







一、什么是梯度?
关于梯度的引入,可以分为四个概念:
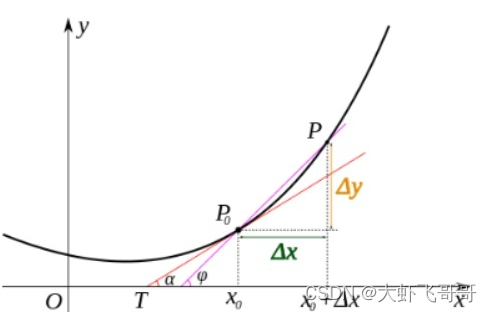
1、导数: 当函数定义域和取值都在实数域中的时候,导数可以表示函数曲线上的切线斜率。
2、偏导数 : 对于多元函数一个多变量的函数的偏导数,是关于其中一个变量的导数,而保持其他
变量恒定。
3、方向导数:函数在某一点上无数个切线的斜率。
举例: 定义在曲面 z = f(x, y) , 平面上一点 P(a,b) 以及单位向量 u =(cosθ,sinθ)。从点 P(a, b, f(a,b)) 出发,沿 u =(cosθ, sinθ) 方向走 t 单位长度后,函数值 z 为 F(t) = f(a+tcosθ, b+tsinθ),求导数:
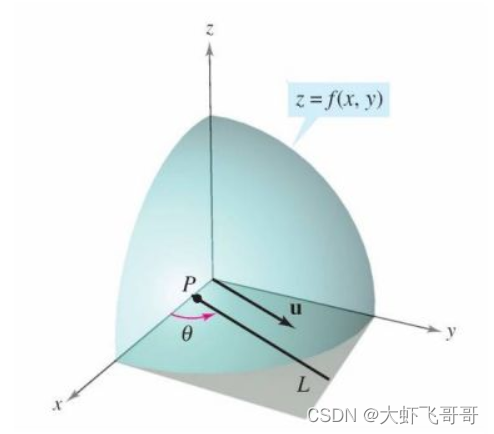
则点 P(a, b) 处 u = (cosθ, sinθ) 方向的方向导数为:
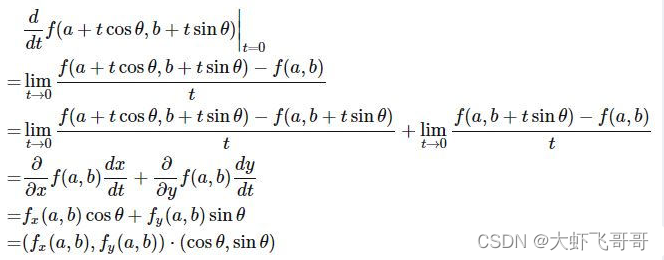
结论: 任意方向的方向导数为偏导数的线性组合,系数为该方向的单位向量。
4、梯度:表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
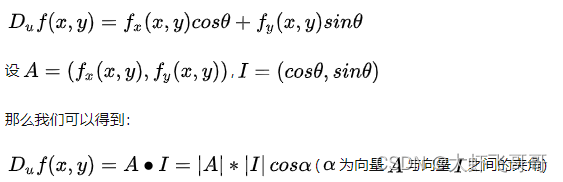
如果想要使方向导数取最大值,很明显 A 与 I 之间的夹角应该为 0。也就是向量 I (这个方向是一直在变,在寻找一个函数变化最快的方向)与向量 A(这个方向当点固定下来的时候,它就是固定的)平行的时候。
即: 偏导数构成的向量为梯度。
二、梯度下降介绍
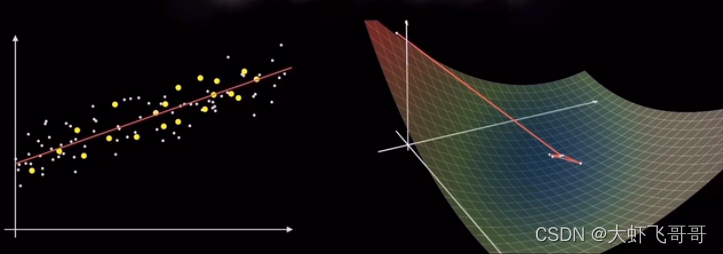
有这样一个数据集,很容易看出,这些数据是线性的,因此可以使用线性回归来拟合。,
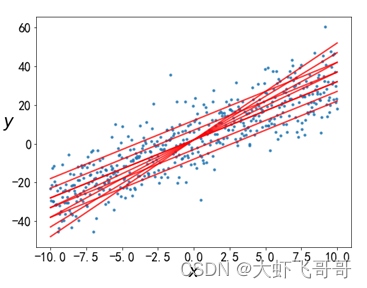
预测函数:可以用如下回归方程来表示模型:𝑓 ( 𝑥 ) = 𝑤 𝑥 + 𝑏 即:预测函数。
代价函数: 在图中画出几条通过样本集的直线,可以看到通过样本集的直线有无数条,每一条都由 𝑤 和 𝑏 确定。我们的任务就是找到那条最符合数据集的直线,也就是求得最优的 𝑤 和 𝑏 。如何实现呢?
