




 本文介绍了机器学习中常用的梯度下降优化器,包括SGD、SGD+Momentum、NAG、Adagrad、RMSProp和Adam。每种优化器的特点和工作原理被详细阐述,帮助理解如何通过优化策略提高模型训练效率。
本文介绍了机器学习中常用的梯度下降优化器,包括SGD、SGD+Momentum、NAG、Adagrad、RMSProp和Adam。每种优化器的特点和工作原理被详细阐述,帮助理解如何通过优化策略提高模型训练效率。
前言
梯度下降算法是机器学习中使用非常广泛的优化算法,梯度可以理解成山坡上某一点上升最快的方向,它的反方向就是下降最快的方向。要想下山最快,那么就要沿着梯度的反方向走,最终到达山底(全局最优点)。梯度下降优化器就是为了找到最快的下山策略。目前最常用的优化器有SGD、SGD+momentum、NAG、adagrad,Adam等。
1、SGD
随机梯度下降算法通常还有三种不同的应用方式,它们分别是SGD、Batch-SGD、Mini-Batch SGD
a.SGD是最基本的随机梯度下降,它是指每次参数更新只使用一个样本,这样可能导致更新较慢;
b.Batch-SGD是批随机梯度下降,它是指每次参数更新使用所有样本,即把所有样本都代入计算一遍,然后取它们的参数更新均值,来对参数进行一次性更新,这种更新方式较为粗糙;
c.Mini-Batch-SGD是小批量随机梯度下降,它是指每次参数更新使用一小批样本,这批样本的数量通常可以采取trial-and-error的方法来确定,这种方法被证明可以有效加快训练速度。
SGD算法是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。(划个重点:每次迭代使用一组样本。)
为什么叫随机梯度下降算法呢?这里的随机是指每次迭代过程中,样本都要被随机打乱。
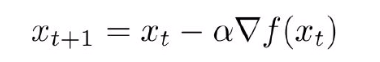
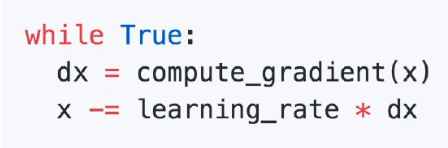
缺点:SGD算法每次只对一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4642
4642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









