






 文章讨论了如何通过大型语言模型(LLM)和环形注意力技术在百万长度的视频和语言序列上构建世界模型,提出了一种新的训练方法和模型架构,展示了在长视频理解和超长上下文处理方面的显著进步。研究者还提供了开源模型和复现指南,强调了多模态数据处理和硬件需求的挑战。
文章讨论了如何通过大型语言模型(LLM)和环形注意力技术在百万长度的视频和语言序列上构建世界模型,提出了一种新的训练方法和模型架构,展示了在长视频理解和超长上下文处理方面的显著进步。研究者还提供了开源模型和复现指南,强调了多模态数据处理和硬件需求的挑战。

引言
最近,一篇论文在PaperWithCode网站引起了广泛关注,它探讨了当前热门的“世界模型”概念。随着Sora的流行,大众对世界模型的兴趣空前高涨。我们能否利用LLM(大型语言模型)来构建这样的模型呢?业内意见不一,例如,人工智能大牛 Yan Lecun 认为由于Transformer架构本身存在的缺陷和幻觉问题,它不太可能催生出真正的AGI(人工通用智能)。然而,这篇论文提出了另一种观点,它认为通过扩大上下文长度至100万个令牌,LLM也能够成为一个有效的世界模型。
我个人认为,所谓的“幻觉问题”并非不可克服的障碍。毕竟,人类最初认识世界的方式也是基于简单的模式识别,并非全然理性。通过不断的进化,我们才逐渐采用科学方法来客观认识世界。这一进化过程正是人类发展的轨迹,因此,如果大型模型沿着这条路径发展,那也是合情合理的。不过,Transformer架构可能确实需要深层次的变革,才能像人类一样进化。
如果你对这个话题充满好奇,那就跟我一起深入了解一下吧!
基础信息
- Title: World Model on Million-Length Video and Language with RingAttention (使用环形注意力的百万长度视频和语言世界模型)
- Authors: Hao Liu, Wilson Yan, Matei Zaharia, Pieter Abbeel
