







之前看LDA,一直没搞懂到底作用是什么,公式推导了一大堆,dirichlet分布求了一堆倒数,却没有真正理解精髓在哪里。
最近手上遇到了一个文本分类的问题,采用普通的VSM模型的时候,运行的太慢,后来查找改进策略的时候,想起了LDA,因此把LDA重新拉回我的视线,也终于弄懂了到底是做什么的。
LDA本质是一种降维
为什么这么说,因为在我的文本分类问题中,文本共有290w个,根据词项得到的维度为90w个,这样一个巨大的矩阵【尤其是维度过多】扔到分类器里,肯定会有各种各样的问题【比如训练过慢,过拟合,等等】
因此,LDA的出现,能让VSM模型的列,由词项变成“主题”。这也就是主题模型的来历吧。
文档——主题矩阵
先看一个简单的:LSI 隐语意索引。基本方法是SVD矩阵分解
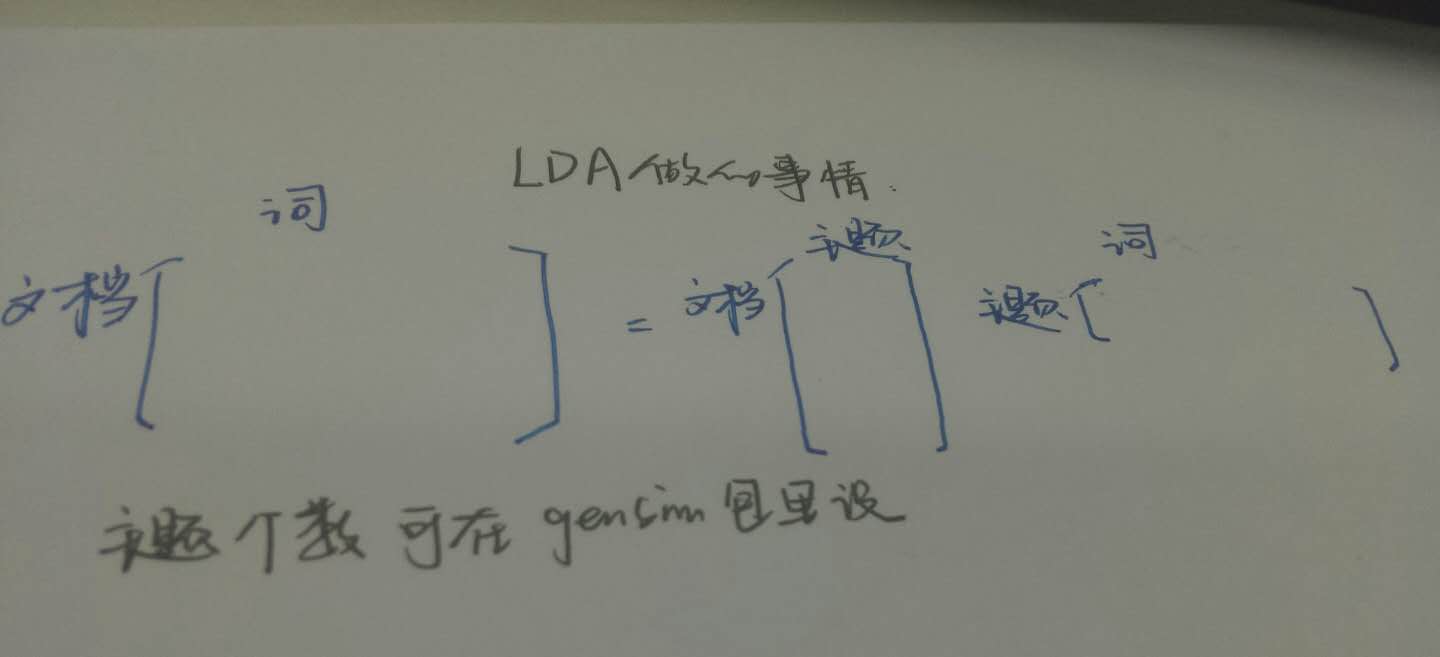
现在我们开始分析这两个矩阵各自长啥样:
文档——主题矩阵求出来之后,是这样的

在这里,我定义了200个主题,现只截图了前25个主题。
需要说明的是,这个是第一个文档的主题分布。我们可以看到,第一个样本的第6,第7个主题明显
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









