







背景介绍

最近家里面的猫主子好像心情不太好,整体茶饭不思,就躺在沙发上睡觉,表情看起来也无精打采,一副生无可恋的样子。作为猫奴的我可着急了,心想小猫咪不会有心理问题了吧。也许是我们平时上班,留着小猫独自在家,孤独太久导致抑郁了。
为了解决这个问题,我打算利用自己的专业技能,亲手造个机器猫,在我们不在家的时候陪伴小猫咪,和它聊天。同时也作为机器人管家,管理家里面的各种智能家居电器,方便我们的日常生活。
我列举了一下机器猫的需求:
- 可以进行自由的语音对话
- 支持语音唤醒功能,不用的时候可以自己休眠省电
- 可以在家里面自由地移动
- 可以控制家里面的各种智能家电(空调/台灯等等)
话不多说,下面是初步的成果
手把手打造机器猫
总体设计
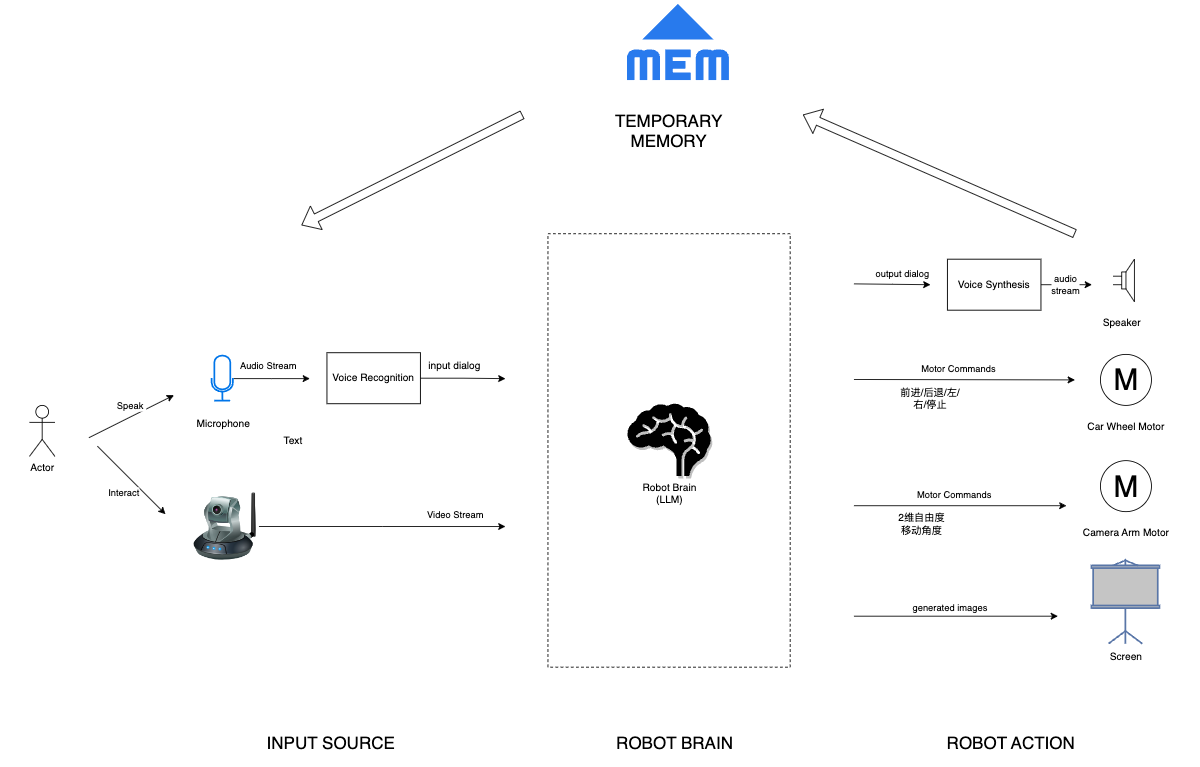
以上是机器猫的总体设计图
- 信息输入
-
- 机器猫可以支持语音/视频等各种模态的信息输入,并与大语言模型(Large Language Model, 以下简称LLM) 进行交互。对于语音输入,会提前通过语音识别转换为文字。
- 信息处理
-
- 大语言模型作为机器猫的大脑,承担最核心的逻辑推理能力,用于做自由对话,以及调度下游的各种硬件设备等等。
- 所有的对话内容/外部接口调用,都由大语言模型来自由发挥创作,不需要我们手动写各种调度逻辑,让它成为一只具备真正"灵魂“的猫猫。
- 信息输出
-
- 支持 文字转语音,方便直接进行语音对话。
- 支持将大模型的回复内容解析,并根据需要调度机器猫的轮子用于移动,也可以控制摄像头转向,甚至可以控制屏幕的显示(比如说显示机器猫的表情)等等。后续可以加入更多的环境交互能力。
- 记忆
-
- 支持将以往对话内容持久化,作为机器猫的记忆,便于后续聊天过程中进行参考。
硬件部分

