










总的来讲,一个完整的文本分类器主要由两个阶段,或者说两个部分组成:一是将文本向量化,将一个字符串转化成向量形式;二是传统的分类器,包括线性分类器,SVM, 神经网络分类器等等。
之前看的THUCTC的技术栈是使用 tf-idf 来进行文本向量化,使用卡方校验(chi-square)来降低向量维度,使用liblinear(采用线性核的svm) 来进行分类。而这里所述的文本分类器,使用lsi (latent semantic analysis, 隐性语义分析) 来进行向量化, 不需要降维, 因为可以直接指定维度, 然后使用线性核svm进行分类。lsi的部分主要使用gensim来进行, 分类主要由sklearn来完成。具体实现可见使用gensim和sklearn搭建一个文本分类器(二):代码和注释 这边主要叙述流程
1. 文档向量化
这部分的内容主要由gensim来完成。gensim库的一些基本用法在我之前的文章中已经有过介绍 点这里 这里就不再详述, 直接按照流程来写了。采用lsi进行向量化的流程主要有下面几步:
- 将各文档分词,从字符串转化为单词列表
- 统计各文档单词,生成词典(dictionary)
- 利用词典将文档转化成词频表示的向量,即指向量中的各值对应于词典中对应位置单词在该文档中出现次数
- 再进行进一步处理,将词频表示的向量转化成tf-idf表示的向量
- 由tf-idf表示的向量转化成lsi表示的向量
接下来按照上述流程来分别阐述
1.1 文档分词及预处理
分词有很多种方法,也有很多现成的库,这里仅介绍结巴的简单用法
import jieba
content = """面对当前挑战,我们应该落实2030年可持续发展议程,促进包容性发展"""
content = list(jieba.cut(content, cut_all=False))
print(content)
>>>['面对', '当前', '挑战', ',', '我们', '应该', '落实', '2030', '年', '可', '持续', '发展', '议程', ',', '促进', '包容性', '发展']注意上面的cut_all选项,如果cut_all=False, 则会列出最优的分割选项; 如果cut_all=True, 则会列出所有可能出现的词
content = list(jieba.cut(content, cut_all=True))
print(content)
>>>['面对', '当前', '挑战', '', '', '我们', '应该', '落实', '2030', '年', '可', '持续', '发展', '议程', '', '', '促进', '包容', '包容性', '容性', '发展']应该观察到,在分词后的直接结果中,有大量的无效项,例如空格,逗号等等。因此,一般在分词以后,还要进行预处理。例如去掉停用词(stop words, 指的是没什么意义的词,例如空格,逗号,句号,啊,呀, 等等), 去掉出现出现频率过低和过高的词等等。
我这一部分的程序是
def convert_doc_to_wordlist(str_doc,cut_all):
# 分词的主要方法
sent_list = str_doc.split('\n')
sent_list = map(rm_char, sent_list) # 去掉一些字符,例如\u3000
word_2dlist = [rm_tokens(jieba.cut(part,cut_all=cut_all)) for part in sent_list] # 分词
word_list = sum(word_2dlist,[])
return word_list
def rm_char(text):
text = re.sub('\u3000','',text)
return text
def get_stop_words(path='/home/multiangle/coding/python/PyNLP/static/stop_words.txt'):
# stop_words中,每行放一个停用词,以\n分隔
file = open(path,'rb').read().decode('utf8').split('\n')
return set(file)
def rm_tokens(words): # 去掉一些停用次和数字
words_list = list(words)
stop_words = get_stop_words()
for i in range(words_list.__len__())[::-1]:
if words_list[i] in stop_words: # 去除停用词
words_list.pop(i)
elif words_list[i].isdigit():
words_list.pop(i)
return words_list主程序是convert_doc_to_wordlist方法,拿到要分词的文本以后,首先去掉一些字符,例如\u3000等等。然后进行分词,再去掉其中的停用词和数字。 最后得到的单词,其顺序是打乱的,即单词间的相关信息已经丢失
1.2 统计单词,生成词典
一般来讲, 生成词典应该在将所有文档都分完词以后统一进行,不过对于规模特别大的数据,可以采用边分词边统计的方法。将文本分批读取分词,然后用之前生成的词典加入新内容的统计结果,如下面所示
from gensim import corpora,models
import jieba
import re
from pprint import pprint
import os
files = ["但是现在教育局非要治理这么一个情况",
"然而又不搞明白为什么这些词会出现"]
dictionary = corpora.Dictionary()
for file in files:
