







- 题目:Accelerating Sparse Deep Neural Network on FPGA
- 时间:2019
- 会议:Proceedings of IEEE High Performance Extreme Computing Conference (HPEC)
- 研究机构:UIUC Deming Chen
1 缩写 & 引用
Efficient and effective sparse LSTM on fpga with bank-balanced sparsity, in Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays
2 abstract & introduction & background
为了能在嵌入式环境下进行低功耗和低计算量的神经网络,通常努力的方向有三点:
- 设计更轻更小的DNN
- 通过牺牲精度来减少DNN的计算量
- 通过定制化的硬件来加速
这篇论文是针对稀疏神经网络在FPGA的加速,贡献点有三条
- 可配置的稀疏DNN inference engine
- 提出了针对稀疏DNN inference优化措施
- 稀疏DNN的计算进行了建模和分析
这里他主要针对于全连接层的矩阵相乘,然后卷积操作也可以展成矩阵乘法
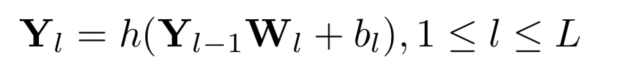
3 design optimizations & sparse DNN accelerator architecture
把feature看作是一个向量,那么feature视为稠密矩阵,DNN的weight视为稀疏矩阵,通过索引来标定非零值

一个FPGA上有n个数目的accelerator,每个accelerator可以进行某一层的计算,每个accelerator之间相互独立,全靠host CPU调度,调度算法很简单host CPU就把工作交给空闲的accelerator,或者当accelerator刚刚完成一项工作时,也可以分配给他
每个accelerator内部好几个PE,每个PE就是一个乘加运算,向量乘矩阵,向量中的一个元素广播到所有的PE,分别乘上不同的weight,n维向量就要进行n次乘累加。
















 1385
1385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









