







最近,计算机系统老师布置了道作业: 给定一个16M大小的文本文件,里面是随机的大小写混合的字符,要求将所有的字符改为小写。
我的电脑硬件环境:
华硕笔记本h550jv,cpu为i7-4700hq,内存和显卡就不写了~应该对我们的性能优化之路影响很低。
原材料已生成好,为了最大化的测试,我已经准备了16kb-1Gb的测试文件。
先上作业附带的示例代码,示例代码肯定只是一个功能展示,性能可想而知:
// lowercase.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <iostream>
#include <Windows.h>
/*待完成的字符串转换函数,
_instr字符串既是输入参数也是输出参数,不再开辟新的内存;
_len为字符串长度
尝试不同的文件大小16k,1M,16M或者更大(可使用wstr程序生成更大的文件),
WARNING:大文本文件不要试图用记事本打开,打开方法google一下
*/
int TransLower(char *_instr, int _len)
{
int i;
for(i=0;i<strlen(_instr);i++)
if(_instr[i]>='A'&&_instr[i]<='Z')
_instr[i]-=('A'-'a');
return 0;
}
int _tmain(int argc, _TCHAR* argv[])
{
//打开文件
HANDLE hfile = CreateFile(L"d:\\char16M.txt", GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL);
int fileSize = 0;
if (INVALID_HANDLE_VALUE == hfile)
{
return -1;
}
else
{
fileSize = GetFileSize(hfile, NULL);
std::cout << "the size of file : " << fileSize << std::endl;
}
//开辟内存
char *charBuf = NULL;
try
{
charBuf = new char [fileSize];
}
catch (std::bad_alloc& e)
{
std::cout << "内存申请失败" << std::endl;
return -2;
}
//将文件中的字符载入到内存中
DWORD dwRet;
ReadFile(hfile, charBuf, fileSize, &dwRet, NULL);
CloseHandle(hfile);
hfile = INVALID_HANDLE_VALUE;
DWORD startime = GetTickCount();
//转换字符串中的大写字母为小写字母
TransLower(charBuf, fileSize);
DWORD endtime = GetTickCount();
std::cout << "calculate time : " << (endtime - startime) << "ms" << std::endl;
//将字符串写入另一文件
HANDLE hwfile = CreateFile(L"d:\\lowerchar16M.txt", GENERIC_WRITE, FILE_SHARE_READ, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL);
if (INVALID_HANDLE_VALUE == hwfile)
{
delete [] charBuf;
charBuf = NULL;
return -1;
}
DWORD nRet;
WriteFile(hwfile, charBuf, fileSize, &nRet, NULL);
CloseHandle(hwfile);
delete [] charBuf;
charBuf = NULL;
int temp;
std::cin >> temp;
return 0;
}
下面说我的解决方案(都先用16M的文件作为测试):
我的第一想法是将大小写字母统一处理
方案一:使用stl的map数据类型,于是就出现了下面的丧心病狂的key-value对:
void makemaptable(std::map<char, char> &mymap)
{
mymap.insert(make_pair('A', 'a')); mymap.insert(make_pair('B', 'b')); mymap.insert(make_pair('C', 'c')); mymap.insert(make_pair('D', 'd')); mymap.insert(make_pair('E', 'e'));
mymap.insert(make_pair('F', 'f')); mymap.insert(make_pair('G', 'g')); mymap.insert(make_pair('H', 'h')); mymap.insert(make_pair('I', 'i')); mymap.insert(make_pair('J', 'j'));
mymap.insert(make_pair('K', 'k')); mymap.insert(make_pair('L', 'l')); mymap.insert(make_pair('M', 'm')); mymap.insert(make_pair('N', 'n')); mymap.insert(make_pair('O', 'o'));
