







高斯混合模型(GMM)深度解析:从概率密度到 EM 算法的全流程实践
高斯混合模型(Gaussian Mixture Model, GMM)是一种强大的概率密度建模工具,通过多个高斯分布的线性组合拟合复杂数据分布。本文结合理论推导与代码实践,系统讲解 GMM 的核心原理、EM 算法优化流程及实际应用场景。重点扩展参数初始化策略、协方差矩阵类型选择、收敛性分析等关键问题,并通过可视化案例展示模型训练过程。
文章目录
一、GMM 的数学本质
-
混合密度函数
GMM 假设数据由多个高斯分布混合生成: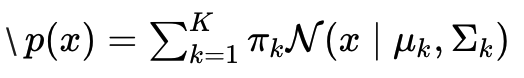
- 几何意义:每个高斯成分对应数据的一个潜在 “子簇”,混合系数π**k表示该子簇的先验概率。
- 参数空间:共需估计K×(D+D(D+1)/2+1)个参数(D 为数据维度)。
-
生成式视角
数据生成过程可视为两步随机过程:

二、EM 算法的核心推导
-
E 步:责任度分配

- 数值稳定性:计算时需防止浮点下溢,可通过对数变换或归一化处理。
代码实现:
def _e_step(self, X):
responsibilities = np.zeros((self.n_components, len(X)))
for k in range(self.n_components):
responsibilities[k] = self.weights_[k] * multivariate_normal.pdf(
X, mean=self.means_[k], cov=self.covariances_[k]
)
responsibilities /= responsibilities.sum(axis=0) # 归一化
return responsibilities
-
M 步:参数更新
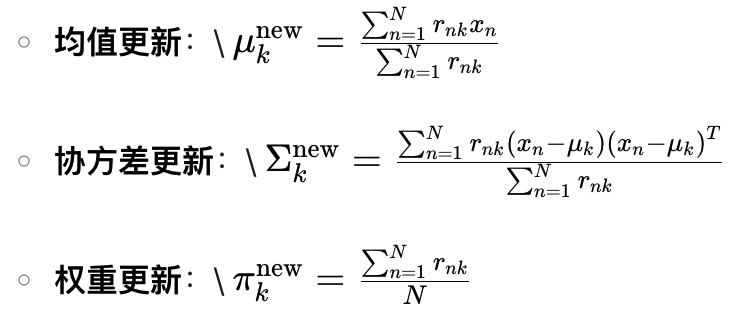
代码实现:
def _m_step(self, X, responsibilities):
N_k = responsibilities.sum(axis=1)
self.means_ = (responsibilities @ X) / N_k[:, np.newaxis] # 均值更新
for k in range(self.n_components):
diff = X - self.means_[k]
if self.covariance_type == 'full':
self.covariances_[k] = (responsibilities[k] * diff.T @ diff) / N_k[k]
elif self.covariance_type == 'diag':
self.covariances_[k] = np.diag(
(responsibilities[k] * np.sum(diff**2, axis=1)) / N_k[k]
)
self.weights_ = N_k / len(X) # 权重更新
三、参数初始化策略
-
K-means 预初始化
-
用 K-means 聚类结果作为 GMM 初始参数,提升收敛速度。
-
代码实现 :
-
def _initialize_params(self, X):
kmeans = KMeans(n_clusters=self.n_components).fit(X)
self.means_ = kmeans.cluster_centers_ # 用K-means结果初始化均值
# 协方差初始化(以full类型为例)
for k in range(self.n_components):
self.covariances_[k] = np.cov(X[kmeans.labels_ == k].T, bias=True)
四、协方差矩阵类型选择
| 类型 | 参数约束 | 适用场景 | 代码实现 |
|---|---|---|---|
| Full | 无约束 | 数据各维度相关性强 | covariance_type='full' |
| Diagonal | 非对角线元素为 0 | 数据各维度独立 | covariance_type='diag' |
| Spherical | 对角元素相等 | 数据各维度方差相同且独立 | covariance_type='spherical' |
五、模型评估与优化
1. 负对数似然(NLL)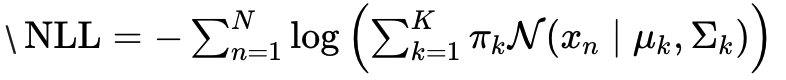
- 代码实现:
def _compute_nll(self, X, responsibilities):
return -np.sum(np.log(responsibilities.sum(axis=0)))
-
**贝叶斯信息准则(BIC) BIC = −2 ⋅ LL + 参数数量 log N
- 代码实现:
def _compute_bic(self, X):
n_params = self.n_components * (X.shape[1] + X.shape[1]*(X.shape[1]+1)/2 + 1)
return -2 * self.nll_[-1] + n_params * np.log(len(X))
六、实战扩展:高维数据处理
1. 降维预处理
- 使用 PCA 降低维度后训练 GMM:
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_high_dim)
model = GMM(n_components=3).fit(X_pca)
2. 客户分群
# 客户价值分群示例
from sklearn.datasets import load_iris
# 加载客户特征数据
X = load_iris().data[:, :2] # 简化为二维特征
model = GMM(n_components=3, covariance_type='diag').fit(X)
# 分群结果
segments = model.predict(X)
print("客户分群结果:", np.unique(segments, return_counts=True))
3. 异常检测
# 基于责任度的异常检测
probs = model.predict_proba(X)
threshold = 0.1 # 设置异常阈值
anomalies = np.where(probs.min(axis=1) < threshold)[0]
print(f"检测到{len(anomalies)}个异常样本")
4. 生成式建模
# 生成新样本
new_samples = np.zeros((100, 2))
for i in range(100):
k = np.random.choice(model.n_components, p=model.weights_)
new_samples[i] = np.random.multivariate_normal(
model.means_[k], model.covariances_[k]
)
性能优化建议
- 向量化运算:避免显式循环,使用 NumPy 矩阵运算加速
- 并行计算:利用