在淘宝买了一个机器人小车,将其组装起来,包含以下部件
- 一个微型计算机模块,基于树莓派 4B型号,4GB内存版本,通过GPIO拓展板支持外接的各种设备
- 4个麦卡姆轮的发动机,便于机器人小车向各种方向移动
- 一个USB摄像头,摄像头放在支持2个自由度移动的舵机上,便于在不移动车身的情况,自由移动摄像头
- 2个红外避障器,用于告知车辆前方的障碍物信息
- 车身底部有蓄电源外接电源,电量比较耐用。另外附带一个电压表,用于显示电源电量情况。
- 另外我自己单独买了一个USB麦克风和扬声器
-
- 商家送的扬声器用的树莓派的3.5mm AV口,底噪大效果差。因为树莓派不带声卡,其板载的 3.5 mm 音频孔实际是通过 PWM 来实现音频输出的(通过算法让PWM信号变成模拟信号)。所以我直接换成了效果更好的USB声卡。
软件部分
关于硬件驱动这块(比如说车轮控制等),淘宝商家已经提供了完整的python工具包方便调用,我的工作主要是基于这些硬件能力,在上层搭建一个基于大语言模型的机器人系统。
代码地址如下: https://github.com/sundl123/RobotPet
目前代码托管在我的私人repo,后续计划整理代码之后再开源,如有需要可以单独联系我开通权限。
以下是各个子模块的设计方案
文本对话
基于时间成本的考虑,最开始没有计划自己训练和部署大语言模型(后续有可能考虑),而是使用现成可用的大语言模型接口,这样子能比较快地看到成果。当时考虑了多个算法提供商,包括百度文心一言,MiniMax, GPT4等,后来综合考虑选择了百度的文心一言,因为文心在国内市场占据领导地位,价格比较便宜,实测效果也还不错,另外网络访问方便,不需要像GPT4一样翻墙才能使用。最近文心开放了4.0最新版本的使用,大家可以试试。

关于LLM的SDK,我没有考虑使用类似Langchain的解决方案,因为之前看过langchain的官方文档,感觉他们为了适应各种场景,增加太多抽象封装了,这会导致后期维护起来比较麻烦,我需要的一种比较简单易用的方案。所幸文心提供了Ernie Bot SDK,便于比较方便地调用大语言模型的各种能力,包括文字对话,函数调用,文生图等等各方面,使用起来也比较简单方便。
以下是Ernie Bot SDK官方提供的文本对话的接口
import erniebot
# List supported models
models = erniebot.Model.list()
print(models)
# ernie-bot 文心一言模型(ernie-bot)
# ernie-bot-turbo 文心一言模型(ernie-bot-turbo)
# ernie-bot-4 文心一言模型(ernie-bot-4)
# ernie-bot-8k 文心一言模型(ernie-bot-8k)
# ernie-text-embedding 文心百中语义模型
# ernie-vilg-v2 文心一格模型
# Set authentication params
erniebot.api_type = 'aistudio'
erniebot.access_token = '<access-token-for-aistudio>'
# Create a chat completion
response = erniebot.ChatCompletion.create(model='ernie-bot', messages=[{'role': 'user', 'content': "你好,请介绍下你自己"}])
print(response.get_result())参考资料
函数调用
为了方便让LLM控制各种外接设备(比如说控制车轮前进后退),需要支持让LLM实现外部函数调用的能力。
原理介绍可以参考这篇文章: Chat Completion 模型的 Function Calling 功能实战。这个挺有趣的,因为和LLM交互的函数是通过自然语言写的,实现方式是通过自然语言的方式描述函数(比如说参数和功能),并要求LLM按照指定格式回答,我们通过解析LLM回复的自然语言结果,来判断LLM需要调用哪种函数以及使用什么参数,并将函数执行的结果返回给LLM,便于他基于函数执行结果进一步判断接下来的回复是什么。
Ernie Bot SDK也支持函数调用功能,详情参考这篇文章 函数调用(Function Calling),以下是我写的一个控制机器人移动的函数定义内容:
"control_robot_action": {
"implementation": control_robot_action,
"documentation": {
'name': 'control_robot_action',
'description': "控制机器人的移动",
'parameters': {
'type': 'object',
'properties': {
'action': {
'type': 'string',
'description': "动作类型",
'enum': [
'前进',
'后退',
'左转',
'右转',
'左移',
'右移',
'前左斜',
'后右斜',
'前右斜',
'后左斜',
],
},
},
'required': [
'action',
],
},
'responses': {
'type': 'object',
'properties': {
'is_successful': {
'type': 'boolean',
'description': "机器是否成功执行动作",
},
},
},
},
}文本语音互转