mymap.insert(make_pair('P', 'p')); mymap.insert(make_pair('Q', 'q')); mymap.insert(make_pair('R', 'r')); mymap.insert(make_pair('S', 's')); mymap.insert(make_pair('T', 't'));
mymap.insert(make_pair('U', 'u')); mymap.insert(make_pair('V', 'v')); mymap.insert(make_pair('W', 'w')); mymap.insert(make_pair('X', 'x')); mymap.insert(make_pair('Y', 'y'));
mymap.insert(make_pair('Z', 'z')); mymap.insert(make_pair('a', 'a')); mymap.insert(make_pair('b', 'b')); mymap.insert(make_pair('c', 'c')); mymap.insert(make_pair('d', 'd'));
mymap.insert(make_pair('e', 'e')); mymap.insert(make_pair('f', 'f')); mymap.insert(make_pair('g', 'g')); mymap.insert(make_pair('h', 'h')); mymap.insert(make_pair('i', 'i'));
mymap.insert(make_pair('j', 'a')); mymap.insert(make_pair('k', 'k')); mymap.insert(make_pair('l', 'l')); mymap.insert(make_pair('m', 'm')); mymap.insert(make_pair('n', 'n'));
mymap.insert(make_pair('u', 'a')); mymap.insert(make_pair('v', 'v')); mymap.insert(make_pair('w', 'w')); mymap.insert(make_pair('x', 'x')); mymap.insert(make_pair('y', 'y'));
mymap.insert(make_pair('z', 'z')); mymap.insert(make_pair('o', 'o')); mymap.insert(make_pair('p', 'p')); mymap.insert(make_pair('q', 'q')); mymap.insert(make_pair('r', 'r'));
mymap.insert(make_pair('t', 't')); mymap.insert(make_pair('s', 's'));
return;
}#include<utility>
#include<iostream>
#include<map>
#include<cstdlib>
#include<time.h>
using namespace std;
void makemaptable(std::map<char, char> &mymap)
{
mymap.insert(make_pair('A', 'a')); mymap.insert(make_pair('B', 'b')); mymap.insert(make_pair('C', 'c')); mymap.insert(make_pair('D', 'd')); mymap.insert(make_pair('E', 'e'));
mymap.insert(make_pair('F', 'f')); mymap.insert(make_pair('G', 'g')); mymap.insert(make_pair('H', 'h')); mymap.insert(make_pair('I', 'i')); mymap.insert(make_pair('J', 'j'));
mymap.insert(make_pair('K', 'k')); mymap.insert(make_pair('L', 'l')); mymap.insert(make_pair('M', 'm')); mymap.insert(make_pair('N', 'n')); mymap.insert(make_pair('O', 'o'));
mymap.insert(make_pair('P', 'p')); mymap.insert(make_pair('Q', 'q')); mymap.insert(make_pair('R', 'r')); mymap.insert(make_pair('S', 's')); mymap.insert(make_pair('T', 't'));
mymap.insert(make_pair('U', 'u')); mymap.insert(make_pair('V', 'v')); mymap.insert(make_pair('W', 'w')); mymap.insert(make_pair('X', 'x')); mymap.insert(make_pair('Y', 'y'));
mymap.insert(make_pair('Z', 'z')); mymap.insert(make_pair('a', 'a')); mymap.insert(make_pair('b', 'b')); mymap.insert(make_pair('c', 'c')); mymap.insert(make_pair('d', 'd'));