joblib实现 E 步和 M 步的并行化 - 稀疏矩阵优化:对于高维数据使用稀疏协方差表示
- 内存优化:使用生成器处理大规模数据
七、完整代码示例
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
import time
# =============================================
# 数据生成与预处理
# =============================================
def generate_data(n_samples=600, n_components=3, seed=42):
"""生成高斯混合数据(支持任意维度)"""
np.random.seed(seed)
means = np.array([
[1.2, 0.4],
[-4.4, 1.0],
[4.1, -0.3]
])
covs = np.array([
[[0.8, -0.4], [-0.4, 1.0]],
[[1.2, -0.8], [-0.8, 1.0]],
[[1.2, 0.6], [0.6, 3.0]]
])
weights = np.array([0.3, 0.2, 0.5])
data = []
for k in range(n_components):
component = np.random.multivariate_normal(
means[k], covs[k], int(n_samples/n_components)
)
data.append(component)
return np.vstack(data)
def preprocess_data(data, method='standardize'):
"""数据预处理"""
if method == 'standardize':
scaler = StandardScaler()
return scaler.fit_transform(data), scaler
elif method == 'normalize':
return (data - data.min()) / (data.max() - data.min()), None
else:
return data, None
# =============================================
# GMM核心实现
# =============================================
class GMM:
def __init__(self, n_components=3, covariance_type='full', max_iter=100,
tol=1e-6, random_state=None, verbose=False):
self.n_components = n_components
self.covariance_type = covariance_type
self.max_iter = max_iter
self.tol = tol
self.random_state = random_state
self.verbose = verbose
self.means_ = None
self.covariances_ = None
self.weights_ = None
self.bic_ = None
self.nll_ = []
# 初始化随机种子
if random_state is not None:
np.random.seed(random_state)
def _initialize_params(self, X):
"""参数初始化(支持K-means预初始化)"""
n_features = X.shape[1]
# K-means预初始化
kmeans = KMeans(n_clusters=self.n_components, n_init=10).fit(X)
self.means_ = kmeans.cluster_centers_
# 协方差初始化
self.covariances_ = np.zeros((self.n_components, n_features, n_features))
for k in range(self.n_components):
if self.covariance_type == 'full':
self.covariances_[k] = np.cov(X[kmeans.labels_ == k].T, bias=True)
elif self.covariance_type == 'diag':
self.covariances_[k] = np.diag(np.var(X[kmeans.labels_ == k], axis=0))
elif self.covariance_type == 'spherical':
self.covariances_[k] = np.eye(n_features) * np.var(X)
# 权重初始化
self.weights_ = np.bincount(kmeans.labels_) / len(X)
def _e_step(self, X):
"""E步:计算责任度"""
responsibilities = np.zeros((self.n_components, len(X)))
for k in range(self.n_components):
responsibilities[k] = self.weights_[k] * multivariate_normal.pdf(
X, mean=self.means_[k], cov=self.covariances_[k]
)
responsibilities /= responsibilities.sum(axis=0)
return responsibilities
def _m_step(self, X, responsibilities):
"""M步:更新参数"""
n_samples = len(X)
N_k = responsibilities.sum(axis=1)
# 更新均值
self.means_ = (responsibilities @ X) / N_k[:, np.newaxis]
# 更新协方差
for k in range(self.n_components):
diff = X - self.means_[k]
if self.covariance_type == 'full':
self.covariances_[k] = (responsibilities[k] * diff.T @ diff) / N_k[k]
elif self.covariance_type == 'diag':
self.covariances_[k] = np.diag(
(responsibilities[k] * np.sum(diff**2, axis=1)) / N_k[k]
)
elif self.covariance_type == 'spherical':
