







文章目录
- 题目:Deep Convolutional Neural Network Architecture With Reconfigurable Computation Patterns
- 时间:2017
- 期刊: TVLSI
- 研究机构:清华大学
- 参考博客:https://blog.csdn.net/darknessdarkness/article/details/106251428
1 introduction
本篇论文的主要贡献:
- DNA can reconfigure its data paths to support a hybrid data reuse pattern for different layer sizes
- DNA can reconfigure its computing resources to support a highly scalable and efficient mapping method
- A layer-based scheduling framework is proposed to reconfigure DNA’s resources
2 method
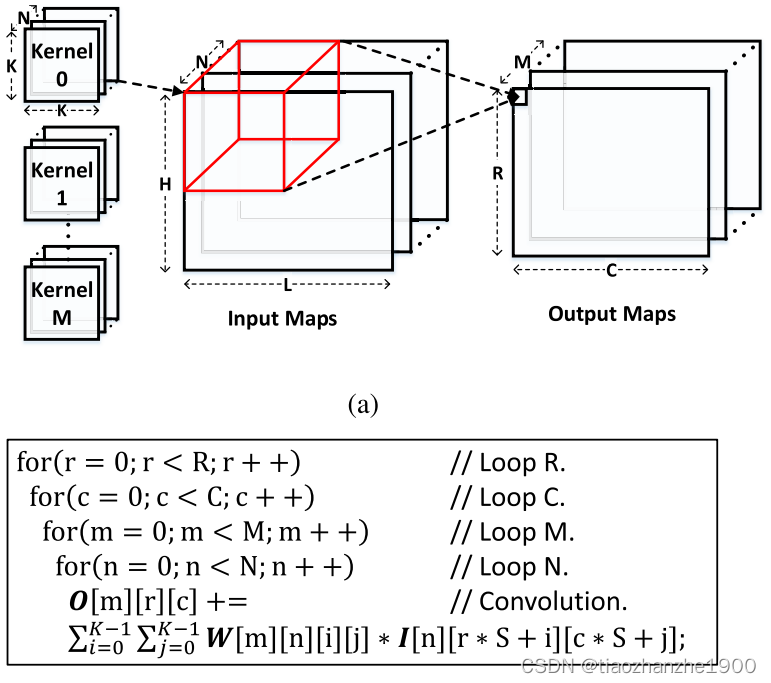
