







更多优质内容,请关注公众号:智驾机器人技术前线
1.论文信息
-
论文标题:CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
-
作者:Hidehisa Arai, Keita Miwa, Kento Sasaki, Yu Yamaguchi, Kohei Watanabe, Shunsuke Aoki, Issei Yamamoto
-
作者单位:Turing Inc, 东京大学, 筑波大学, Keio Research Institute at SFC, National Institute of Informatics
-
论文链接:https://www.arxiv.org/abs/2408.10845
2.摘要
自动驾驶领域面临许多不可预见的场景,这要求系统具备复杂的推理和规划能力。虽然多模态大语言模型(MLLMs)为此提供了一个有希望的途径,但它们主要用于理解复杂的环境背景或生成高级驾驶指令,很少有研究将其应用扩展到端到端的路径规划。一个主要的研究瓶颈是缺乏包含视觉、语言和动作的大型注释数据集。为了解决这个问题,我们提出了CoVLA(全面视觉-语言-动作)数据集,这是一个包含超过80小时真实驾驶视频的广泛数据集。该数据集采用了一种新颖的、可扩展的方法,基于自动化数据处理和标题生成流程来生成与详细的自然语言描述相匹配的驾驶轨迹,描述了驾驶环境和操作。这种方法利用了原始的车内传感器数据,使其在规模和注释丰富度方面超越了现有数据集。使用CoVLA,我们研究了能够处理各种驾驶场景中视觉、语言和动作的MLLMs的驾驶能力。我们的结果展示了我们的模型在生成连贯的语言和动作输出方面的强能力,强调了视觉-语言-动作(VLA)模型在自动驾驶领域的潜力。该数据集通过提供一个全面的平台来训练和评估VLA模型,为构建健壮、可解释且数据驱动的自动驾驶系统奠定了框架,有助于实现更安全、更可靠的自动驾驶车辆。
3.主要贡献
-
