







一. 前言
谁是Andrej Karpathy
最近,Andrej Karpathy 的技术分享引起了广泛关注,主题是字节对编码(Byte Pair Encoding)。Karpathy,作为李飞飞的学生,在从特斯拉的首席技术官职位辞职后,一直积极从事于AI科普教育。他不久前加入了OpenAI,随后又离开,期间发起了两个备受瞩目的开源项目:llama2.c 和 minbpe。特别是 minbpe 项目,近期引发了巨大的关注。Karpathy 的这些活动不仅展示了他对AI科普的热忱,也为技术社区带来了宝贵的资源和灵感。

关于 minbpe,该项目不仅公开了源代码,还提供了一系列的YouTube讲解视频。这些视频旨在帮助用户更深入地理解该技术。你不妨去YouTube上看看,观众们的反响极为热烈,评论区充满了赞誉。这些积极的反馈不仅证明了视频的教育价值,也反映了minbpe项目本身的创新性和实用性。
我对于Karpathy的评价
- Karpathy的热情不仅仅局限于技术探索,他对于自己的职业和追求有着明确的目标和理念。这种独立思考的精神让他选择离开OpenAI和Tesla,追寻自己的热情。
- 他对知识分享的热爱极大地帮助了众多人士,尤其是在当前AI技术飞速发展的时代。他致力于推动AI教育的普及和公平,让人们认识到大型语言模型(LLM)并非遥不可及的巨兽,而是可以被细分、理解和掌握的知识体系。
- Karpathy制作的教程品质出众,他遵循费曼的教学哲学——如果无法简明扼要地讲解一个概念,那就意味着还未完全掌握它。他的思维敏捷,能够将复杂的概念浅显易懂地传达给观众。
- 简而言之,我对他的敬佩之情溢于言表!他的工作不仅展示了他作为一个科技探索者和教育者的才华,也激励着我们每个人深入了解并参与到AI领域的学习和探索中。
本文的目标读者
- 那些渴望深入了解大型语言模型(LLM)实现细节的人。如果你对LLM的内部机制充满好奇,这篇文章将为你揭开其工作原理的神秘面纱。
- 对大模型 token 数量计算方式感到困惑的人。如果你曾经对于为何一个中文字符等同于2到3个token感到疑惑,这篇文章会帮你理清这一概念。我们将探讨token是如何在LLM中运作的,以及它们为何在不同语言和文本中表现出不同的数量。
- 纯粹热爱学习的人。如果你追求的是学习的乐趣,而非仅仅为了实用或职业发展,这篇文章同样适合你。我们鼓励所有充满好奇心和求知欲的读者,不论其背景或目标如何,都来探索这一迷人的主题。
推荐学习资源
minbpe源码
以下是Andrej Karpathy亲自制作的配套的学习视频,推荐搭配食用~
[中文字幕][Andrej Karpathy] Let's build the GPT Tokenizer
Andrej Karpathy 不仅仅是个AI领域的摇滚明星,他还是个慷慨分享的知识传播者。除了我们刚刚讨论的内容,他还创作了一系列其他精彩的教程,涵盖了 nanoGPT、Llama2.c 等多个项目。如果你对这些内容感兴趣,强烈推荐你深入探索和学习。
二. Tokenization
什么是 Tokenization
在Transformer架构的世界里,Tokenization是启程的第一步。想象一下,将人类的语言转化成机器能够理解的符号,这就是我们称之为 Tokenization 的过程。诚然,这一步骤可能让人感到有些头疼——连Andrej Karpathy本人似乎也不是很中意这一过程,并希望有朝一日能有更高效的方法来取代它。但就目前而言,Tokenization是我们的不二选择,因为它对LLM的性能有着不容忽视的影响。虽然这个过程可能让人有些讨厌,但绝对不是你想跳过的那块儿。
Tokenization 对于 LLM的影响
Tokenization对于LLM有很大的影响,以下列举一下常见的各种影响:
- 为什么LLM无法拼写单词?
- 为什么LLM无法执行超级简单的字符串处理任务,比如反转字符串?
- 为什么LLM在非英语语言(例如日语)方面表现更差?
- 为什么LLM在简单算术方面表现不佳?