为了实现语音对话,需要引入 文本与语音互转的能力,因为之前使用了百度的文心一言,所以索性直接也使用了他们家的 语音技术。
- 语音转文字
-
- 使用PyAudio工具包从麦克风收音,调用百度语音接口进行语音识别,可以调用百度提供的AipSpeech工具包
- 注意: AipSpeech只支持 8kHz 或者 16kHz 的sample rate,如果麦克风的sample rate(比如说常见的是44.1kHz) 不一致,需要在识别前进行一下audio sample rate的转换。
- 文字转语音
-
- 调用AipSpeech的接口,进行语音合成
- 可以设置 合成语音的 音色(多种人物嗓音可选),速度,音量等
- 合成的audio流,可以使用PyAudio来进行播放
- 百度语音的效果算是还能凑合用,不过可选的声音风格有限,效果有时候也不太自然。如果想要更加自然的效果或者更多种类的声音风格,比如说希望带着情绪的语音风格,建议考虑下其他的平台,比如说OpenAI的Whisper API,或者 ElevenLabs 平台的接口
参考资料
- 语音技术-百度智能云
- AipSpeech工具包使用教程: 基于树莓派的语音识别和语音合成-腾讯云开发者社区-腾讯云
语音唤醒

需要支持语音唤醒的功能,这样子机器人在不使用的时候,可以处于待命状态,这样子便于省电。
- 支持关键词识别。类似于 iPhone的“Hey Siri”,或者小米音箱的 “小爱同学”
- 支持离线运行。因为语音唤醒需要一直检测,如果使用云厂商提供的接口不停stream到云端,费用顶不住
- 速度比较快。这样子确保比较实时地响应用户,提高用户体验。
通过调研发现有一种比较简单的方式,可以基于 snowboy ,来训练一个自己的关键词检测模型
参考以下教程,基本上可以实现出一个简单可用的语音唤醒功能。
- snowboy 官方github repo
- snowboy 模型训练教程
语音唤醒的效果跟各方面因素都有关系,算法鲁棒性,环境噪音,麦克风收音质量等等,如果大家觉得效果不满意,可以尝试下:
- 找个比较安静的环境
- 训练模型的时候,可以多采集一些数据,这样子效果更好
- 采集训练数据的麦克风,和实际测试的麦克风尽量使用相同的型号,因为不同的麦克风的收音效果略有不同,可能导致语音唤醒效果不佳
总的来说,我个人觉得snowboy的效果不算好。有时候不太灵敏,喊半天都不使唤;有时候又过于灵敏,稍微有点响声就触发了。具体原因后续还需要定位一下,不过snowboy官方已经不维护了,所以有问题也没有人支持,同时他们只开放编译好的库,不提供源码,所以问题定位可能有点困难。所以我后续考虑自己训练一个基于CNN的唤醒词检测模型,可以基于 speech_recognition 库,大家有如果其他的建议,也可以帮下忙。
智能家居控制

我希望机器人可以控制家里面的各种智能家居,包括智能窗帘,台灯,电视等等。我家的智能家居基本上都属于 小米智能家居生态,这样子的好处是,小米智能家居的协议是开放的(参考官方协议定义的Mi Home Binary Protocol ),通过了解各种智能家居开放的接口,可以比较方便地设计对应的工具来控制各种智能家居。所幸有个比较好用的工具,叫做 python-miio 已经封装了相关的小米智能家居控制功能。
参考下面列举的教程,大家可以比较方便写出控制智能家居的代码。首先需要使用 Xiaomi Cloud Tokens Extractor,获取到小米账号下所有的智能家居的访问ip和鉴权token,然后就可以用下面的命令控制各种设备了,以下是举例
# 控制打开窗帘
miiocli curtainmiot --ip 192.168.7.70 --token 45154e1bac2c02a1be9e681df set_motor_control open
# 控制关闭窗帘
miiocli curtainmiot --ip 192.168.7.70 --token 45154e1bac2c02a1be9e681df set_motor_control close
# 控制打开台灯
miiocli yeelight --ip 192.168.7.69 --token 444964de0bf155ef53ba8adsasdfa on
# 控制关闭台灯
miiocli yeelight --ip 192.168.7.69 --token 444964de0bf155ef53ba8adsasdfa off参考资料
- 一行代码操作米家智能家居设备 - 少数派
- python-miiot
后续的优化
现在的机器猫还是初步的版本,我后续期望给它在以下方面都加强一些,便于提高用户的使用体验。
一. 希望给他一副眼睛,看尽世界的万紫千红