mymap.insert(make_pair('e', 'e')); mymap.insert(make_pair('f', 'f')); mymap.insert(make_pair('g', 'g')); mymap.insert(make_pair('h', 'h')); mymap.insert(make_pair('i', 'i'));
mymap.insert(make_pair('j', 'a')); mymap.insert(make_pair('k', 'k')); mymap.insert(make_pair('l', 'l')); mymap.insert(make_pair('m', 'm')); mymap.insert(make_pair('n', 'n'));
mymap.insert(make_pair('u', 'a')); mymap.insert(make_pair('v', 'v')); mymap.insert(make_pair('w', 'w')); mymap.insert(make_pair('x', 'x')); mymap.insert(make_pair('y', 'y'));
mymap.insert(make_pair('z', 'z')); mymap.insert(make_pair('o', 'o')); mymap.insert(make_pair('p', 'p')); mymap.insert(make_pair('q', 'q')); mymap.insert(make_pair('r', 'r'));
mymap.insert(make_pair('t', 't')); mymap.insert(make_pair('s', 's'));
return;
}
int main()
{
/*use map as table container*/
std::map<char, char> mymap;
makemaptable(mymap);
/*use array straightly*/
FILE *mystringfile = fopen("F:\\char16M.txt", "r");
FILE *newstringfile = fopen("F:\\data", "w+");
if (mystringfile == NULL || newstringfile == NULL)
{
printf("heheda");
exit(-1);
}
const long LENGTH = 16 * 1024 * 1024;
char *randomstring = new char[LENGTH];/*源随机字符串
*/
char * upcasestring = new char[LENGTH];/*目标字符串序列
*/
fread(randomstring, sizeof(char), LENGTH, mystringfile);/*读取源
*/
cout << "src string size:" << strlen(randomstring) << endl;
long long startime = clock();
#pragma omp parallel for/*intel 并行计算库
*/
for (register long i = 0; i != LENGTH; i++)
{
upcasestring[i] = mymap.at(randomstring[i]);
}
long long endtime = clock();
cout << "run time:" << endtime - startime << "ms" << endl;
fwrite(upcasestring, sizeof(char), LENGTH, newstringfile);
fclose(mystringfile);
fclose(newstringfile);
delete[]randomstring;
delete[]upcasestring;
upcasestring = nullptr;
randomstring = nullptr;
system("pause");
}
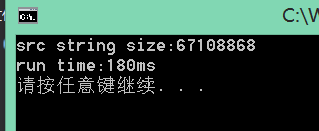
16M源字符串:
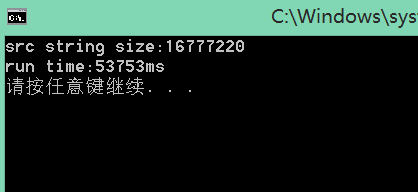
50多s是吧,考虑到是一个16*1024*1024的数据处理,大概还没让人抓狂,那我们实验一个64M的吧~~~等了好大一会了,我们再等等吧==
结果是:
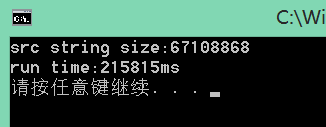
215秒!果断受不了,我的电脑也烫的要炸了,毕竟是一个类似死循环的东西~~
开始step2
我们考虑到,对于字母的ascii码,小写字母97-122,大写字母65-90,而我们在运算时,完全可以把字母字符当作对应的整数值,于是,我就做了一个长度为123的数组 char *alphebaltTable = new char[122];这样我们就可以直接模拟上面的map<char,char>的效果了,但是速度肯定会提升很多,数组生成代码如下:
void makearraytable(char *& alphebaltTable)
{
for (int index = 0; index < TABLE_LENGT; index++)
{
if (index >= 65 && index <= 90)
{
alphebaltTable[index] = index + ('a' - 'A');
}
else
alphebaltTable[index] = index;
}
return;
}
#include<utility>
#include<iostream>
#include<map>
#include<cstdlib>
#include<time.h>
using namespace std;