- Affiliation: UC Berkeley (加州大学伯克利分校)
- Keywords: language model, video understanding, multimodal, RingAttention
核心贡献
(a) 最大的上下文神经网络:论文在长视频和语言序列上训练了最大的上下文规模的Transformer,在困难检索任务和长视频理解中设定了新的基准。
(b) 克服视觉语言训练挑战的解决方案,包括使用掩码序列打包(masked sequence packing)混合不同序列长度、损失加权(loss weighting)以平衡语言和视觉,以及模型生成的长序列聊天QA数据集。
(c) 高度优化的实现,包括RingAttention、掩码序列打包和其他关键特征,用于在数百万长度的多模态序列上进行训练。
(d) 完全开源了7B参数模型家族,能够处理超过100万个标记的长文本文档(LWM-Text,LWM-Text-Chat)和视频(LWM,LWM-Chat)。
效果展示
虽然研究团队已经公开了完整的代码和模型,但由于其对硬件资源的要求较高,我们目前无法亲自进行复现。因此,接下来的展示将直接引用官方提供的演示示例。如果有同学拥有相应的硬件条件并成功复现了这些结果,非常欢迎你们分享自己的实践经验和成果。这不仅能帮助我们更深入地理解模型的实际表现,也能促进技术交流和知识共享。
大海捞针实验
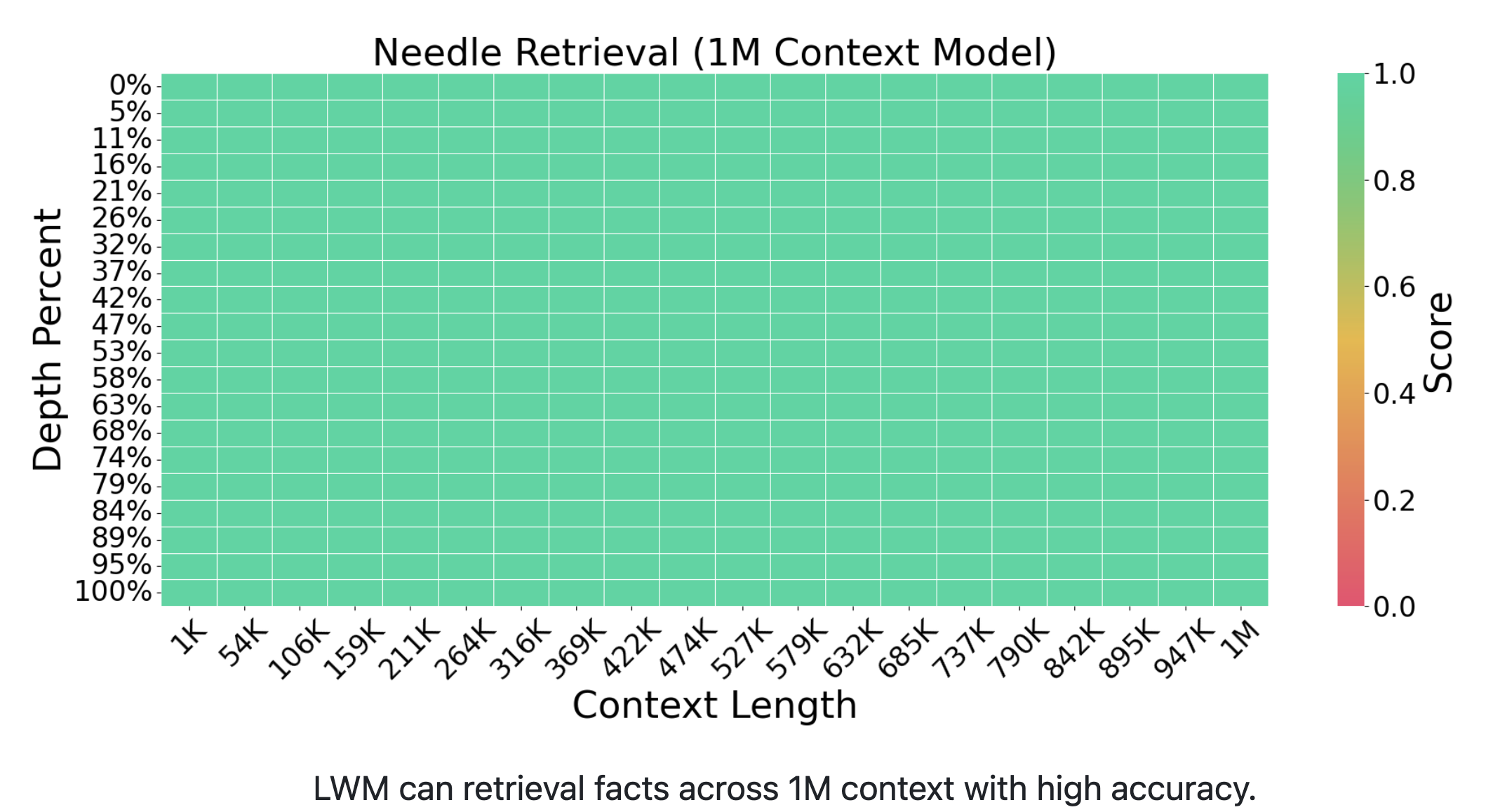
大海捞针实验是用来考验大模型在超长上下文窗口处理能力的重要测试,它像一面“照妖镜”,揭示了模型处理长序列数据的真实水平。为了验证模型上下文处理的有效性,研究团队首先展示了大海捞针实验的实际测试结果,而成果令人印象深刻。在1K至1M的上下文长度范围内,模型能够准确地从任意位置检索出相关信息,展现了卓越的性能。这一成就在当前处理超长上下文数据的领域中设定了新的最高标准,即行业内公认的最佳表现(State Of The Art, SOTA)。
基于一小时YouTube视频内容的问答展示