介绍了CoVLA数据集,这是一个大规模数据集,为各种驾驶场景提供轨迹目标,以及详细的逐帧情境描述;
-
提出了一种可扩展的方法,通过传感器融合准确估计轨迹,并自动生成关键驾驶信息的帧级文本字幕
-
开发了CoVLA-Agent,这是一个新颖的VLA模型,用于在CoVLA数据集之上实现可解释的端到端自动驾驶。我们的模型展示了持续生成驾驶场景描述和预测轨迹的能力,为更可靠的自动驾驶铺平了道路。
4.核心思想与方法
我们开发了CoVLA-数据集,这是一个全面的自动驾驶数据集,包括独特的10,000个视频剪辑、描述驾驶场景的逐帧语言字幕和未来轨迹动作。我们还展示了CoVLA-agent,这是一个基于VLM的路径规划模型,能够预测车辆的未来轨迹,并提供其行为和推理的文本描述。
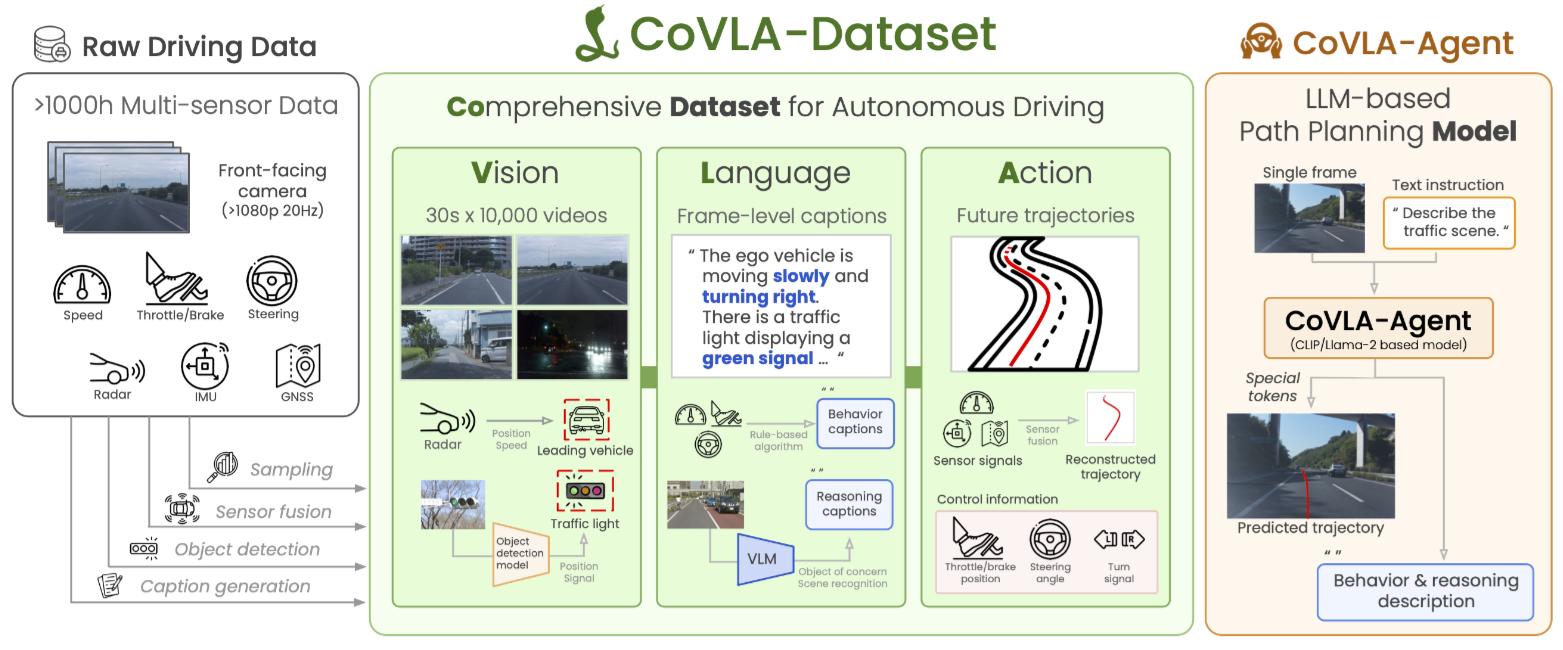
5.数据集概括
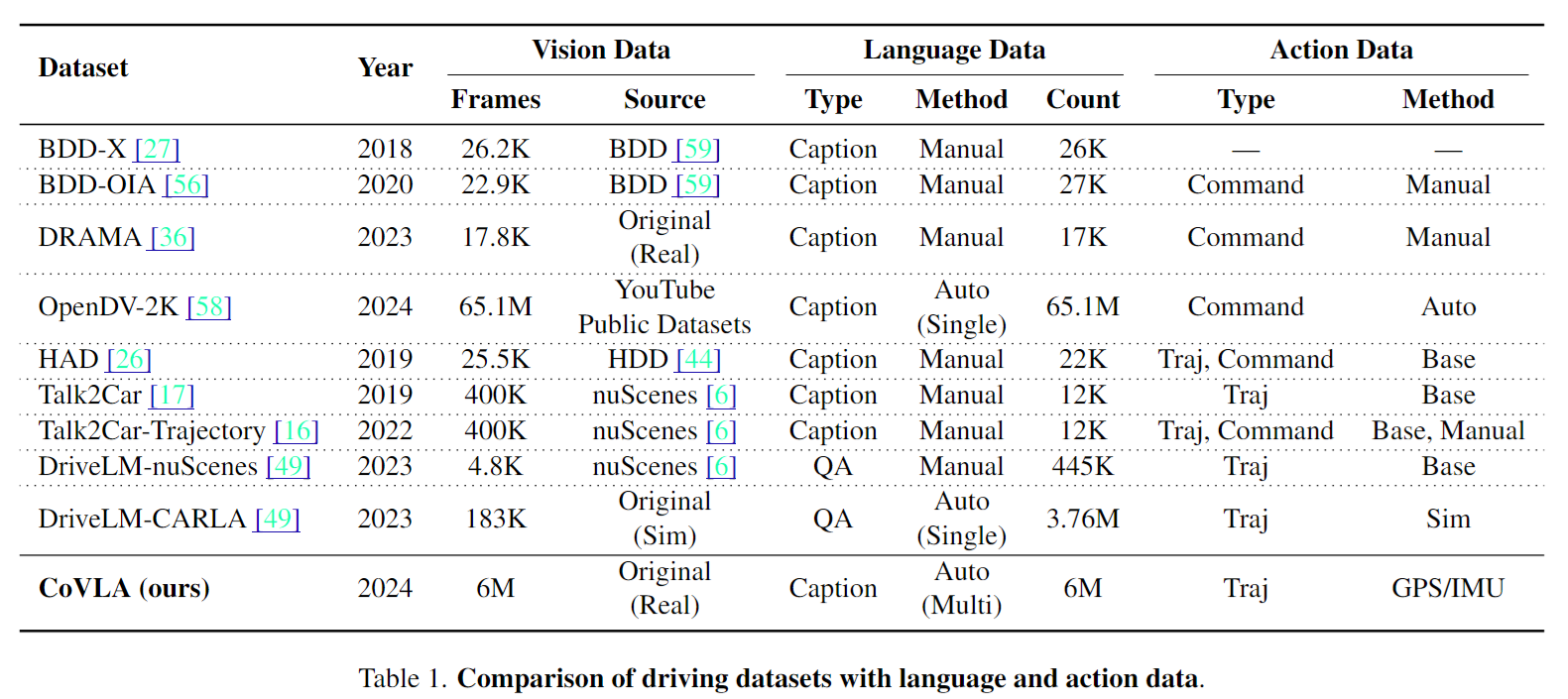
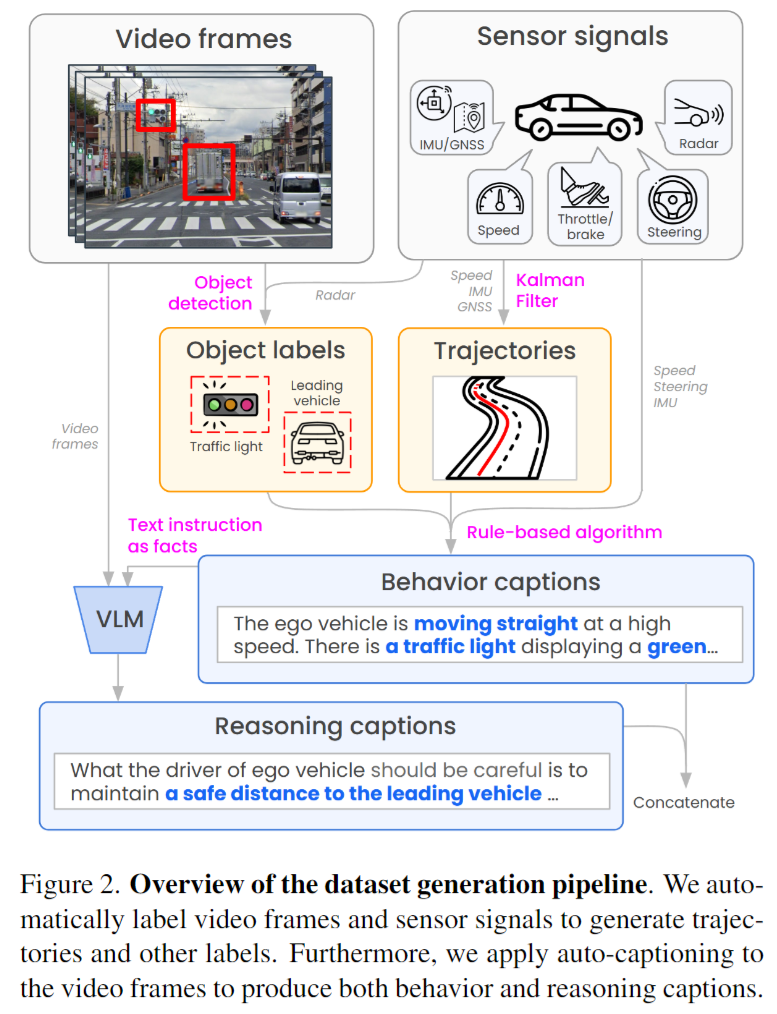