- 为什么GPT-2在编写Python时会遇到比必要更多的麻烦?
- 为什么我的LLM在看到字符串""时突然停止运行?
- 我为什么会收到有关“Trailing Space”的奇怪警告?
- 如果我问LLM关于“SolidGoldMagikarp”,为什么LLM会出错?
- 为什么我应该更喜欢在LLM中使用YAML而不是JSON?
- 为什么LLM实际上并不是端到端的语言建模?
等看完今天的教程,你都会明白以上的所有问题
三. BPE 介绍
谈到Tokenization,就不得不提Byte Pair Encoding(BPE)——一种看似简单却极其强大的数据压缩技术。它最早出现在1994年的一篇名为“A New Algorithm for Data Compression”的文章中。现在,从Llama到GPT-4,再到Claude,几乎所有的Transformer模型都在使用BPE。这个技巧不仅仅是数据压缩的利器,更是让机器学会理解我们语言的关键步骤。所以,当你在探索这些令人兴奋的AI模型时,不妨深入了解一下BPE,它或许比你想象的要有趣得多。
为什么不直接输入Unicode 给 LLM?
有人可能好奇,为什么我们不能直接将Unicode编码作为输入提供给大型模型呢?
原因主要是Token数量限制:每个Transformer模型都有其能够处理的token上限。例如,目前的Claude模型最大context大小是100,000个token。如果不采用Byte Pair Encoding(BPE)等方法,我们很快就会耗尽所有的token配额,导致模型无法继续处理更长的文本。
此外,Unicode是一个不断发展的标准,每隔一段时间就会增加新的字符,这使得它不是一个固定的标准。这种不断变化的特性对模型的稳定性和持续使用也带来了挑战。
举例说明
BPE的根本目的是进行数据压缩,使得文本表示更为高效。
让我们以"Byte Pair Encoding"这个短语为例。
- 直接按字符计算,这是18个字母,若按ASCII编码,每个字符1个字节,总共需要18个字节。
- 但是如果我们应用BPE,可以将这个短语分为三个token:"Byte", "_Pair", "_Encoding"。在GPT-4的tokenization系统中,一共有100255个不同的token,每个token有一个唯一编号。如果单个token的编码占用4个字节(范围从0到4294967295),那么我们只需要3 * 4 = 12个字节来表示这个短语。从18个字节压缩到12个字节,节省了1/3的空间。

通过这个例子,我们可以看到,使用BPE不仅可以让模型处理更多的数据,还能以更高效的方式存储和处理信息。使用BPE压缩词表后,信息变得更加紧凑。这种紧凑性不仅提高了处理效率,还为模型留出了更多空间,使其能够进行更深入、更连贯的对话。这就是为什么在LLM中不直接使用Unicode编码,而是采用更为高效的tokenization策略的原因。
Tokenization可视化
推荐尝试这款用于Tokenization可视化的网络应用:https://tiktokenizer.vercel.app/
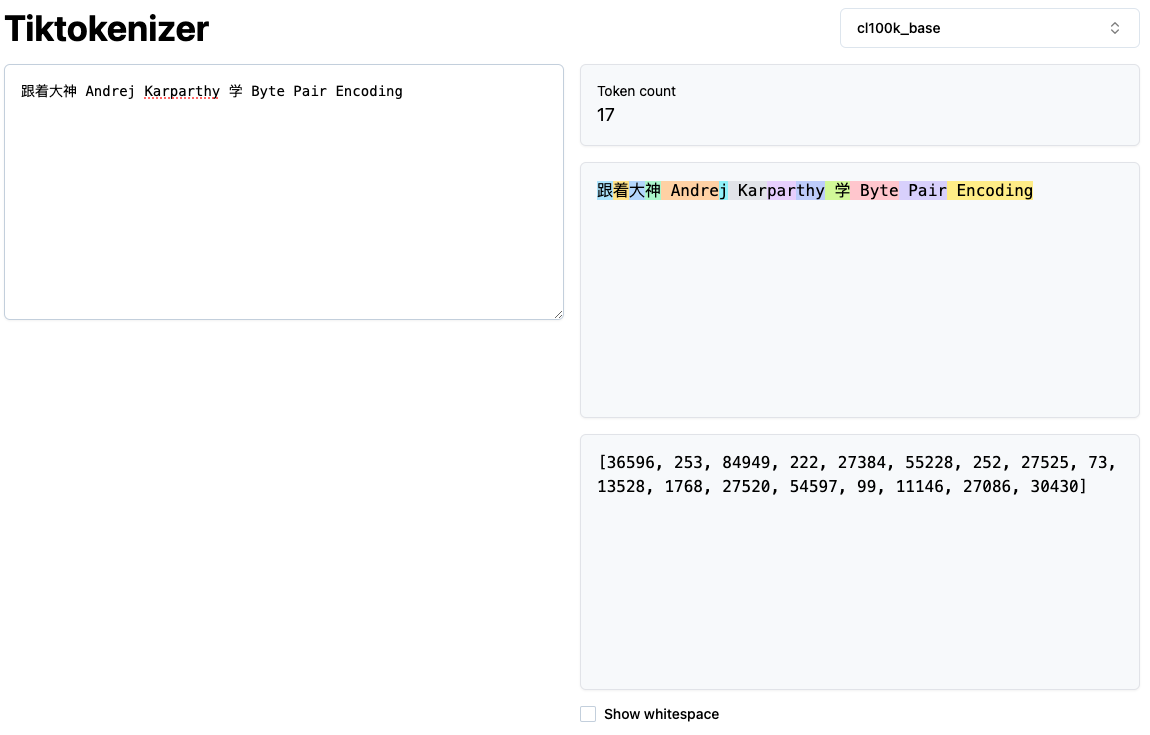
以上是一个使用GPT-4的BPE词汇表(cl100k_base)进行的示例,展示了如何将用户输入的字符串切分成不同的token,并以不同颜色加以标记。这个工具能直观展示Tokenization的过程,帮助理解如何将文本转化为机器可理解的格式。
四. BPE 实现
算法概述
- BPE 算法通过不断迭代,将文本中频繁出现的相邻字符对替换为一个新的未出现过的数据单元,直到达到预设的停止条件。
- 这个过程中,如果某个字符组合出现频率较高,就会被赋予一个唯一的Token来表示,从而实现数据压缩。
- 至于如何识别出现频率最高的字符对,BPE采用的是一种简单直接的方法:遍历文本,对所有可能的字符对进行频率统计。
举个简单的例子
以下是一个实际的例子
# 假设以下是需要编码的字符串
aaabdaaabac
# 我们发现 aa 这个字符对出现得最频繁,因为我们使用Z来代替aa,并替换原字符串中所有的 aa 为 X
ZabdZabac
Z=aa
# 接下来我们发现 ab 这个字符对出现的频率最高,因此我们使用 Y 来代替 ab, 并替换原字符串中所有的 ab 为 Y
ZYdZYac
Y=ab
Z=aa
# 接下来我们发现 ZY 这个字符对出现的频率最高,因此我们使用 X 代表 ZY,并替换原字符串中所有的 ZY 为 X
XdXac
X=ZY
Y=ab
Z=aa
# 现在我们发现无法找到频繁出现的字符对了,因此我们就此打住。
# 我们将字符串从 aaabdaaabac(共11个token) 压缩为 XdXac(共5个token)如何训练
以下是一个实际的代码例子,来自于Lei Mao的博客 Byte Pair Encoding - Lei Mao's Log Book,关于以下代码逻辑,他的博客有详细解释,文末有链接,我就不在这儿赘述了。
大家可以拷贝直接执行下,基于已有的文本训练一个自己的BPE词汇表。
import re, collections
def get_vocab(filename):
vocab = collections.defaultdict(int)
with open(filename, 'r', encoding='utf-8') as fhand:
for line in fhand:
words = line.strip().split()
for word in words:
vocab[' '.join(list(word)) + ' </w>'] += 1
return vocab
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
def get_tokens(vocab):
tokens = collections.defaultdict(int)
for word, freq in vocab.items():
word_tokens = word.split()
for token in word_tokens:
tokens[token] += freq
return tokens
# vocab = {'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
# Get free book from Gutenberg
# wget http://www.gutenberg.org/cache/epub/16457/pg16457.txt
vocab = get_vocab('pg16457.txt')
print('==========')
print('Tokens Before BPE')
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(tokens)))
print('==========')
num_merges = 1000
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print('Iter: {}'.format(i))
print('Best pair: {}'.format(best))
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(tokens)))
print('==========')如何编码 & 解码
同样的,我们提供一套Python代码,基于训练的词表来进行新的字符串的编码与解码
import re, collections
def get_vocab(filename):
vocab = collections.defaultdict(int)
with open(filename, 'r', encoding='utf-8') as fhand:
for line in fhand:
words = line.strip().split()
for word in words:
vocab[' '.join(list(word)) + ' </w>'] += 1
return vocab
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
def get_tokens_from_vocab(vocab):
tokens_frequencies = collections.defaultdict(int)
vocab_tokenization = {}
for word, freq in vocab.items():
word_tokens = word.split()
for token in word_tokens:
tokens_frequencies[token] += freq
vocab_tokenization[''.join(word_tokens)] = word_tokens
return tokens_frequencies, vocab_tokenization
def measure_token_length(token):
if token[-4:] == '</w>':
return len(token[:-4]) + 1
else:
return len(token)
def tokenize_word(string, sorted_tokens, unknown_token='</u>'):
if string == '':
return []
if sorted_tokens == []:
return [unknown_token]
string_tokens = []
for i in range(len(sorted_tokens)):
token = sorted_tokens[i]
token_reg = re.escape(token.replace('.', '[.]'))
matched_positions = [(m.start(0), m.end(0)) for m in re.finditer(token_reg, string)]
if len(matched_positions) == 0:
continue
substring_end_positions = [matched_position[0] for matched_position in matched_positions]
substring_start_position = 0
for substring_end_position in substring_end_positions:
substring = string[substring_start_position:substring_end_position]
string_tokens += tokenize_word(string=substring, sorted_tokens=sorted_tokens[i+1:], unknown_token=unknown_token)
string_tokens += [token]