观察这个示例,我们可以发现模型能够基于一个由500多个短视频合成的1小时YouTube视频中的任何细节进行回答,这一效果实在令人赞叹。事实上,即便是人类,也难以记住一个视频的所有内容。这个演示主要旨在展现模型处理超长文本窗口的能力以及其对视频的理解能力。
依据官方提到的100万上下文窗口,模型能够同时处理数千帧视频画面。对于这1小时的视频,可能最终被抽样成数千帧的图像子集进行测试。传统方法由于上下文窗口限制,不论视频长度,通常只能将视频抽样成8帧数据输入模型,这显然会丢失大量信息。而通过这种新方法,模型能够支持数千帧图像数据的输入,显著提升了执行此类任务的精度和效果。
多模态交互能力
支持文本/图像/视频等多模态的数据输入与生成
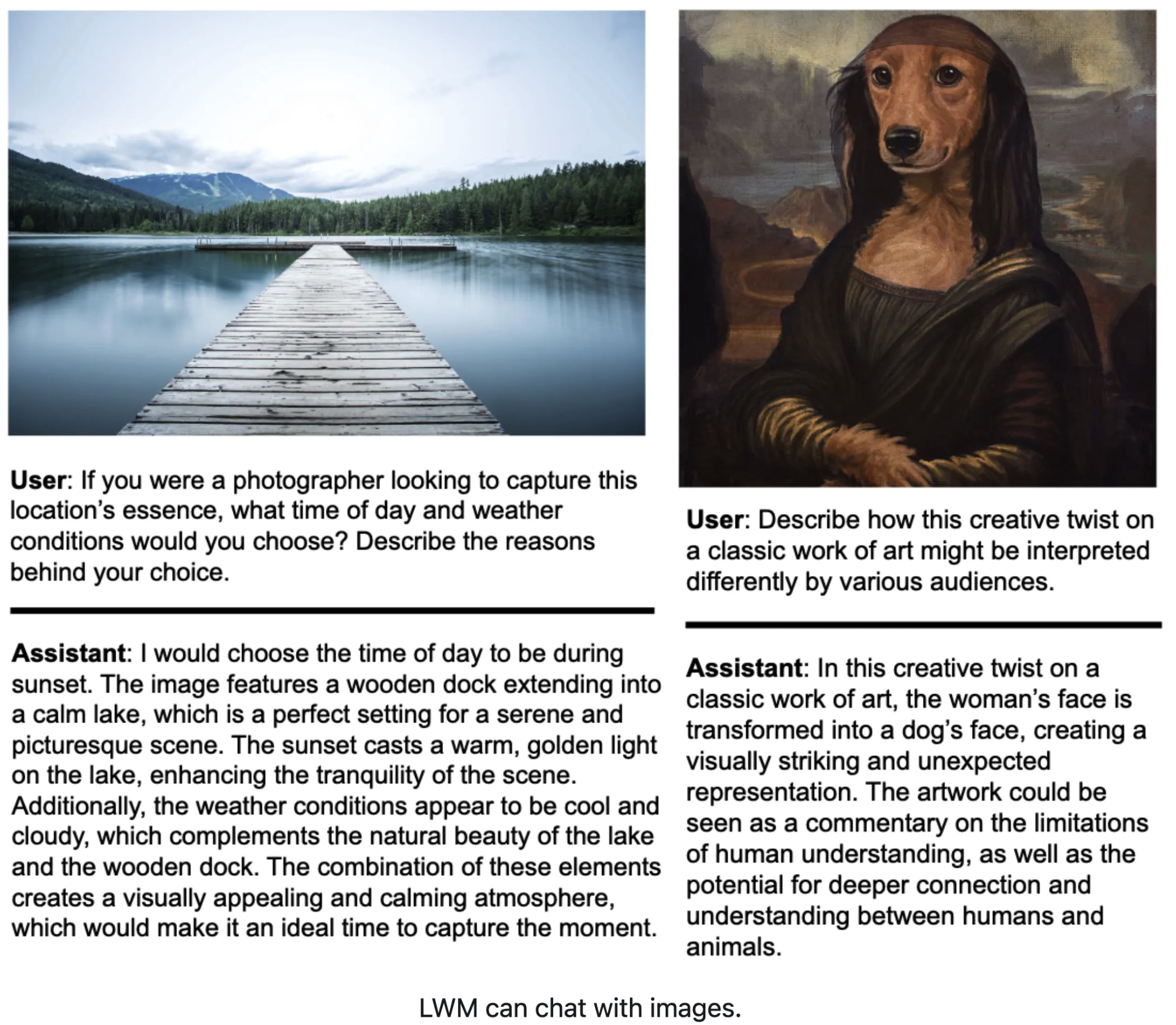
模型展现了其在多模态数据处理上的强大能力。特别是在进行图片对话时,它能够准确理解图片中的内容,甚至能够洞察到一张关于蒙娜丽莎的幽默网络图片中的笑点。