现在的机器人是个瞎子,因为没有视觉的输入,我希望它能利用起来自己的摄像头来观察世界,并进行互动与反馈。
- 支持人脸识别
-
- 比如说,当我出现在他的面前,它能够说出具体我是谁,并聊我比较感兴趣的内容。它说话的内容,可以根据对话的对象不同而发生变化。
- 支持通用的视觉理解能力
-
- 比如说当我穿了一身帅气的衣服的时候,希望他根据画面中的我实际的穿搭进行点评,或者提示一些穿搭的建议。
二. 语音交流效果进一步提升

- 响应时间提升
-
- 问题描述: 目前每次对话都需要大概10s左右的延时,这里涉及到文字语音互转,云端大模型推理,函数调用等等
- 解决方案: 如果能够整个流程使用流式并行的处理方式,可以大大提升响应速度。
- 更灵敏的语音唤醒
-
- 问题描述: 基于snowboy的语音唤醒方案的效果不大鲁棒,有时候过于灵敏(被环境杂音触发),有时候过于呆笨(喊半天也无法唤醒),比较影响用户体验。
- 解决方案: 先检测下snowboy的使用方式是否可以优化,如果实现不行,应该有一些基于CNN的方案可以训练出效果更好的语音唤醒模型。
- 更及时的语音结束检测
-
- 问题描述: 目前倾听用户语音输入,因为无法及时检测用户是否停止了说话,需要等待默认的10s,这样子不够灵活,在用户对话比较简短的时候会增加系统端到端的响应延时。
- 解决方案: 调研下语音处理技术,应该有比较成熟的方案可以检测用户是否停止了说话。还想到一种比较简单的方案,比如说通过检测语音转文字API的流式接口是否长时间不输出文字(之前看过波士顿动力团队做一个机器狗 + ChatGPT的Demo,使用了类似的方案)。
三. 外观有点丑,不够拟人化

- 更萌一点的外观
-
- 可以考虑安装一个类似于与波士顿机器狗的身体,不过打扮成猫的外形(可以试着3D打印一些外壳进行装饰)。这样不仅可以适应更多的地形环境,外观也更加容易让人亲近。
- 更丰富的表情展现
-
- 可以加装一块小的屏幕,用于展示说话时候的嘴巴动作,以及机器猫的各种神态表情,比如说喜悦,失落,生气,撒娇等等。所有的这些表情的选择和展示,都由大模型来进行选择,不用人去干预。更有甚者,可以使用算法自动生成的表情视频进行展示,之前有看到一些paper可以基于静态的图片,生成各种动态的表情动作视频。
- 更有情绪化的语言风格
-
- 现在机器猫说话的语气始终是平和稳定的,但是我希望真正的机器人宠物是可以根据说话内容的不同,表现出不同的语气,比如说人高兴和低落的时候说话的语气是不一样的,这样子能够更容易引起人的共鸣。我有看到一些工具比如说 ElevenLabs , 可以克隆一个人的声音,并生成各种不同的情绪的语言风格,后续也可以尝试下。
- 同样的,使用何种情绪来说话,也全部用大模型来决定,不用人为控制。
未来的畅想
用大模型做一个真正实用的机器人宠物,还有很长的一段距离,不过这个创造的过程是很有趣的。能够看到机器人在自己的手下一步一步“活”过来,就像是创造一个生命一样,看着它从蹒跚学步,变成一个有着成熟心智的成年人。
我觉得 多模态大模型 + 机器人技术 是一个未来很有前景的方向,大模型的通用推理和逻辑能力使我们带来了机器人的"灵魂"与“大脑”, 而机器人技术使得大模型能够真正走进千家万户,触达每个人的日常生活,变成看得见摸得着的技术进步。我畅想中的机器人应该不是只局限于一个场景下(比如窝在一个固定工位上只会拧螺丝或者工件计数)的传统机器人,而是一个在各种场景下,通过与环境互动能够快速学习与适应的智能体。

这让我想起 1999年的科幻电影《机器人管家》里面的安德鲁,作为机器人,他把家务管理得井井有条,并且擅长学习,一点就通,成为了人类的得力助手;同时他又具备人类的情感,可以跟人类进行进行情感与思想的交流。我很期待未来能有这样子的机器人可以诞生。















 6346
6346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