substring_start_position = substring_end_position + len(token)
remaining_substring = string[substring_start_position:]
string_tokens += tokenize_word(string=remaining_substring, sorted_tokens=sorted_tokens[i+1:], unknown_token=unknown_token)
break
return string_tokens
# vocab = {'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
vocab = get_vocab('pg16457.txt')
print('==========')
print('Tokens Before BPE')
tokens_frequencies, vocab_tokenization = get_tokens_from_vocab(vocab)
print('All tokens: {}'.format(tokens_frequencies.keys()))
print('Number of tokens: {}'.format(len(tokens_frequencies.keys())))
print('==========')
num_merges = 10000
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print('Iter: {}'.format(i))
print('Best pair: {}'.format(best))
tokens_frequencies, vocab_tokenization = get_tokens_from_vocab(vocab)
print('All tokens: {}'.format(tokens_frequencies.keys()))
print('Number of tokens: {}'.format(len(tokens_frequencies.keys())))
print('==========')
# Let's check how tokenization will be for a known word
word_given_known = 'mountains</w>'
word_given_unknown = 'Ilikeeatingapples!</w>'
sorted_tokens_tuple = sorted(tokens_frequencies.items(), key=lambda item: (measure_token_length(item[0]), item[1]), reverse=True)
sorted_tokens = [token for (token, freq) in sorted_tokens_tuple]
print(sorted_tokens)
word_given = word_given_known
print('Tokenizing word: {}...'.format(word_given))
if word_given in vocab_tokenization:
print('Tokenization of the known word:')
print(vocab_tokenization[word_given])
print('Tokenization treating the known word as unknown:')
print(tokenize_word(string=word_given, sorted_tokens=sorted_tokens, unknown_token='</u>'))
else:
print('Tokenizating of the unknown word:')
print(tokenize_word(string=word_given, sorted_tokens=sorted_tokens, unknown_token='</u>'))
word_given = word_given_unknown
print('Tokenizing word: {}...'.format(word_given))
if word_given in vocab_tokenization:
print('Tokenization of the known word:')
print(vocab_tokenization[word_given])
print('Tokenization treating the known word as unknown:')
print(tokenize_word(string=word_given, sorted_tokens=sorted_tokens, unknown_token='</u>'))
else:
print('Tokenizating of the unknown word:')
print(tokenize_word(string=word_given, sorted_tokens=sorted_tokens, unknown_token='</u>'))GPT2的BPE实现细节
OpenAI开源了GPT2的源码,里面包含了BPE的一些实现细节
- OpenAI使用了正则表达式对于字符串来进行预处理,来确定某些特定的字符串不会被Merge.
