







数据投毒
定义
主要是在训练数据中加入精心构造的异常数据,破坏原有的训练数据的概率分布,导致模型在某些条件会产生分类或聚类错误[1]。
适应场景:
由于数据投毒攻击需要攻击者接触训练数据,通常针对在线学习场景(即模型利用在线学习数据不断学习更新模型),或者需要定期重新训练进行模型更新的系统,这类攻击比较有效,典型场景如推荐系统、自适应生物识别系统、垃圾邮件检测系统等。
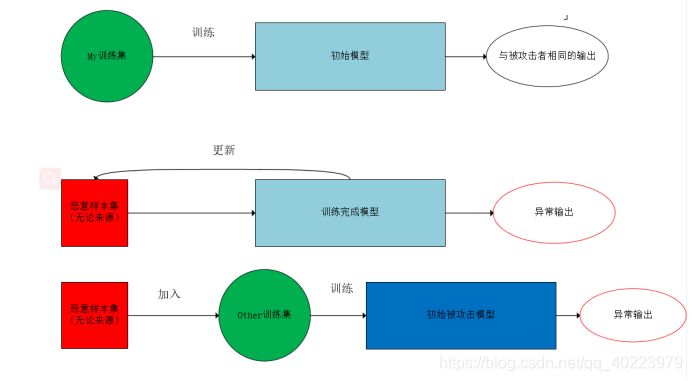
数据投毒攻击流程可以分为三个阶段(假设不知道被攻击的训练集和模型参数):
1.根据被攻击模型的输出特征,选择替代的训练集,训练在同样的输入下,具有相同输出的模型。例如对猫狗类别的分类。
2.初始化恶意样本集(无论来源),使用梯度更新(根据需要构建损失函数,例如梯度上升策略)恶意样本,直至达到理想效果。
3.将恶意样本集投入被攻击模型的训练集
图示如下
一般解决办法:
- 训练数据过滤(Training Data Filtering):该技术侧重对训练数据集的控制,利用检测和净化的方法防止药饵攻击影响模型。具体方向包括:根据数据的标签特性找到可能的药饵攻击数据点,在重训练时过滤这些攻击点;采用模型对比过滤方法,减少可以被药饵攻击利用的采样数据,并过滤数据对抗药饵攻击。
- 回归分析(Regression Analysis):该技术基于统计学方法,检测数据集中的噪声和异常值。具体方法包括对模型定义不同的损失函数(loss function)来检查异常值,以及使用数据的分布特性来进行检测等。
- 集成分析(Ensemble Analysis):该技术强调采用多个子模型的综合结果提升机器学习系统抗药饵攻击的能力。多个独立模型共同构成AI系统,由于多个模型采用不同的训练数据集,整个系统被药饵攻击影响的可能性进一步降低。[2]
关于投毒攻击与对抗样本比较的描述:
1.An exploratory attack exploits the misclassification of models without affecting the training
process. A typical exploratory attack is the adversarial example attack. An adversarial example attackis a deformed sample, with some disturbance added to the original sample, to make the model liableto be misinterpreted, and a person cannot identify the disturbance. This attack’s characteristics do notaffect the training data of the DNN.
2.A causative attack degrades the accuracy of the model by approaching the training process of themodel. A poisoning attack [9,26,27] is a causative attack method that reduces the accuracy of a model by adding malicious data between the processes during the training of the model. There is a strong possibility that this attack will have access to the training process of the model, but it has the advantage of effectively reducing the accuracy of the model.
概括的这两段话,对抗样本攻击与投毒攻击区别不在于有没有梯度更新,而在于作用时间是在预测期间还是在训练期间。
参考
[1]人工智能安全标准化白皮书
[2]华为AI安全白皮书
[3]Kwon H, Yoon H, Park K W. Selective Poisoning Attack on Deep Neural Networks[J]. Symmetry, 2019, 11(7): 892.

















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