在图片和视频生成方面,模型也展示了令人满意的成果。虽然在视频生成的领域,与SORA相比,它仍有一段路要走,但已经表现出了其潜力和进步空间。
训练方法
这个模型的训练是基于Llama2 7B模型进行的,采取了分阶段的训练策略以优化性能:
- 第一阶段:纯文本训练 - 在这个阶段,训练专注于使用纯文本数据,目的是逐步增强模型处理长上下文的能力。通过这种方式,模型的上下文长度得到了显著提升。
- 第二阶段:引入多模态数据 - 经过文本训练打好基础后,训练进入第二阶段,开始加入图像、视频等多模态数据。这一步骤旨在扩展模型的功能,让它不仅能处理文本,还能支持多种模态的数据输入和输出,从而实现更全面的多模态理解和生成能力。

阶段一 增加上下文窗口大小
在这个阶段,模型的训练集中在如何有效地扩大上下文窗口:
- 采用RingAttention和FlashAttention:为了提高计算效率,尤其是在处理超大上下文时,模型采用了RingAttention和FlashAttention技术。这些方法对于优化长序列数据的处理至关重要。
- 逐步扩大上下文窗口:训练策略包括逐步扩大上下文窗口的尺寸,顺序为32k、128k、256k、512k、直至1M。这种渐进式的增长策略有助于降低训练成本。这种方法类似于人类的学习过程,从简单到复杂逐步递进,这样既节省了算力又提高了训练效率。正如逐步教育一个人从小学到大学,这种循序渐进的方式更利于知识的吸收和理解。
- 长上下文中的位置外推(Positional Extrapolation for Long Contexts):模型使用了旋转位置编码(RoPE)来处理位置信息。随着上下文窗口的扩大,模型逐渐调整RoPE的θ参数,以增强训练的稳定性。
- 上下文窗口大小的影响:通过对超大上下文进行训练,研究团队发现增大上下文窗口并不会削弱模型在处理较小上下文时的性能。这一发现为未来模型设计提供了新的洞见,强调了灵活处理不同规模上下文的重要性。
阶段二 多模态训练

在这一阶段,多模态数据的引入要求对模型架构进行相应的调整:
- 模型架构变更以适应多模态数据:
- 引入了VQGAN来编码图像和视频信息。具体来说,使用了预训练的VQGAN(来自aMUSEd项目),它将256×256的输入图像转换为16×16的离散令牌。视频则通过对每帧应用VQGAN并拼接得到的代码来进行令牌化。
- 引入了特定的标识符(如eof、eov)来标记不同的模态数据,例如,eof(end of frame)用于标记单帧图像的结束,和eov(end of vision)用于标记单张图片的末尾或者整个视频序列的最后一张图,而<vision></vision>标签则用于指明数据为视觉数据。
- 超长上下文的训练方法也应用于视频数据:借鉴了在纯文本训练中逐步增加上下文长度的方法,同样地,逐步增加视频数据的上下文长度。
- 结合Llama的文本数据进行视觉-语言训练:在视觉-语言训练中,为了保持模型的基础语言对话能力,会额外加入Llama的文本数据进行训练。
- 视图理解任务未达到领域最佳但仍有显著进步:尽管在视频理解或图像理解任务上,该模型还未能达到行业最佳(SOTA),但这篇论文的主要贡献在于显著提升了大型语言模型的上下文窗口大小,为未来的发展奠定了基础。
论文复现指南
官方已经公开了完整的论文代码和相关模型,对此感兴趣的研究者或学生可以尝试自行复现。遗憾的是,由于我自己的硬件资源限制,未能成功复现该研究——复现这一项目的硬件成本相当高昂,每小时需要数百美元,远超我的经济承受能力。如果有任何复现成功的朋友,非常欢迎你们分享经验和结果。
此外,值得一提的是,原团队的研究得到了Google云的算力赞助,因此所有训练都是在TPU上完成的,且代码都是针对Google JAX框架进行了优化。
根据官方提供的资料,推荐的硬件配置如下:
- 模型训练(Google TPU):
- LWM-Text Training Stages: v4-512
- LWM-Text-Chat Training Details: v4-512
- LWM / LWM-Chat Training Stages: v4-1024
- 模型推理(Google TPU):
- 对于1M上下文长度:v4-256
- 目前仅查到Google TPU v2-512规格的价格,每小时约为$211.20
- 模型推理(NVIDIA显卡):
- 32K上下文长度:1个80GB的A100,每小时$5.07
- 128K上下文长度:2个80GB的A100
- 256K上下文长度:4个80GB的A100
- 512K上下文长度:8个80GB的A100,每小时$40.55
希望这些信息能为有意复现该论文的研究者提供一定的参考。如果你们中有人成功复现并愿意分享结果,那将对整个学术社区大有裨益。
参考链接
- paperwithcode: World Model on Million-Length Video And Language With RingAttention | Papers With Code
- arxiv: https://arxiv.org/pdf/2402.08268v1.pdf
- github: GitHub - LargeWorldModel/LWM
- 硬件推荐: Memory requirements · Issue #7 · LargeWorldModel/LWM · GitHub















 816
816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