6.使用仿真验证
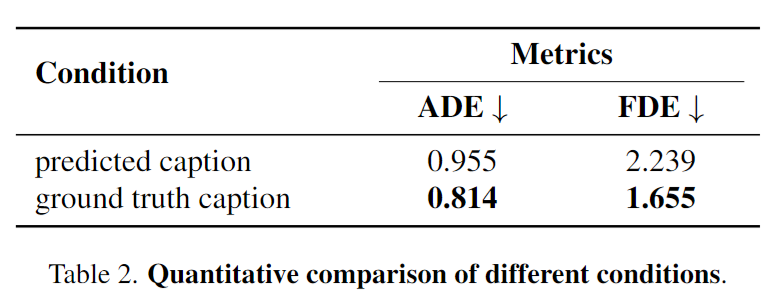
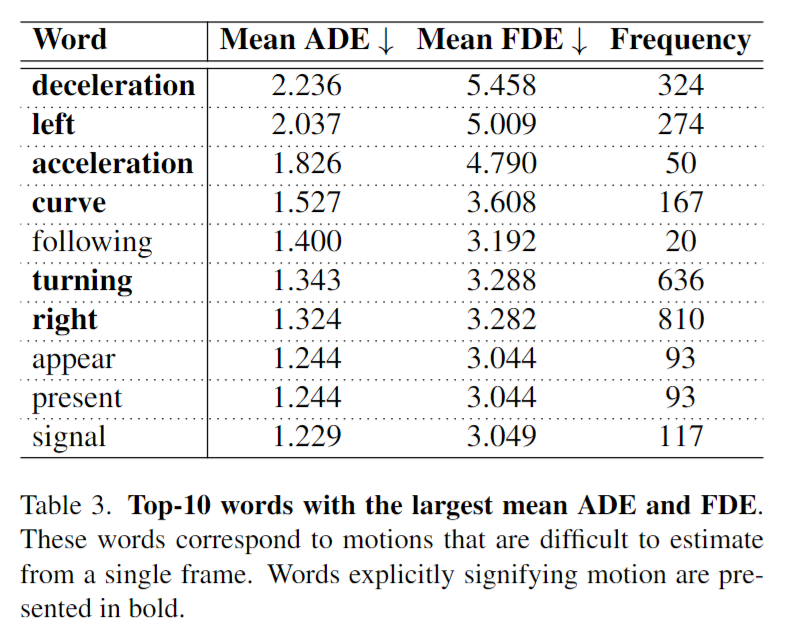
7.总结
在这项研究中,我们介绍了CoVLA-数据集,这是一个用于自动驾驶的新型VLA模型数据集。通过利用可扩展的自动化方法,我们构建了一个大规模、全面的、富含详细语言注释的数据集。在这个强大的数据集基础上,我们开发了CoVLA-agent,一个复杂的VLA自动驾驶模型。评估结果强调了模型的强大能力,它能够生成连贯的语言和动作输出。这些发现突出了VLA多模态模型的变革潜力,并为自动驾驶研究的未来发展铺平了道路。


本文仅做学术分享,如有侵权,请联系删文!
更多优质内容,请关注公众号:智驾机器人技术前线
















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