首先明确参数:
- N:输入通道数
- M:输出通道数
- L:输入特征图宽度
- H:输入特征图高度
- C:输出特征图宽度
- R:输出特征图高度
- K:卷积核宽度
DRAM访问次数为 I N ∗ α i + O U T ∗ α o + W G T ∗ α w + T o t a l P o o l e d O u t p u t IN * \alpha_i + OUT * \alpha_o + WGT * \alpha_w + TotalPooledOutput IN∗αi+OUT∗αo+WGT∗αw+TotalPooledOutput
其中 α i \alpha_i αi、 α w \alpha_w αw、 α o \alpha_o αo分别表示输入特征图、权重、输出特征图的数据复用次数
2.1 输入复用Input Reuse(IR)
输入的特征图,先沿输出通道方向算,再沿输入通道方向算,这样特征图只需要加载一次,即
α
i
=
1
\alpha_i = 1
αi=1,此时
α
w
\alpha_w
αw取决于输入特征图在宽度和高度方向tiling的次数,
α
o
\alpha_o
αo取决于权重在输出通道方向tiling的次数
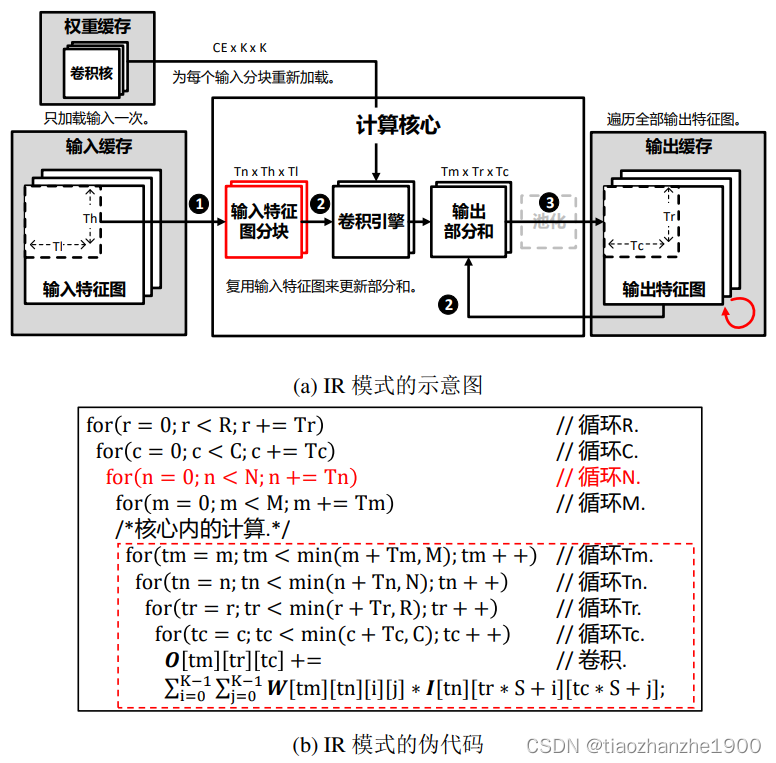
缺点: 输入特征图存在overlay的区域
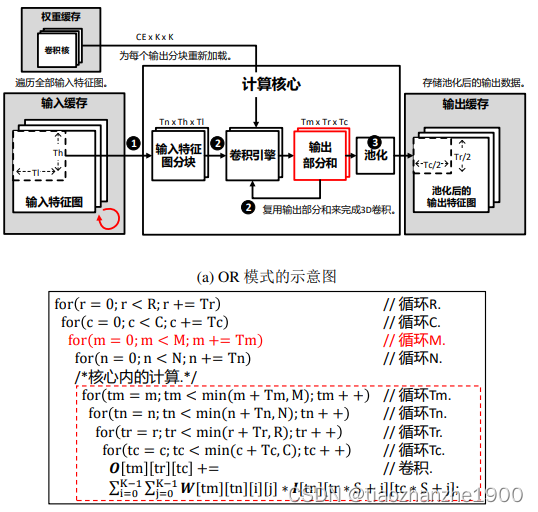
2.2 输出复用Output Reuse(OR)
如下图,先沿输入通道算,再沿输出通道算,输出特征图一直在累加,所以
α
o
=
0
\alpha_o = 0
αo=0,而
α
i
\alpha_i
αi取决于输出通道tiling次数,
α
w
\alpha_w
αw取决于输出特征图宽度和高度方向tiling次数
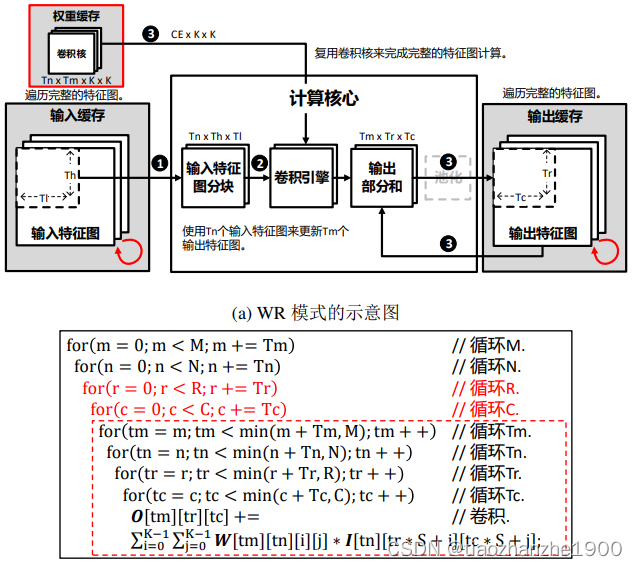
2.3 权重复用Weight Reuse(WR)
- 题目:FlexFlow: A Flexible Dataflow Accelerator Architecture for Convolutional Neural Networks
- 时间:2017
- 会议:HPCA
- 研究机构:中科院计算所
- 参考博客:https://zhuanlan.zhihu.com/p/109041345
1 方法
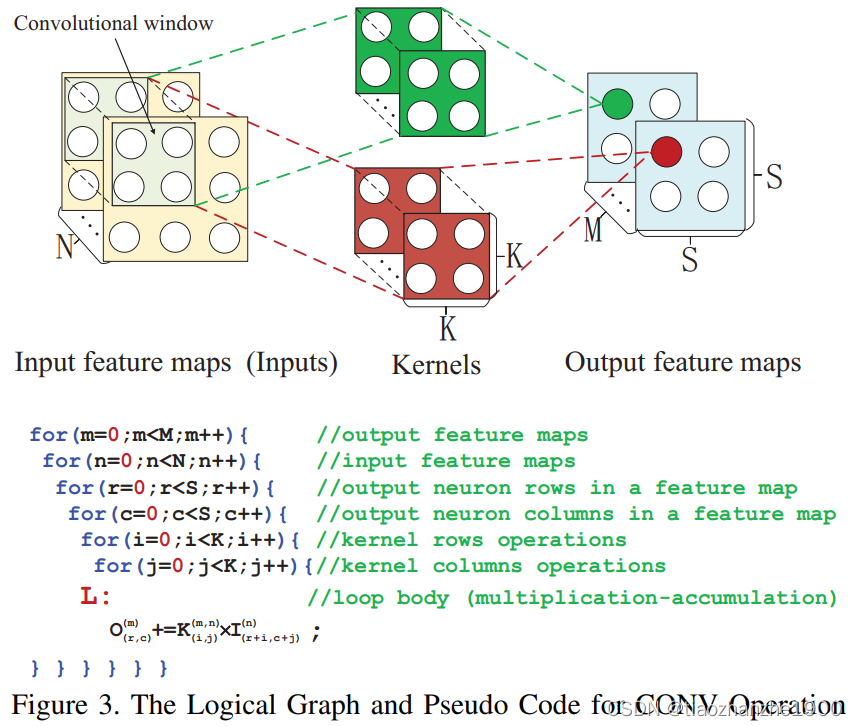
这有几个概念是跟我们之前的理解不一样:
- Feature map Parallelism (FP):对应输入通道和输出通道
- Neuron Parallelism (NP):对应输出特征图宽度和高度方向
- Synapse Parallelism (SP):对应了一个3x3或5x5 kernel内部的并行度
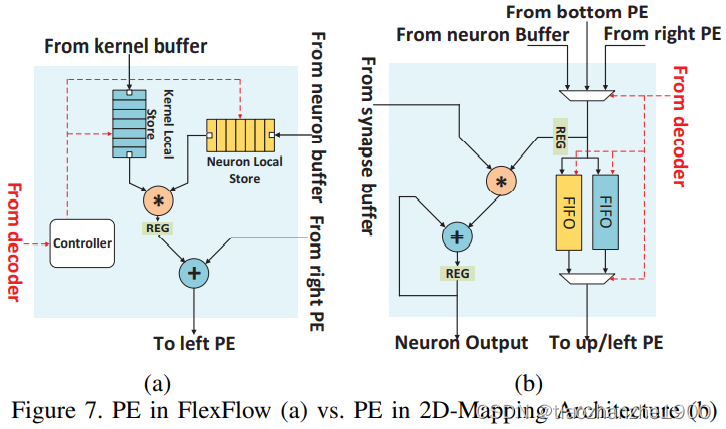
针对架构的分类,同样采用了Neuron、Synapse的概念,比如说3x3kernel内部并行的SP对应了(a)的脉动阵列,输出特征图宽度和高度方向的NP对应了(b)的2D mapping,而FP对应了tiling,倒是比较接近我们的设计
2 架构
PE结构如下图所示,可以发现每个PE内部都会有一个local buffer,方便实现不同数据的重排,那么卷积操作一共分成三步
- DataFlow1: 数据分发到PEDistribution Layer to Local Store
- DataFlow2: Local Store to Operator
- DataFlow3: Neuron and Kernel Buffers to Distribution Layer
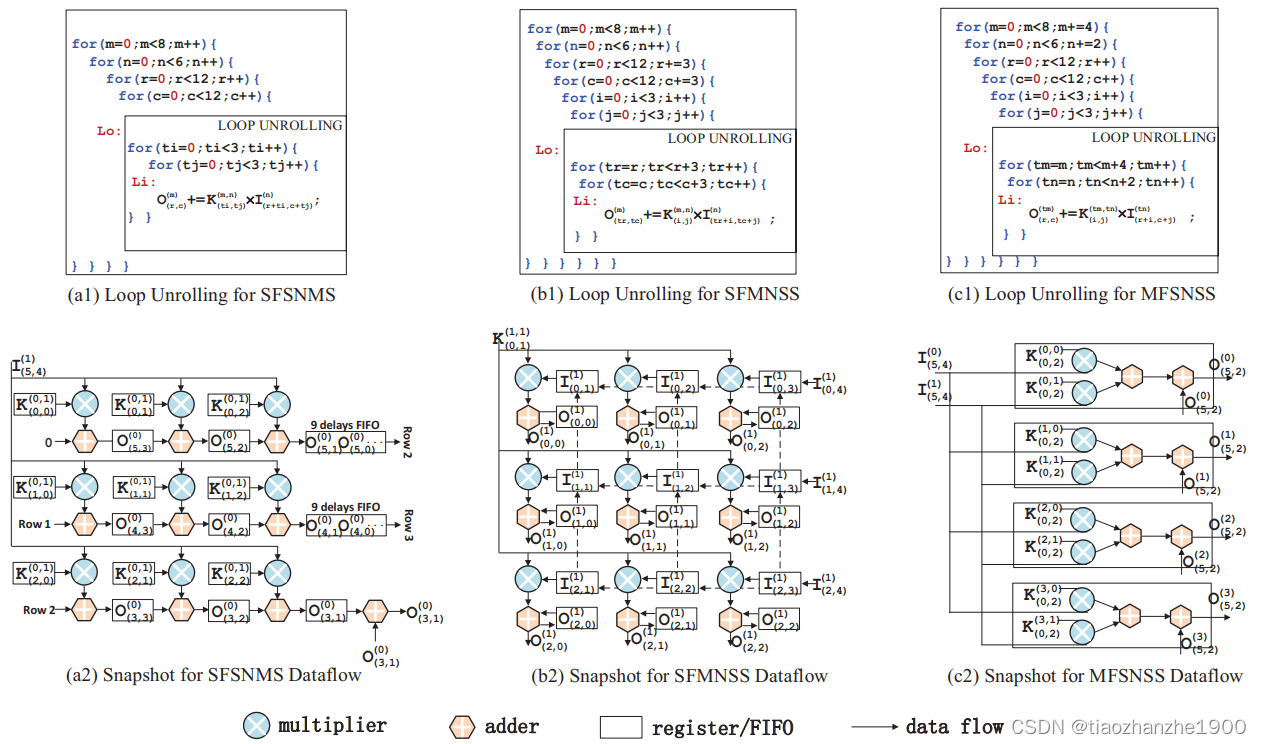