file = convert_doc_to_wordlist(file, cut_all=True)
dictionary.add_documents([file])
pprint(sorted(list(dictionary.items()),key=lambda x:x[0]))
>>>[(0, '教育'),
>>> (1, '治理'),
>>> (2, '教育局'),
>>> (3, '情况'),
>>> (4, '非要'),
>>> (5, '搞'),
>>> (6, '明白'),
>>> (7, '词')]对于已经存在的词典,可以使用dictionary.add_documents来往其中增加新的内容。当生成词典以后,会发现词典中的词太多了,达到了几十万的数量级, 因此需要去掉出现次数过少的单词,因为这些代词没什么代表性。
small_freq_ids = [tokenid for tokenid, docfreq in dictionary.dfs.items() if docfreq < 5 ]
dictionary.filter_tokens(small_freq_ids)
dictionary.compactify()1.3 将文档转化成按词频表示的向量
继续沿着之前的思路走,接下来要用dictionary把文档从词语列表转化成用词频表示的向量,也就是one-hot表示的向量。所谓one-hot,就是向量中的一维对应于词典中的一项。如果以词频表示,则向量中该维的值即为词典中该单词在文档中出现的频率。其实这个转化很简单,使用dictionray.doc2bow方法即可。
count = 0
bow = []
for file in files:
count += 1
if count%100 == 0 :
print('{c} at {t}'.format(c=count, t=time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())))
word_list = convert_doc_to_wordlist(file, cut_all=False)
word_bow = dictionary.doc2bow(word_list)
bow.append(word_bow)
pprint(bow)
>>>[[(1, 1), (2, 1), (4, 1)], [(5, 1), (6, 1)]]1.4 转化成tf-idf和lsi向量
之所以把这两部分放到一起,并不是因为这两者的计算方式或者说原理有多相似(实际上两者完全不同),而是说在gensim中计算这两者的调用方法比较类似,都需要调用gensim.models库。
tfidf_model = models.TfidfModel(corpus=corpus,
dictionary=dictionary)
corpus_tfidf = [tfidf_model[doc] for doc in corpus]
lsi_model = models.LsiModel(corpus = corpus_tfidf,
id2word = dictionary,
num_topics=50)
corpus_lsi = [lsi_model[doc] for doc in corpus]可以看到gensim的方法还是比较简洁的。
1.5 实践中的一些问题
由于之前阅读THUCTC源码的时候下载了THUCTCNews文档集,大概1G多点,已经帮你分好类,放在各个文件夹下面了。为了便于分析,各个环节的中间结果(词频向量,tfidf向量等)也都会存放到本地。为了便于以后标注,各个类的中间结果也是按类别存储的。
2. 分类问题
在将文本向量化以后,就可以采用传统的分类方法了, 例如线性分类法,线性核的svm,rbf核的svm,神经网络分类等方法。我在这个分类器中尝试了前3种,都可以由sklearn库来完成
2.1 从gensim到sklearn的格式转换
一个很尴尬的问题是,gensim中的corpus数据格式,sklearn是无法识别的。即gensim中对向量的表示形式与sklearn要求的不符。
在gensim中,向量是稀疏表示的。例如[(0,5),(6,3)] 意思就是说,该向量的第0个元素值为5,第6个元素值为3,其他为0.但是这种表示方式sklearn是无法识别的。sklearn的输入一般是与numpy或者scipy配套的。如果是密集矩阵,就需要输入numpy.array格式的; 如果是稀疏矩阵,则需要输入scipy.sparse.csr_matrix.由于后者可以转化成前者,而且gensim中向量本身就是稀疏表示,所以这边只讲如何将gensim中的corpus格式转化成csr_matrix.
去scipy的官网去找相关文档,可以看到csr_matrix的构造有如下几种方法。
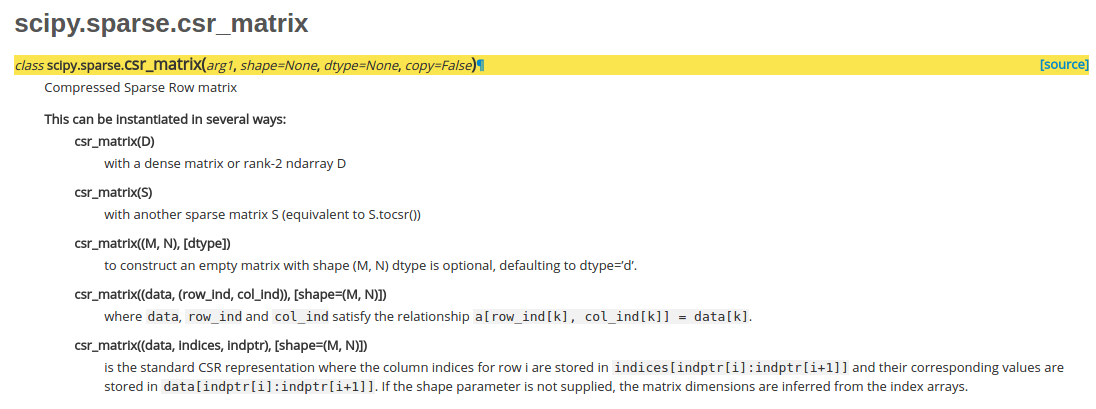
第一种是由现有的密集矩阵来构建稀疏矩阵,第二种不是很清楚,第三种构建一个空矩阵。第四种和第五种符合我们的要求。其中第四种最为直观,构建三个数组,分别存储每个元素的行,列和数值即可。
官网给出的示例代码如下,还是比较直观的。
row = np.array([0, 0, 1, 2, 2, 2])
col = np.array([0, 2, 2, 0, 1, 2])
data = np.array([1, 2, 3, 4, 5, 6])
print(csr_matrix((data, (row, col)), shape=(3, 3)).toarray())
>>>array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]])依样画葫芦,gensim转化到csr_matrix的程序可以写成
data = []
rows = []
cols = []
