







本篇文章将实现前面学到的优化技术,并以更系统的方式对模型进行性能分析。我们将评估配置变更的影响,以及不同请求模式对推理能力的影响,并生成结构化报告,对比两个模型的性能:
- 使用
TorchScript的模型(未启用Triton高级功能) - 使用
TensorRT ONNX的模型(启用了前面介绍的关键优化功能)
除了分析前面课程中的基础指标(吞吐量和延迟),我们还将进一步探讨影响延迟的因素,如网络通信等。最后,我们还将介绍一些用于监控和管理推理服务性能的工具,并说明它们如何支持更高级的功能,如自动扩缩容。
本文用到的脚本文件可在Triton模型部署相关脚本文件下载。
1 评估优化效果
我们使用的性能测试工具除了在终端显示结果外,还会将数据以表格格式保存到以下路径中:./results/${MODEL_NAME}/results${RESULTS_ID}_${TIMESTAMP}.csv。为了评估不同优化策略的效果,我们可以利用之前生成的日志文件。
1.1 对模型进行分析
我们之前已经运行了bertQA-torchscript和bertQA-onnx-trt-dynbatch两个模型,因此应该已经生成了相关的日志文件。现在查看这些模型的日志目录:
# 查看 bertQA-torchscript 模型的结果文件夹
!ls ./results/bertQA-torchscript/
# 查看 bertQA-onnx-trt-dynbatch 模型的结果文件夹
!ls ./results/bertQA-onnx-trt-dynbatch
通过这两个模型对应的CSV文件,我们可以生成一些分析的图表。
1、bertQA-onnx-trt-dynbatch
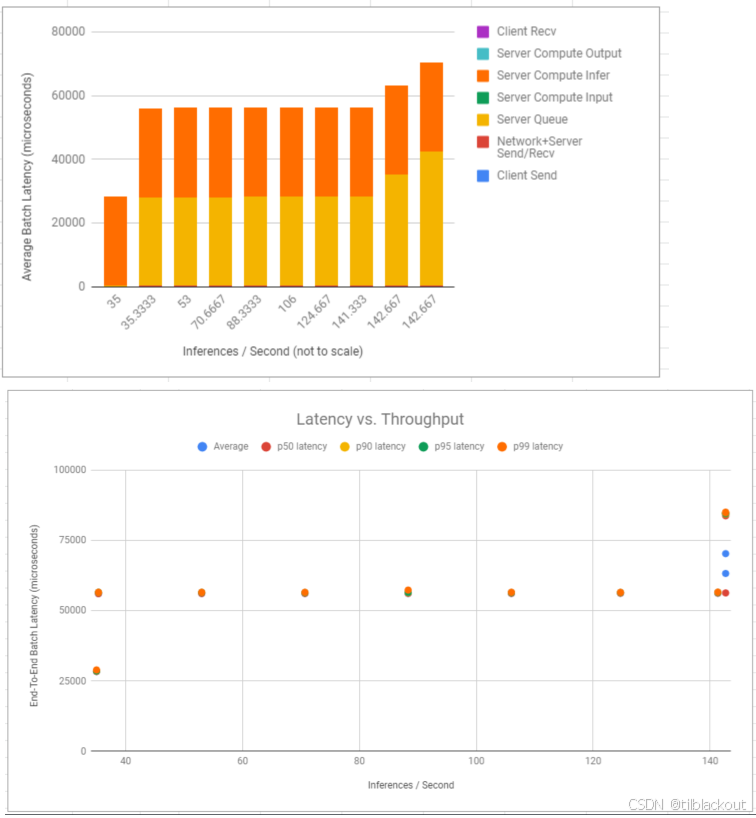
(1)平均延迟组成(Components of Latency)
- 延迟被分成多个阶段,其中
Server Queue + Compute Input + Compute Infer占据了大部分时间。 - 随着吞吐量增加(x轴),整体延迟变化相对平稳,这表明动态批处理+高并发有效分摊了开销。
- 动态批处理让请求可以被快速合并并行处理,最大吞吐量达到了 140+ inferences/sec,具有良好的扩展性。
(2)延迟 vs 吞吐量(Latency vs Throughput)
- 即使在高吞吐量时,延迟的 p50(排在中间50%的那个推理请求的延迟)、p90、p99都比较集中,没有明显恶化,说明系统稳定。
- 表现出高吞吐、低延迟波动的理想状态。
性能表现非常优秀,得益于TensorRT 加速 + 动态批处理,既压低了平均延迟,又保持了高吞吐。
2、bertQA-torchscript(该模型是在batch size=8的设置下运行的)
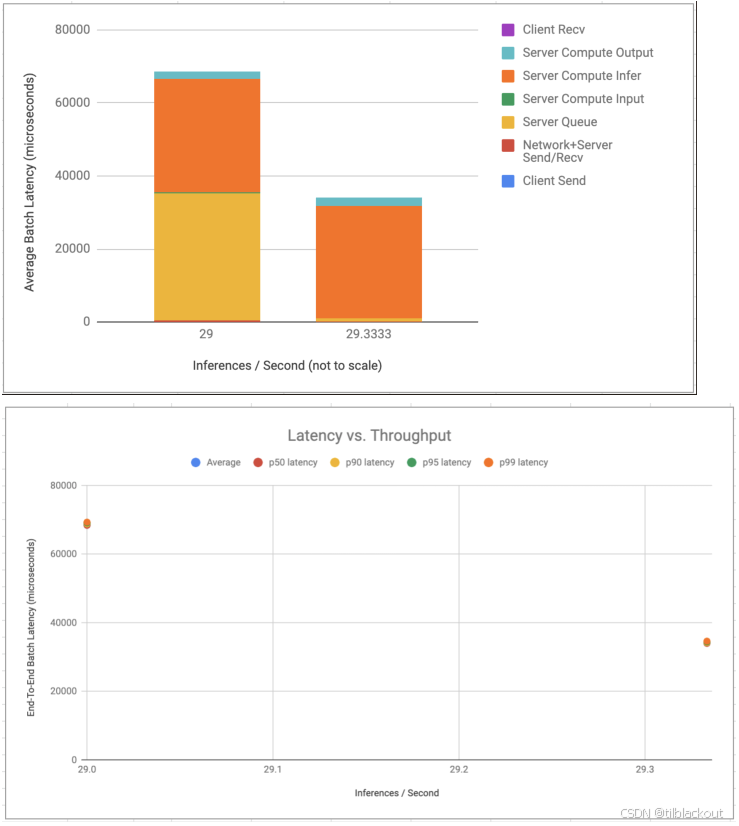