下图展示了混合并行度的情况,对于(a),包括了 - 输出通道方向并行度 x2
- kernel内部并行度 x4
- 输出特征图x方向 x2
对于(b),包括了
- 输出通道方向并行度 x2
- 输入通道方向并行度 x2
- kernel内部并行度 x2
- 输出特征图x方向 x2
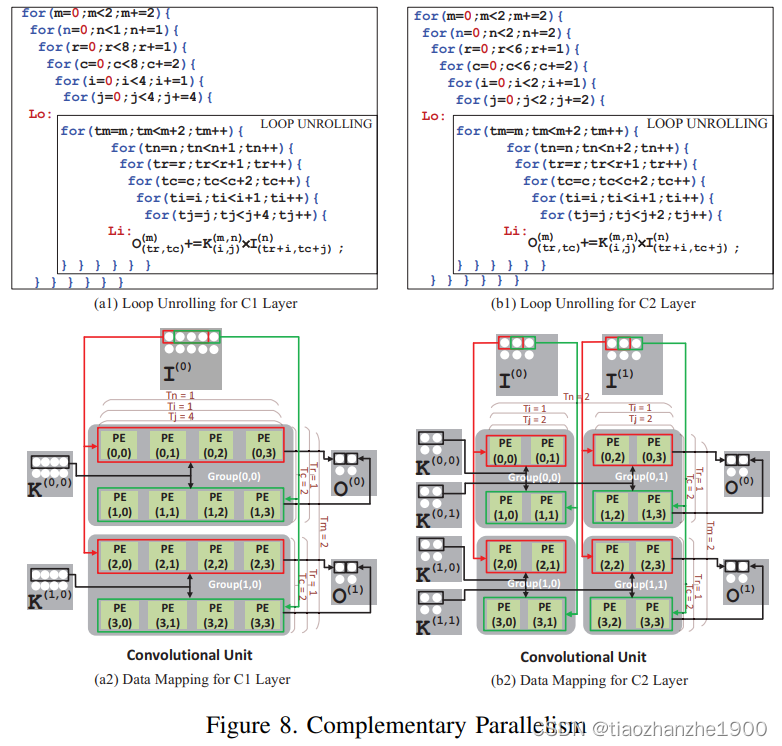
下面这个图对应了上图(a),表示是具体数据分布方式,黑箭头表示t时刻数据访问,灰箭头表示t+1时刻数据访问。
- 在t时刻时,第一行PE对应了输入特征图的0-3
- 在t时刻时,第一行PE对应了输入特征图的1-4
- 在t+1时刻时,第一行PE对应了输入特征图的2-5
- 在t+1时刻时,第一行PE对应了输入特征图的3-6
可以发现,数据按下面的排布方式,不会出现bank conflict
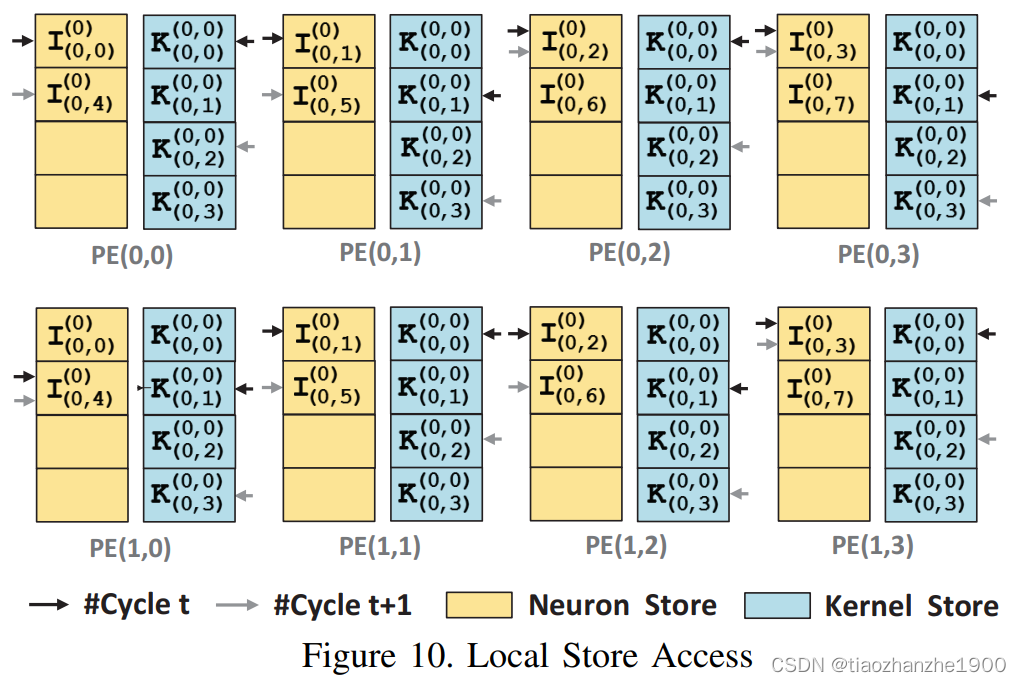
可以说,想要实现灵活的数据流,主要的难度都在这个数据排布和重组上

















 3184
3184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