line_count = 0
for line in lsi_corpus_total: # lsi_corpus_total 是之前由gensim生成的lsi向量
for elem in line:
rows.append(line_count)
cols.append(elem[0])
data.append(elem[1])
line_count += 1
lsi_sparse_matrix = csr_matrix((data,(rows,cols))) # 稀疏向量
lsi_matrix = lsi_sparse_matrix.toarray() # 密集向量在将所有数据集都转化成sklearn可用的格式以后,还要将其分成训练集和检验集,比例大概在8:2.下面的代码就是关于训练集和检验集的生成的
data = []
rows = []
cols = []
line_count = 0
for line in lsi_corpus_total:
for elem in line:
rows.append(line_count)
cols.append(elem[0])
data.append(elem[1])
line_count += 1
lsi_matrix = csr_matrix((data,(rows,cols))).toarray()
rarray=np.random.random(size=line_count)
train_set = []
train_tag = []
test_set = []
test_tag = []
for i in range(line_count):
if rarray[i]<0.8:
train_set.append(lsi_matrix[i,:])
train_tag.append(tag_list[i])
else:
test_set.append(lsi_matrix[i,:])
test_tag.append(tag_list[i])2.2 线性判别分析
sklearn中,可以使用sklearn.discriminant_analysis.LinearDiscriminantAnalysis来进行线性分类。
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis(solver="svd", store_covariance=True)
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
Y = np.array([1, 1, 2, 2])
lda_res = lda.fit(X, Y)
print(lda_res.predict([[-0.8, -1]]))在上面的例子中,X代表了训练集。上面的X是一个4*2的矩阵,代表训练集中含有4各样本,每个样本的维度是2维。而Y代表的是训练集中各样本所期望的分类结果。回到文本分类的任务,易知上面代码的X对应于train_set, 而Y对应于train_tag
lda = LinearDiscriminantAnalysis(solver="svd", store_covariance=True)
lda_res = lda.fit(train_set, train_tag)
train_pred = lda_res.predict(train_set) # 训练集的预测结果
test_pred = lda_res.predict(test_set) # 检验集的预测结果lda_res即是得到的lda模型。 train_pred, test_pred 分别是训练集和检验集根据得到的lda模型获得的预测结果。
| 实验批次 | 向量化方法 | 向量长度 | 分类方法 | 训练集错误率 | 检验集错误率 |
|---|---|---|---|---|---|
| 1 | LSI | 50 | 线性判别 | 16.78% | 17.18% |
| 2 | LSI | 100 | 线性判别 | 14.10% | 14.25% |
| 3 | LSI | 200 | 线性判别 | 11.74% | 11.73% |
| 4 | LSI | 400 | 线性判别 | 10.50% | 10.93% |
2.3 SVM分类
总的来说,使用SVM与上面LDA的使用方法比较类似。使用sklearn.svm类可以完成。不过与lda相比,svm可以接受稀疏矩阵作为输入,这是个好消息。
# clf = svm.SVC() # 使用RBF核
clf = svm.LinearSVC() # 使用线性核
clf_res = clf.fit(train_set,train_tag)
train_pred = clf_res.predict(train_set)
test_pred = clf_res.predict(test_set)可以使用RBF核,也可以使用线性核。不过要注意,RBF核在数据集不太充足的情况下有很好的结果,但是当数据量很大是就不太明显,而且运行速度非常非常非常的慢! 所以我推荐使用线性核,运算速度快,而且效果比线性判别稍好一些
| 实验批次 | 向量化方法 | 向量长度 | 分类方法 | 训练集错误率 | 检验集错误率 |
|---|---|---|---|---|---|
| 5 | LSI | 50 | svm_linear | 12.31% | 12.52% |
| 6 | LSI | 100 | svm_linear | 10.13% | 10.20% |
| 7 | LSI | 200 | svm_linear | 8.75% | 8.98% |
| 8 | LSI | 400 | svm_linear | 7.70% | 7.89% |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