GPT4_SPLIT_PATTERN = r"""'(?i:[sdmt]|ll|ve|re)|[^\r\n\p{L}\p{N}]?+\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]++[\r\n]*|\s*[\r\n]|\s+(?!\S)|\s+"""上面这个复杂的正则表达式,包括 GPT4 现在也在使用,只进行了稍微的调整。 大家可以去查询下具体的含义,并探究下为什么OpenAI 要这么做。
- Special Token
仔细看OpenAI的tiktoken库,我们会发现OpenAI支持在词汇表中插入一些special token,如下
ENDOFTEXT = "<|endoftext|>"
FIM_PREFIX = "<|fim_prefix|>"
FIM_MIDDLE = "<|fim_middle|>"
FIM_SUFFIX = "<|fim_suffix|>"
ENDOFPROMPT = "<|endofprompt|>"比如说上面的的 ENDOFTEXT, 这样的token的目的用来告诉模型,当前文本已经结束了,接下来的内容和之前的文本没有关系。大家可以研究下其他的 special token的目的是什么
五. BPE总结
Tokenization过程与LLM训练是独立的
- 实际上,我们可以独立进行tokenization的训练。并且相较于训练Transformer模型,BPE的训练成本相对较低。
- OpenAI已经开源了GPT-4的BPE模型。感兴趣的人可以通过以下链接下载并查看GPT-4的词汇表。这提供了一个深入理解GPT-4如何处理文本的机会
- https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken
回到最开始的问题
回到文章开头提出的问题,我们探讨了Tokenization对LLM的影响,并举了一些现象作为例子。下面,我们将解释其中几个现象,而对于其他问题,我们鼓励读者自行思考并参考Karpathy的教学视频寻找答案。
- 为什么LLM难以正确拼写单词?
LLM处理的是token而非单个字符。以“Hello”为例,虽然它包含5个字符['H', 'e', 'l', 'l', 'o'],但LLM视为一个整体token,因而难以辨识并拼写出内部的每个字符。
- 为什么LLM在处理非英语(如中文)文本时表现不佳?
一种可能的原因在于模型在训练过程中接触到的非英语数据较少。这种数据不足主要体现在两个方面:一是Transformer模型(不包括tokenization)本身在训练数据中缺乏非英语内容;二是在tokenization的训练过程中同样缺少非英文数据。例如,在GPT-2的BPE词表中,许多英文单词(如"Hello")只占用一个token,而一个中文字符可能相当于2至3个token。这是因为BPE的训练基于词组出现的频率,常见词组更可能被压缩成一个新的token,从而提高数据的压缩率。对于非英语数据,由于其在训练集中的稀缺性,其压缩率不佳,导致非英文文本消耗更多的token,进而减少了模型可用的context范围。
- 为什么说LLM并非真正的端到端语言模型?
由于LLM的输入是经过Tokenization处理的数据,而非原始字符串,因此LLM并不能算作完全的端到端语言建模。这个处理步骤在输入和模型之间引入了一个额外的转换层。
六. 参考资料
- minbpe github repo: GitHub - karpathy/minbpe: Minimal, clean code for the Byte Pair Encoding (BPE) algorithm commonly used in LLM tokenization.
- minbpe Youtube Video: https://www.youtube.com/watch?v=zduSFxRajkE
- 【[中文字幕][Andrej Karpathy] Let's build the GPT Tokenizer】 : [中文字幕][Andrej Karpathy] Let's build the GPT Tokenizer_哔哩哔哩_bilibili
- Andrey Karpathy Github Page: karpathy (Andrej) · GitHub
- Byte Pair Encoding: Byte Pair Encoding - Lei Mao's Log Book
- 理解NLP最重要的编码方式 — Byte Pair Encoding (BPE),这一篇就够了: 理解NLP最重要的编码方式 — Byte Pair Encoding (BPE),这一篇就够了 - 知乎
- WikiPedia: https://en.wikipedia.org/wiki/Byte_pair_encoding














 1886
1886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