self.covariances_[k] = np.eye(X.shape[1]) * (
(responsibilities[k] * np.sum(diff**2, axis=1)) / (N_k[k] * X.shape[1])
)
# 更新权重
self.weights_ = N_k / n_samples
def _compute_nll(self, X, responsibilities):
"""计算负对数似然"""
return -np.sum(np.log(responsibilities.sum(axis=0)))
def fit(self, X):
"""训练GMM模型"""
self._initialize_params(X)
self.nll_.append(self._compute_nll(X, self._e_step(X)))
for iter in range(1, self.max_iter + 1):
# E步
responsibilities = self._e_step(X)
# M步
self._m_step(X, responsibilities)
# 计算NLL
current_nll = self._compute_nll(X, responsibilities)
self.nll_.append(current_nll)
# 检查收敛
if np.abs(current_nll - self.nll_[iter-1]) < self.tol:
if self.verbose:
print(f"Converged at iteration {iter}")
break
# 记录中间结果
if self.verbose and iter % 10 == 0:
print(f"Iteration {iter}: NLL = {current_nll:.4f}")
# 计算BIC
self.bic_ = self._compute_bic(X)
return self
def _compute_bic(self, X):
"""计算贝叶斯信息准则"""
n_samples = len(X)
n_features = X.shape[1]
n_params = self.n_components * (n_features + n_features*(n_features+1)/2 + 1)
return -2 * self.nll_[-1] + n_params * np.log(n_samples)
def predict_proba(self, X):
"""预测样本属于各成分的概率"""
responsibilities = self._e_step(X)
return responsibilities.T
def predict(self, X):
"""预测样本所属成分"""
return np.argmax(self.predict_proba(X), axis=1)
# =============================================
# 可视化与评估
# =============================================
def plot_gmm_results(X, model, title="GMM Results"):
"""可视化GMM训练结果"""
plt.figure(figsize=(12, 5))
# 数据点
plt.subplot(1, 2, 1)
plt.scatter(X[:, 0], X[:, 1], c=model.predict(X), cmap='tab10', alpha=0.6)
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
plt.title("Clustering Results")
# 对数似然曲线
plt.subplot(1, 2, 2)
plt.plot(range(len(model.nll_)), model.nll_, label='NLL')
plt.xlabel("Iteration")
plt.ylabel("Negative Log-Likelihood")
plt.title("Convergence Curve")
plt.legend()
plt.suptitle(title)
plt.tight_layout()
plt.show()
def evaluate_model(X, model):
"""评估模型性能"""
print(f"Number of Components: {model.n_components}")
print(f"BIC: {model.bic_:.2f}")
print(f"Silhouette Score: {silhouette_score(X, model.predict(X)):.4f}")
print(f"Final NLL: {model.nll_[-1]:.4f}")
# =============================================
# 主流程
# =============================================
if __name__ == "__main__":
# 生成数据
X = generate_data(n_samples=600, n_components=3)
# 预处理
X_processed, scaler = preprocess_data(X, method='standardize')
# 训练模型
model = GMM(
n_components=3,
covariance_type='full',
max_iter=200,
tol=1e-6,
random_state=42,
verbose=True
).fit(X_processed)
# 评估与可视化
evaluate_model(X_processed, model)
plot_gmm_results(X_processed, model)
# 成分分析
print("\nComponent Statistics:")
for k in range(model.n_components):
print(f"Component {k+1}:")
print(f" Weight: {model.weights_[k]:.4f}")
print(f" Mean: {model.means_[k].round(2)}")
print(f" Covariance:")
print(np.round(model.covariances_[k], 2))
print()
总结:
高斯混合模型通过概率密度建模实现复杂数据分布的灵活拟合,EM 算法的迭代优化是其核心驱动力。实际应用中需关注参数初始化、协方差类型选择和模型评估方法。结合可视化工具(如等高线图、似然曲线)可有效监控训练过程,提升模型解释性。未来可探索贝叶斯 GMM、变分推断等扩展方法,进一步优化模型性能。



















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











