







背景
随着数字化建设的持续深入,企业的业务规模迎来了高速发展,其数据规模也呈现爆炸式增长,如果继续使用传统解决方案,将所有数据存储在一个表中,对数据的查询和维护效率将是一个巨大的挑战,在这个背景下,表分区技术应运而生。
分区的其核心思想是将数据按照某个特定的标准分成多个物理块,每个物理块即为一个分区,从而使数据的存储和管理更加高效,可帮助我们我们实现稳定的存储增长、高性能和易维护。
优势
- 提升查询性能: 通过将数据分成多个分区,查询只需要访问特定分区的数据,避免扫描全表,减少磁盘I/O,从而加速查询操作,降低响应时间。
- 提升运维便利: 分区使得数据维护操作更加精确,例如我们按年分区,要删除指定年份的数据,无需使用性能开销极大的 DELETE FROM … WHERE year=2001,而是直接使用 DROP TABLE table_partition_2001来快速删除分区数据(几乎无开销)。
- 提升可用性和扩展性:表分区允许根据业务需求进行定制,例如按时间、业务部门等进行分区,单个分区出现故障,其他分区数据仍可用,且修复成本更低;同时避免单表的无限增长而导致性能下降,为系统的可扩展性提供了更好的基础。
何时分区
在决定是否对表进行分区时,需要综合考虑以下几个因素,以确保分区对系统性能和数据管理带来实际的好处:
- 查询模式相对固定:例如经常按业务部门查询,可将其作为分区键以最大限度地减少查询所需扫描的数据规模,例如对超大数据量的表(如 500 GB 以上,非绝对标准)收益较为明显,可明显地降低查询耗时,提升查询效率。
- 数据按时间有序:例如日志数据,使用时间作为分区键可以使查询按时间范围过滤更加高效,同时方便对访问量极低的旧数据进行管理和归档。
设计表分区策略
设计适当的表分区策略是确保分区表性能最大化的关键一步,以下是一些步骤和考虑因素,可帮助您制定有效的分区策略:
- 分析查询需求:分析查询需求,重点关注经常被查询的数据的过滤条件,以选择适当的分区键,使得满足这些过滤条件的数据能够集中在同一分区中,从而优化查询性能。
- 确认数据类型:推荐使用 STRING 或时间类型的列作为分区键,通常可以帮助在数据均衡和分区数量上取得较好的平衡。
- 权衡分区规模:常规情况下,单个分区的数据量控制在 500GB 内,如果集群的 CPU 核数较多,可适当提升,此外,我们还需要关注数据的增长趋势,例如数据按时间增长,时间则是一个优秀的分区键,查询按时间范围过滤时会更高效。
- 选择分区策略:ArgoDB 支持范围分区和单值分区:
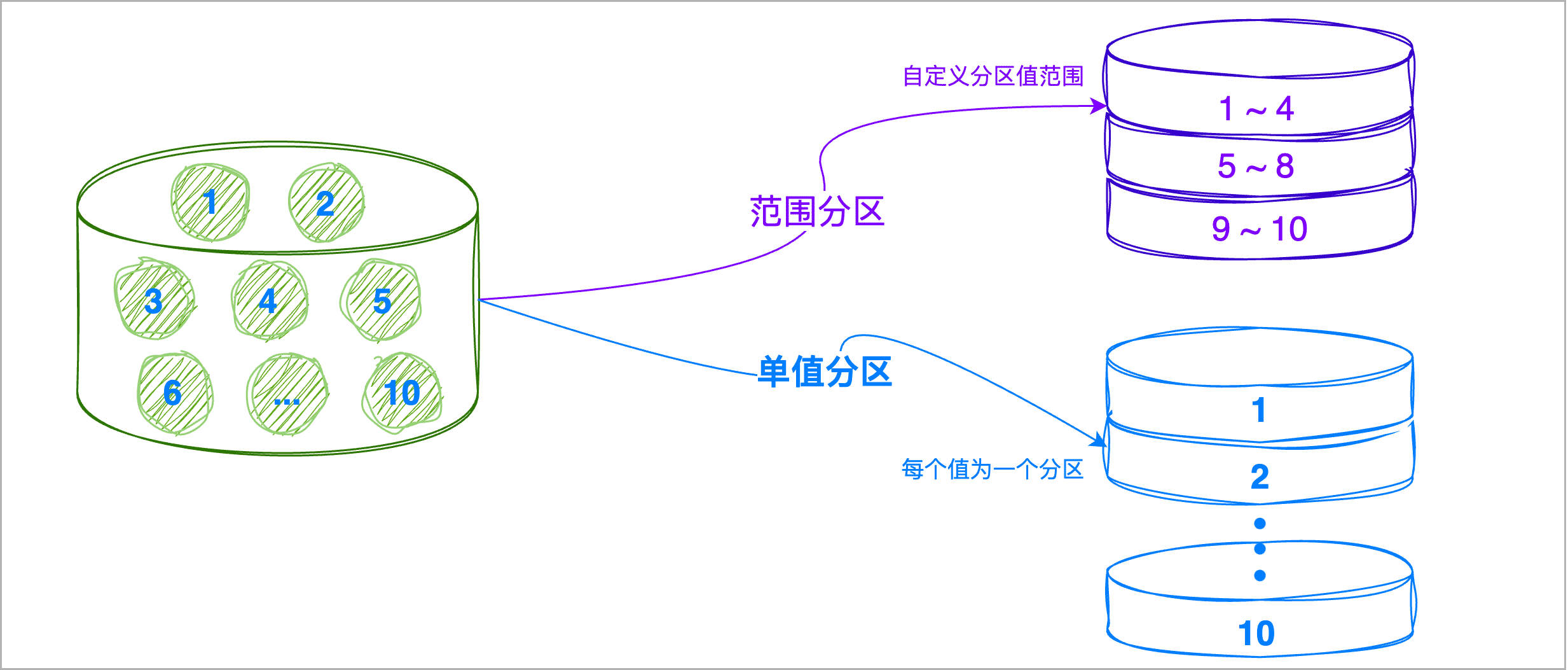
| 分区类型 | 说明 |
|---|---|
| 范围分区 | 按照分区键的值范围来划分分区,执行分区时可基于列值分布均衡度和查询需求来自由划分范围,可避免分区间的数据规模差距过大,提升查询效率。 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1223
1223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