const int TABLE_LENGTH = 122;
void makearraytable(char *& alphebaltTable)
{
for (int index = 0; index < TABLE_LENGTH; index++)
{
if (index >= 65 && index <= 90)
{
alphebaltTable[index] = index + ('a' - 'A');
}
else
alphebaltTable[index] = index;
}
return;
}
int main()
{
/*use array straightly*/
char *alphebaltTable = new char[TABLE_LENGTH];
makearraytable(alphebaltTable);
FILE *mystringfile = fopen("F:\\char16M.txt", "r");
FILE *newstringfile = fopen("F:\\data", "w+");
if (mystringfile == NULL || newstringfile == NULL)
{
printf("heheda");
exit(-1);
}
const long LENGTH = 16 * 1024 * 1024;
char *randomstring = new char[LENGTH];/*源随机字符串
*/
fread(randomstring, sizeof(char), LENGTH, mystringfile);
cout << "src string size:" << strlen(randomstring) << endl;
char * upcasestring = new char[LENGTH];
long long startime = clock();
#pragma omp parallel for/*intel 并行计算库
*/
for (register long i = 0; i != LENGTH; i++)
{
*(upcasestring + i) = alphebaltTable[randomstring[i]];
}
long long endtime = clock();
cout << "run time:" << endtime - startime << "ms" << endl;
fwrite(upcasestring, sizeof(char), LENGTH, newstringfile);
fclose(mystringfile);
fclose(newstringfile);
delete[]randomstring;
delete[]alphebaltTable;
alphebaltTable = NULL;
randomstring = nullptr;
delete[] upcasestring;
upcasestring = nullptr;
}16M文件:
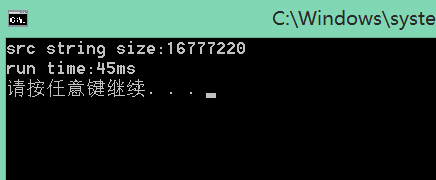
64M文件:
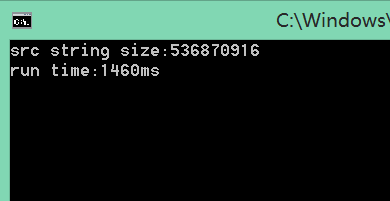
来个512M文件!:
来个1G的文件:
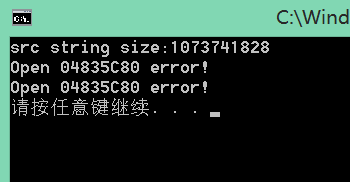
duang~~读取错误!我们先忽视它,待我开一篇新的博客来讨论它;
我们这时看到对于512M的字符串转换,时间是1460ms,应该来说比较理想了,但我说,这还不够!
开始step3
原本想通过cuda openmp加速,但发现加了以后,对性能提升基本为0,偶尔还会下降,主要是因为我们单次计算量太小了。那怎么办?我们人工并行,并合理分配每个任务块大小!
二话不说,c++11thread走起(如果你还没用过,纳尼太low了,随便google一发,学习一下吧!):
回到我们原来的问题,无非就是值拷贝,单次任务相关性极低,我们平分这些任务,使其并行化呢,代码搞起:
#include<time.h>
#include<cstdlib>
#include<iostream>
#include<map>
#include<algorithm>
#include<utility>
#include<thread>
using namespace std;
const int TABLE_LENGT = 122;
void makearraytable(char *& alphebaltTable)
{
for (int index = 0; index < TABLE_LENGT; index++)
{
if (index >= 65 && index <= 90)
{
alphebaltTable[index] = index + ('a' - 'A');
}
else
alphebaltTable[index] = index;
}
return;
}
uint64_t startime;
void mythreadfunc(long &start_series, long & end_series, char * &src_set, char * &alphebaltTable, char * &des_set)
{
long i;
for (i = start_series; i <= end_series; i++)
{
*(des_set+i) = alphebaltTable[src_set[i]];
}
uint64_t diff_time = clock() - startime;
std::cout << "run time:" << diff_time << "ms" << std::endl;
}
int main()
