







import pandas as pd
titanic = pd.read_csv('../Datasets/Breast-Cancer/titanic.txt')
y=titanic['survived']
X = titanic.drop(['row.names','name','survived'],axis=1)
X['age'].fillna(X['age'].mean(),inplace=True)
X.fillna('UNKNOWN',inplace=True)
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=33)
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer()
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
X_test = vec.transform(X_test.to_dict(orient='record'))
print(len(vec.feature_names_))
#使用决策树模型依靠所有特征进行预测,并作性能评估
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(criterion = 'entropy')
dt.fit(X_train,y_train)
print(dt.score(X_test,y_test))
#从sklearn导入特征筛选器
from sklearn import feature_selection
fs = feature_selection.SelectPercentile(feature_selection.chi2,percentile=20)
X_train_fs = fs.fit_transform(X_train,y_train)
dt.fit(X_train_fs,y_train)
X_test_fs = fs.transform(X_test)
print(dt.score(X_test_fs,y_test))
from sklearn.cross_validation import cross_val_score
import numpy as np
percentiles = range(1,100,2)
results = []
for i in percentiles:
fs = feature_selection.SelectPercentile(feature_selection.chi2,percentile=i)
X_train_fs = fs.fit_transform(X_train,y_train)
scores = cross_val_score(dt,X_train_fs,y_train,cv=5)
results = np.append(results,scores.mean())
print (results)
opt = np.where(results == results.max())[0]
#print('Optimal number of feature %d' %percentiles[opt])
import pylab as pl
pl.plot(percentiles,results)
pl.xlabel('percentiles of features')
pl.ylabel('accuracy')
pl.show()
#使用最佳筛选后的特征,利用相同配置的模型在测试集上进行性能评估
from sklearn import feature_selection
fs = feature_selection.SelectPercentile(feature_selection.chi2,percentile=7)
X_train_fs = fs.fit_transform(X_train,y_train)
dt.fit(X_train_fs,y_train)
X_test_fs = fs.transform(X_test)
print(dt.score(X_test_fs,y_test))
运行结果如下:Traceback (most recent call last):
File "D:\Python35\demo\titanic_select.py", line 2, in <module>
titanic = pd.read_csv('../Datasets/Breast-Cancer/titanic.txt')
File "D:\Python35\lib\site-packages\pandas\io\parsers.py", line 709, in parser_f
return _read(filepath_or_buffer, kwds)
File "D:\Python35\lib\site-packages\pandas\io\parsers.py", line 449, in _read
parser = TextFileReader(filepath_or_buffer, **kwds)
File "D:\Python35\lib\site-packages\pandas\io\parsers.py", line 818, in __init__
self._make_engine(self.engine)
File "D:\Python35\lib\site-packages\pandas\io\parsers.py", line 1049, in _make_engine
self._engine = CParserWrapper(self.f, **self.options)
File "D:\Python35\lib\site-packages\pandas\io\parsers.py", line 1695, in __init__
self._reader = parsers.TextReader(src, **kwds)
File "pandas\_libs\parsers.pyx", line 402, in pandas._libs.parsers.TextReader.__cinit__
File "pandas\_libs\parsers.pyx", line 718, in pandas._libs.parsers.TextReader._setup_parser_source
FileNotFoundError: File b'../Datasets/Breast-Cancer/titanic.txt' does not exist
>>> 提示找不到相应的数据集,导入数据集,运行结果如下:
474
0.8267477203647416
0.8206686930091185
[0.85063904 0.85673057 0.87501546 0.88622964 0.86692435 0.87403628
0.87302618 0.86998557 0.86691404 0.87200577 0.86894455 0.86795506
0.86692435 0.86691404 0.86285302 0.86689342 0.86083282 0.86387343
0.86694496 0.8608122 0.86284271 0.86284271 0.86487322 0.86388374
0.86997526 0.86896516 0.86894455 0.86589363 0.87200577 0.86690373
0.86588332 0.86996496 0.86996496 0.86588332 0.87404659 0.86994434
0.86488353 0.87100598 0.87201608 0.86993403 0.87199546 0.86994434
0.8608122 0.86591424 0.85878169 0.86589363 0.86388374 0.8618223
0.8598021 0.85981241]
超参数预估结果曲线图如下:
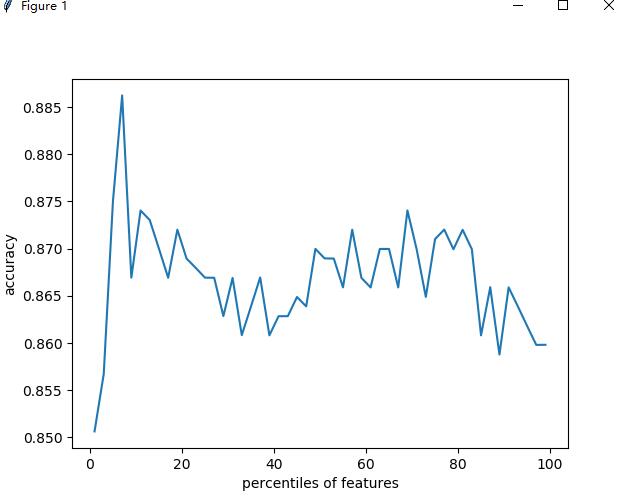
从图示中可以看出,当超参数调整为7时,预估精度达到最高,相应的预估精度结果如下:
Optimal accuarcy of feature is
0.8571428571428571














 1677
1677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









