







贝叶斯学派的论点:
- 先验分布
+ 样本信息
后验分布
- 先验分布
- 样本信息
:样本服从参数为theta的(二项Bernulli)分布
- 后验分布
:更新theta的分布 这是人们更新了对theta的认知
theta是一个定值 theta是一个分布
样本是随机的,因此研究样本的分布 认为theta是随机的,因而研究参数的分布
X1,X2~N(theta,100)
生成过程
在pLSA中,我们假定文档是这样生成的:
你不停的重复扔“文档-主题”骰子和”主题-词项“骰子,重复N次(产生N个词),完成一篇文档,重复这产生一篇文档的方法M次,则完成M篇文档。
- 按照概率
选择一篇文档
- 选定文档
后,从主题分布中按照概率
选择一个隐含的主题类别
- 选定
后,从词分布中按照概率
选择一个词
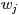
在LDA中,只是加入了一个dirichlet先验
反推过程
假定结束之后,那么如何根据已经产生好的文档反推其主题呢?
文档d和单词w自然是可被观察到的,但主题z却是隐藏的。如下图所示(
图中被涂色的d、w表示可观测变量,未被涂色的z表示未知的隐变量,N表示一篇文档中总共N个单词,M表示M篇文档):
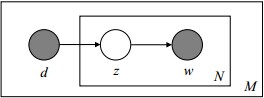
上图中,文档d和词w是我们得到的样本(样本随机,参数虽未知但固定,所以pLSA属于频率派思想。区别于下文要介绍的LDA中:样本固定,参数未知但不固定,是个随机变量,服从一定的分布,所以LDA属于贝叶斯派思想),可观测得到,所以
对于任意一篇文档,其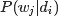 是已知的。
是已知的。
是已知的。
从而可以
根据
大量已知的文档-词项信息
,训练出文档-主题
和
主题-词项
,如下公式所示:
,训练出文档-主题
和
主题-词项
,如下公式所示:
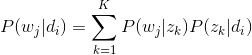
故得到文档中每个词的生成概率为:
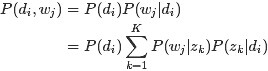
由于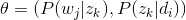
用什么方法进行估计呢,常用的参数估计方法有极大似然估计MLE、最大后验证估计MAP、贝叶斯估计等等。因为该待估计的参数中含有隐变量z,所以我们可以考虑EM算法。
pLSA和LDA在反推参数的不同
上面对比了pLSA跟LDA生成文档的不同过程,下面,咱们反过来,假定文档已经产生,反推其主题分布。那么,它们估计未知参数所采用的方法又有什么不同呢?
- 在pLSA中,我们使用EM算法去估计“主题-词项”矩阵Φ(由
转换得到)和“文档-主题”矩阵Θ(由
转换得到)这两个参数,而且这两参数都是个固定的值,只是未知,使用的思想其实就是极大似然估计MLE。
- 而在LDA中,估计Φ、Θ这两未知参数可以用变分(Variational inference)-EM算法,也可以用gibbs采样,前者的思想是最大后验估计MAP(MAP与MLE类似,都把未知参数当作固定的值),后者的思想是贝叶斯估计。贝叶斯估计是对MAP的扩展,但它与MAP有着本质的不同,即贝叶斯估计把待估计的参数看作是服从某种先验分布的随机变量。















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