{
char *alphebaltTable = new char[TABLE_LENGT];
makearraytable(alphebaltTable);
FILE *mystringfile = fopen("F:\\char16M.txt", "r");
FILE *newstringfile = fopen("F:\\data", "w+");
if ( mystringfile == NULL || newstringfile == NULL)
{
printf("heheda");
exit (- 1);
}
const long LENGTH = 16 * 1024 * 1024;
char *randomstring = new char[LENGTH];/*源随机字符串*/
char * upcasestring = new char[LENGTH];
/*应该使用硬件原生cpu核心数,不然的话,很难达到好的性能;
例如,我强制开了8 cpu core,在我的机器上没有问题,但是,在室友的机器上就会出现很大的数据误差
原生4core:20ms
虚拟8core : 15ms 15ms 15ms 15ms 30ms 30ms 30ms 30ms 后面的虚拟线程显著拖慢了系统运算时间
*/
const int THREAD_NUM =thread::hardware_concurrency();
long *set_num = new long[THREAD_NUM];/*线程运算元素集合大小
*/
long *start_series = new long[THREAD_NUM];/*开始执行的序列号
*/
long *end_series = new long[THREAD_NUM];/*终止执行的序列号
*/
fread(randomstring, sizeof(char), LENGTH, mystringfile);/*读取源
*/
{/*操作初始化集合大小
*/
if (LENGTH % (THREAD_NUM) == 0)
{
long average = LENGTH / (THREAD_NUM);
for (int i = 0; i < THREAD_NUM; i++)
{
start_series[i] = average*i;
end_series[i] = average*(i + 1) - 1;
}
}
else
{
int average = LENGTH / (THREAD_NUM - 1);
int mod = LENGTH % (THREAD_NUM - 1);
for (int i = 0; i < THREAD_NUM - 1; i++)
{
set_num[i] = average;
}
set_num[THREAD_NUM - 1] = mod;
for (int i = 0; i < THREAD_NUM; i++)
{
start_series[i] = i*average;
}
for (int i = 0; i < THREAD_NUM; i++)
{
end_series[i] = set_num[i] + start_series[i] - 1;
}
}
}
int thread_num_small = THREAD_NUM - 1;
startime = clock();
for (register int i = 0; i < thread_num_small; i++)
{
//前几次线程分离,以使操作进行下去
thread t(mythreadfunc, start_series[i], end_series[i], randomstring, alphebaltTable, upcasestring);
t.detach();
}
//最后一次join,试内存得已释放
thread t(mythreadfunc, start_series[thread_num_small], end_series[thread_num_small]
, randomstring, alphebaltTable, upcasestring);
t.join();
fwrite(upcasestring, sizeof(char), LENGTH, newstringfile);
fclose(mystringfile);
fclose(newstringfile);
delete []randomstring;
delete []alphebaltTable;
alphebaltTable = NULL;
randomstring = nullptr;
delete[] upcasestring;
upcasestring = nullptr;
system("pause");
}
16M字符串测试结果: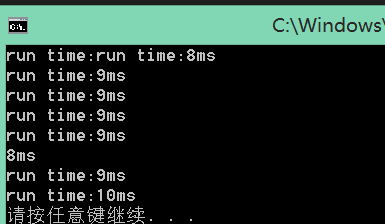
64M字符串测试:
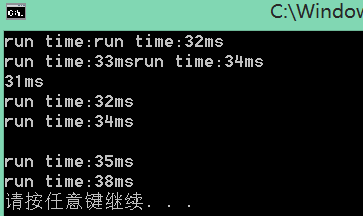
512M字符串测试:
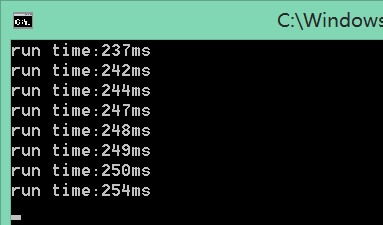
512M的字符串转换 249ms,是一个理想的时间了,但是,我们试试在并行数目上还有没有文章可做,在前面,我们说过,当线程数超过物理核心(超线程属于物理核心)时,性能不增反降,但当我们单个任务太繁重时,可不可以适当调节呢?
下面,我给出了使用2倍物理核心线程数的方案测试结果:
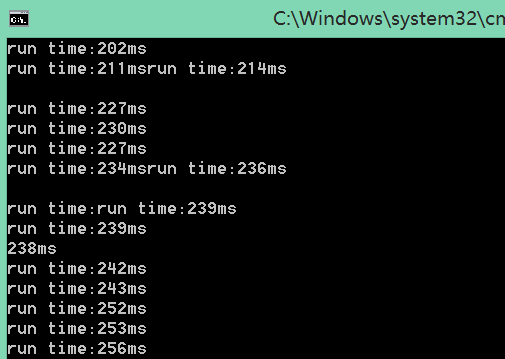
额,效率(最慢的thread的时间)还是下降了。。。所以,单个应用还是最大线程数设到物理核心数吧。。。
但是,这个效率还不够,夜深了,室友都休息了,我明天将会给出windows thread下 及嵌入汇编代码的优化结果!
晚安!
