构可以参照我的前一篇博客基于RNN的文本分类模型(Tensorflow)
考虑到在实际应用场景中,数据有可能后续增加,另外,类别也有可能重新分配,比如银行业务中的[取款两万以下]和[取款两万以上]后续可能合并为一类[取款],而重新训练模型会浪费大量时间,因此我们考虑使用迁移学习来缩短训练时间。即保留LSTM层的各权值变量,然后重新构建全连接层,即图中的Softmax层。
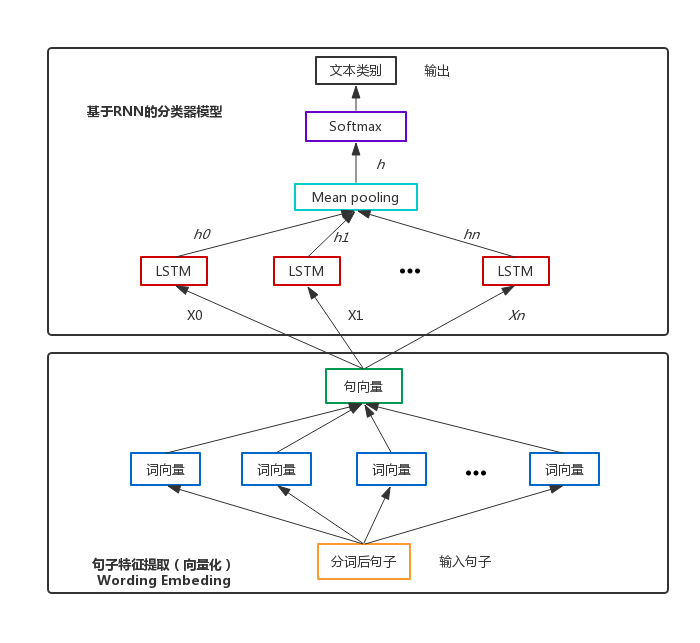
分类器模型结构图
具体迁移过程如下(代码基于Python3.5/Tensorflow1.2 github代码地址):
Step1 构建网络模型
with tf.name_scope("Train"):
with tf.variable_scope("Model", reuse=None, initializer=initializer):
model = RNN_Model(config=config, num_classes=num_classes, is_training=True)
with tf.name_scope("Valid"):
with tf.variable_scope("Model", reuse=True, initializer=initializer):
valid_model = RNN_Model(config=valid_config, num_classes=num_classes, is_training=False)Step1 构建网络模型
Step2 初始化变量(这一步要先做,以免覆盖后续加载的Variable)
Step3 restore之前保存的网络权值,这里做了判断
如果没有模型文件的话就从头开始训练
有模型文件存在,但是输出类别没有发生变化的话,就接着训练
有模型文件,同时输出类别发生了改变,就进行迁移学习
if os.path.exists(checkpoint_dir):
classes_file = codecs.open(os.path.join(config.out_dir, "classes"), "r", "utf-8")
classes = list(line.strip() for line in classes_file.readlines())
classes_file.close()
# 类别是否发生改变
if sorted(classify_names) == sorted(classes):
print('-----continue training-----')
new_classify_files = []
for c in classes:
idx = classify_names.index(c)
new_classify_files.append(classify_files[idx])
# classify_files = new_classify_files
restored_saver = tf.train.Saver(tf.global_variables())
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
print('restore model: '.format(ckpt.model_checkpoint_path))
restored_saver.restore(session, ckpt.model_checkpoint_path)
else:
print('-----train from beginning-----')
else:
print('-----change network-----')
not_restore = ['softmax_w:0', 'softmax_b:0']
restore_var = [v for v in tf.global_variables() if v.name.split('/')[-1] not in not_restore]
restored_saver = tf.train.Saver(restore_var)
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
print('restore model: '.format(ckpt.model_checkpoint_path))
restored_saver.restore(session, ckpt.model_checkpoint_path)
else:
pass
classes_file = codecs.open(os.path.join(config.out_dir, "classes"), "w", "utf-8")
for classify_name in classify_names:
classes_file.write(classify_name)
classes_file.write('\n')
classes_file.close()
else:
print('-----train from begin-----')
os.makedirs(checkpoint_dir)
classes_file = codecs.open(os.path.join(config.out_dir, "classes"), "w", "utf-8")
for classify_name in classify_names:
classes_file.write(classify_name)
classes_file.write('\n')
classes_file.close()Step4 开始训练
经验证,很快loss就收敛了,由于数据的变动不是很大,因此一个epoch就能到达收敛,持续好几个小时的重复训练可以缩短至几分钟。
另外,在写代码的过程中,发现restored_saver.restore()这个函数的作用是加载之前保存模型的各Variable,而Graph需要自己重新画,这个函数的好处是,可以只加载你想要的Variable,不想要的可以丢掉,例如本文中,需要舍弃Softmax层的w 和b,可以这样写:
not_restore = ['softmax_w:0', 'softmax_b:0']
restore_var = [v for v in tf.global_variables() if v.name.split('/')[-1] not in not_restore]
restored_saver = tf.train.Saver(restore_var)
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
print('restore model: '.format(ckpt.model_checkpoint_path))
restored_saver.restore(session, ckpt.model_checkpoint_path)
如果不希望重复定义图上的运算,也可以使用tf.train.import_meta_graph()直接加载已经持久化的图,之前那篇博客在调用训练好的模型进行分类时,就是这么做的:
saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_file))
saver.restore(self.session, checkpoint_file)这个函数会把整个Graph连同里面的各个量一股脑加载进来,这样就导致不能对模型进行微调(fine tuning),就连batch size也是不能改,考虑到这一点,那时候我在训练的时候验证集对应的model只能设成1了。
对比感觉还是用restored_saver.restore()更方便、灵活一点,也不容易出错。

















 1708
1708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