(1)平均延迟组成
- 请求数量很少(吞吐只有约29次/s),但每个请求的平均延迟极高,达到了37~67毫秒。
- 其中大部分时间花在了Server Compute Infer阶段,说明模型推理效率低。
(2)延迟 vs 吞吐量
- 图中几乎只有两点,表明系统没有承受更多负载,无法体现扩展性。
- 延迟几乎不变,但吞吐也完全没提高,说明处理能力被限制在单线程或模型自身性能上。
该模型未启用任何Triton优化功能,虽然设置了 batch=8,但没有并发、没有动态批处理,整体性能瓶颈明显。
2 监控和应对性能波动
了解推理服务器的性能不仅在初始部署阶段重要,在系统运行生命周期中也同样关键。能够收集服务器性能指标不仅有助于排查问题,还为更高级功能(如自动扩容)打下基础。
2.1 通用推理服务器部署架构
下图展示了Triton部署架构的简化示意。结合Kubernetes等技术,你可以轻松配置一个自动根据负载变化扩展的推理系统,甚至支持将多余负载转移至云端。
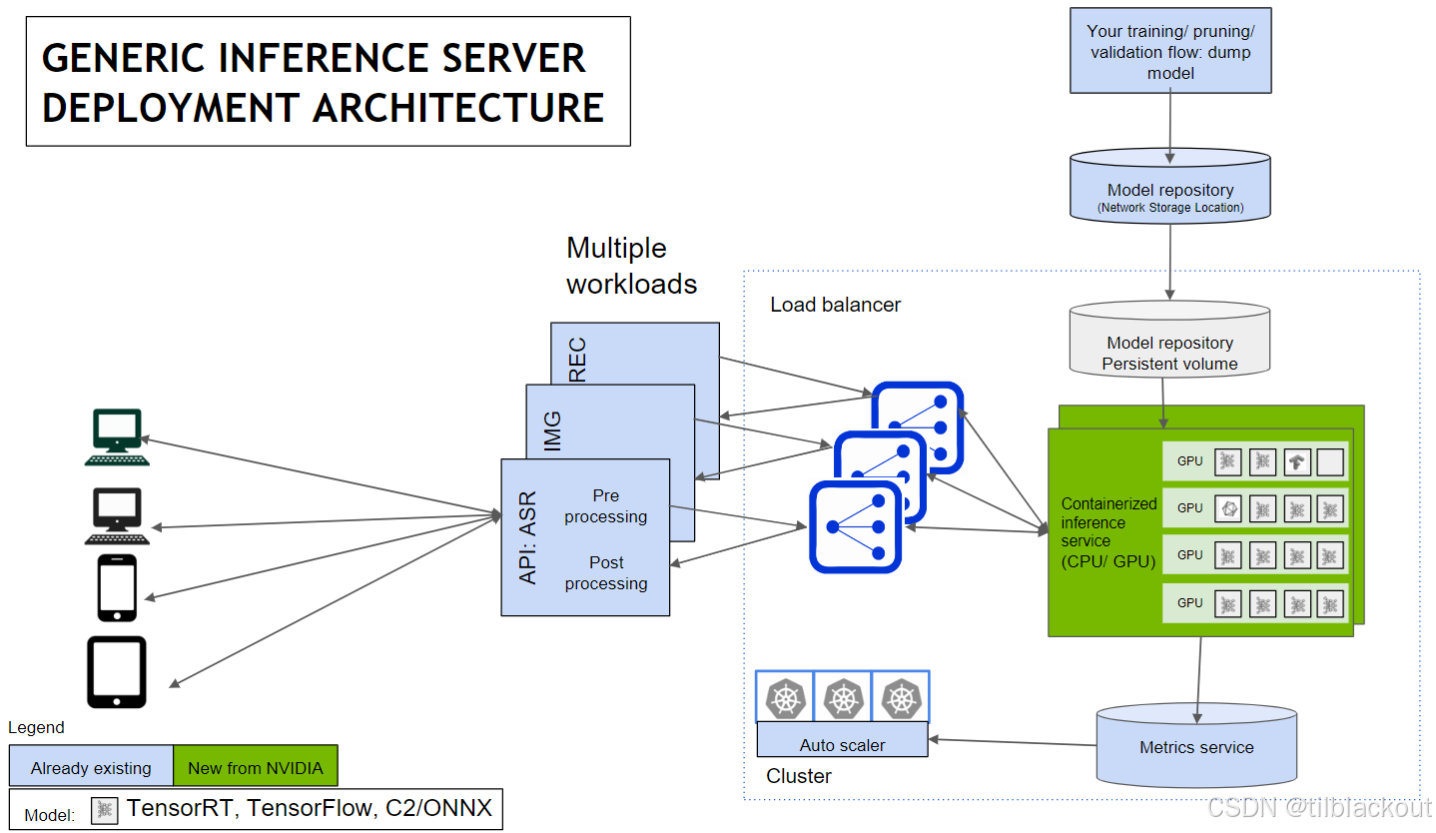
1、用户端请求
来自多个设备(电脑、手机、平板等)的推理请求通过 API 接口(比如语音识别 API、图像处理 API)发送到服务器。
这些请求会进入统一的入口服务(如 API: ASR、IMG、REC),在这里完成:
- 预处理(Pre-processing):如图像缩放、文本清洗
- 后处理(Post-processing):如输出格式转换、结果筛选
2. 负载均衡器(中间)
请求经过负载均衡器(Load balancer),它会把任务平均分配给后端多个推理服务节点,防止某个节点压力过大。
3. 推理服务容器(右侧绿色部分)
每个服务节点运行的是容器化的推理服务(如Triton),这些服务可以使用:
- GPU(进行高效推理)
- CPU(处理轻量任务或调度)
它们从共享的模型仓库(Model repository)中加载模型,例如TensorRT、TensorFlow、ONNX模型。
4. 自动扩缩容(下方)
结合右下角的Kubernetes控制器(自动扩缩组件auto scaler),系统会根据负载动态调整 GPU 节点数量:
- 请求变多则自动增加推理节点;请求变少则自动释放资源节省成本
Kubernetes 是一个容器调度平台,可以自动部署、管理和扩展服务,是现代 AI 服务部署的核心工具之一。
5. 性能监控(最下方)
所有服务运行状态(如吞吐、延迟、GPU 使用率)会被记录到Metrics 服务中,用于运维监控和自动扩容的依据。
2.2 查看Prometheus指标
Triton 默认会通过8002端口提供Prometheus性能指标接口,包括 GPU 功耗、显存使用、请求计数、延迟等信息。详细指标文档见 Triton Metrics 文档。
我们可以通过下面指令查询一下之前运行时记录的性能指标:
# 设置 Triton Server 主机名,并检查其是否已准备就绪
tritonServerHostName = "triton"
!./utilities/wait_for_triton_server.sh {tritonServerHostName}
# 使用 curl 请求 Prometheus 暴露的指标接口
prometheus_url = tritonServerHostName + ":8002/metrics"
!curl -v {prometheus_url}
Prometheus输出是一组指标,每个指标采用以下格式:
# HELP <metric_name 和说明>
# TYPE <metric_name 和类型>
metric_name{gpu_uuid="GPU-xxxxxx",...} <数值>
示例:推理计数
下面的输出表示 bertQA-onnx-trt-dynbatch 模型目前已执行了10105次推理,而 bertQA-torchscript 模型只执行了717次。
# HELP nv_inference_count Number of inferences performed
# TYPE nv_inference_count counter
nv_inference_count{gpu_uuid="GPU-640c6e00-43dd-9fae-9f9a-cb6af82df8e9",model="bertQA-onnx-trt-dynbatch",version="1"} 10105.000000
nv_inference_count{gpu_uuid="GPU-640c6e00-43dd-9fae-9f9a-cb6af82df8e9",model="bertQA-torchscript",version="1"} 717.000000
示例:GPU 功耗
下面的指标表示当前GPU功耗大约为40瓦。
# HELP nv_gpu_power_usage GPU power usage in watts
# TYPE nv_gpu_power_usage gauge
nv_gpu_power_usage{gpu_uuid="GPU-640c6e00-43dd-9fae-9f9a-cb6af82df8e9"} 39.958000
3 总结
本文通过实测与分析,系统评估了Triton推理服务器的三项关键优化技术:并发执行、动态批处理与TensorRT加速。我们对比了启用与未启用优化功能的模型性能差异,发现优化后的模型在吞吐量和延迟上均有显著提升。随后,我们介绍了推理服务在生产环境中的部署架构,以及如何利用Kubernetes和Prometheus实现服务的自动扩缩容与性能监控。
下一篇文章,我们将学习如何构建利用 Triton 功能的自定义应用…



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