接着昨天的工作,一直羡慕android开发中的 asynctask,但是今天翻了一下c++11和c++14标准,发现竟然已经支持了原生语言层面的std::async,创建和使用非常简易,看一下官方的例子就明白了:
#include<future>
#include<iostream>
#include<algorithm>
#include<numeric>
#include<vector>
using namespace std;
template< typename RAIter>
int parrellSum(RAIter beg, RAIter end)
{
RAIter::difference_type len= end-beg;
if (len < 1000)
return std::accumulate(beg, end, 0);
RAIter mid = beg + len / 2;
auto parrellHandler = std::async(std::launch::async, parrellSum<RAIter>, mid, end);
int sum = parrellSum(beg, mid);
return sum + parrellHandler.get();
}
int main()
{
vector<int> v(10000, 1);
int sum = parrellSum(v.cbegin(), v.cend());
cout << sum << "\n";
}
运行结果是10000,看不大懂的同学建议补充一下泛型及模板的知识~哦,还有递归。
下面,我们就尝试模仿上面的例子来优化我们的程序。
#include<time.h>
#include<cstdlib>
#include<iostream>
#include<map>
#include<algorithm>
#include<utility>
#include<thread>
#include<future>
using namespace std;
const int TABLE_LENGT = 122;
void makearraytable(char *& alphebaltTable)
{
for (int index = 0; index < TABLE_LENGT; index++)
{
if (index >= 65 && index <= 90)
{
alphebaltTable[index] = index + ('a' - 'A');
}
else
alphebaltTable[index] = index;
}
return;
}
uint64_t s;
int chunk = 0;
int parrellAsyn(long start_series, long end_series, char * src_set, char * alphebaltTable, char * des_set)
{
long diff_len = end_series - start_series;
if (diff_len < chunk)
{
for (long i = start_series; i != end_series; ++i)
{
*(des_set + i) = alphebaltTable[src_set[i]];
}
return 1;
}
long mid_series = start_series + diff_len / 2;
auto parrellHandler = async(std::launch::async, parrellAsyn, mid_series, end_series, src_set, alphebaltTable, des_set);
int sum = parrellAsyn(start_series, mid_series, src_set, alphebaltTable, des_set);
return sum + parrellHandler.get();
}
int main()
{
char *alphebaltTable = new char[TABLE_LENGT];
makearraytable(alphebaltTable);
FILE *mystringfile = fopen("F:\\char16M.txt", "r");
FILE *newstringfile = fopen("F:\\data", "w+");
if ( mystringfile == NULL || newstringfile == NULL)
{
printf("heheda");
exit (- 1);
}
const long LENGTH = 16 * 1024 * 1024;
char *randomstring = new char[LENGTH];/*源随机字符串*/
chunk = LENGTH / (4);
char * upcasestring = new char[LENGTH];
fread(randomstring, sizeof(char), LENGTH, mystringfile);
s = clock();
int sum=parrellAsyn(0, LENGTH, randomstring, alphebaltTable, upcasestring);
long e = clock();
cout << sum << endl;
cout << "all runtime :" << (e - s) << endl;
fwrite(upcasestring, sizeof(char), LENGTH, newstringfile);
fclose(mystringfile);
fclose(newstringfile);
delete []randomstring;
delete []alphebaltTable;
alphebaltTable = NULL;
randomstring = nullptr;
delete[] upcasestring;
upcasestring = nullptr;
system("pause");
}
这样,后台为我们开了8个微线程。
可能有朋友会问,既然只开8个线程,为什么要用递归而不是直接8个异步任务呢,这个问题很好,是时候拿出来官方的解释了:
Notes
The implementation may extend the behaviorof the first overload of std::async by enabling additional(implementation-defined) bits in the default launch policy.
One drawback with the current definition of std::asyncis that the associated state of an operation launched by std::async can causethe returned std::future'sdestructor to block until the operation is complete. This can limitcomposability and result in code that appears to run in parallel but in realityruns sequentially. For example:
Run this code
{
std::async(std::launch::async, []{ f(); });
std::async(std::launch::async, []{ g(); }); // does not run until f() completes
}
In the above code, f() and g() run sequentiallybecause the destruction of the returned future blocks until each operation hasfinished.
你顺序的开这些异步任务并不一定是并行的!
所以我们还是递归吧;还是看我们的测试结果:
16M:

32M:

64M:

512M:

可以看出,速度有了不少提升!而且async的易用性也很强!
由于时间原因和vs中潜入汇编存在很多问题,所以优化之路就暂时到这儿了。















 4444
4444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