首先,需要量化数据与模型的偏离程度,通过使用均方误差来评估:
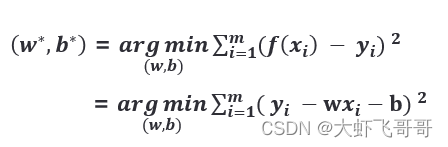
即:代价函数。
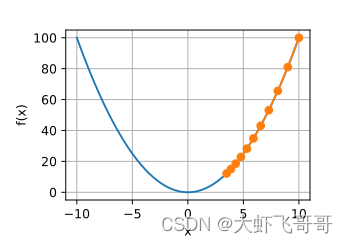
代价函数的图像是一个抛物线,如下图所示, 𝑤 和 𝑏 取不同的值,对应图像上不同的点,将样本的拟合过程映射到了一个函数图像上:
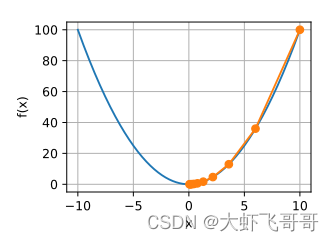
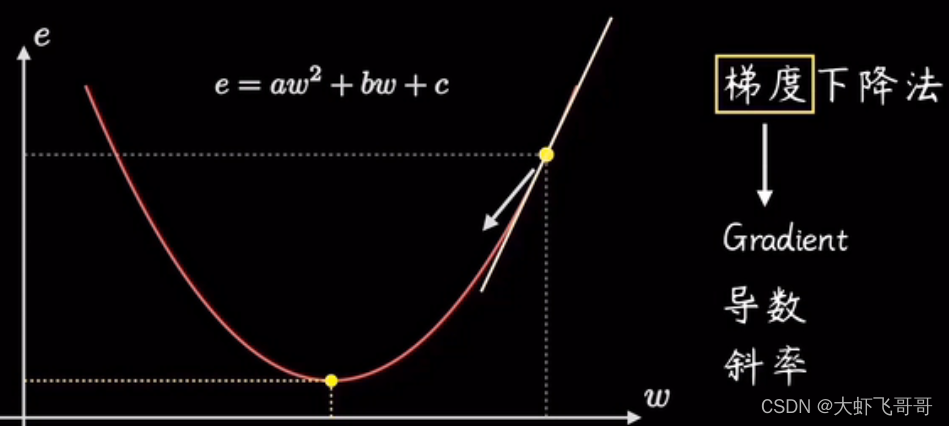
梯度计算: 上述代价函数比较简单,可以使用数学公式求解。而实际过程中,代价函数很复杂,不是简单的抛物线,因此不能使用计算求解,而是使用梯度下降求解。有了代价函数图像,我们该怎么寻找最优点呢?机器学习目标是拟合出最接近训练数据分别的直线。也就是找到是误差代价最小的参数 𝑤 和 𝑏 ,梯度下降就是为了寻找此参数。
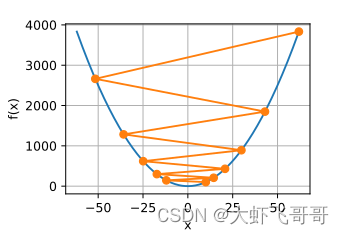
选择项陡峭程度最大的方向走, 就能更快达到最低点,这个陡峭程度就是梯度,即抛物线在该点的斜率。
学习率: 确定好前进方向后,每一步我们走多长呢? 用步长乘以梯度,得到当前位置下降的距离。如果使用的学习率太小,将导致x xx的更新非常缓慢,需要更多的迭代。当使用过高的学习率,x 的迭代不能保证降低 f(x) 的值, x 超出了最优解并逐渐发散。
梯度下降总结如下:
1、定义代价函数
2、选择起始点
3、计算梯度
4、按学习率前进
5、重复 3-4 过程
三、梯度下降分类
训练数据有很多,我们每次使用多少数据进行计算梯度呢?
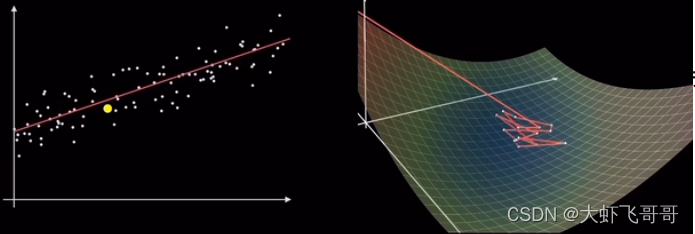
批量梯度下降BGD: 使用全部的样本进行计算。 这种方法每更新一次参数,都要把数据集里的所有样本计算一遍,计算量大,计算速度慢,不支持在线学习。
随机梯度下降SGD: 随机选择一个样本点。可以极大地减少计算量,提高计算效率,它存在着一定的不确定性,因此收敛速率比批梯度下降得更慢。
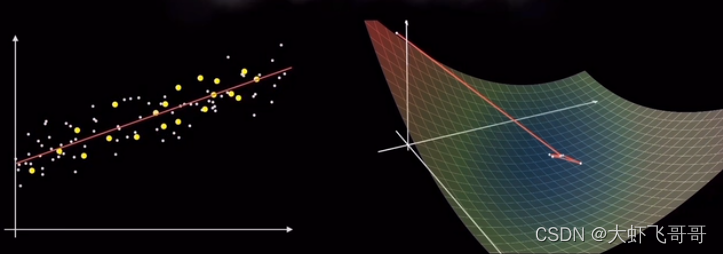
小批量梯度下降MBGD: 选择一小批样本进行计算(batch_size)。每次使用多个样本来估计梯度,这样可以减少不确定性,提高收敛速率。
调节 Batch_Size 对训练效果影响到底如何?
- Batch_Size 太小,模型表现效果极其糟糕(error飙升)。
- 随着 Batch_Size 增大,处理相同数据量的速度越快。
- 随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。
- 由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
- 由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
















 1058
1058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











