







 本文详细介绍了TensorFlow的计算图概念,包括操作、张量、变量和会话。计算图中,操作作为算法的基础单元,张量表示数据流动,变量用于存储可变数据。会话是执行计算的容器,负责资源管理和数据输入。文章还讨论了执行过程中的计算设备选择、任务分配算法以及优化策略,如子图消除和调度优化,旨在提升性能。同时,提到了反向传播在计算图中的应用,简化了深度学习模型的训练过程。
本文详细介绍了TensorFlow的计算图概念,包括操作、张量、变量和会话。计算图中,操作作为算法的基础单元,张量表示数据流动,变量用于存储可变数据。会话是执行计算的容器,负责资源管理和数据输入。文章还讨论了执行过程中的计算设备选择、任务分配算法以及优化策略,如子图消除和调度优化,旨在提升性能。同时,提到了反向传播在计算图中的应用,简化了深度学习模型的训练过程。
1 计算图
在TensorFlow中,算法都被表示成计算图(computational graphs)。计算图也叫数据流图,可以把计算图看做是一种有向图,图中的节点表示操作,图中的边代表在不同操作之间的数据流动。
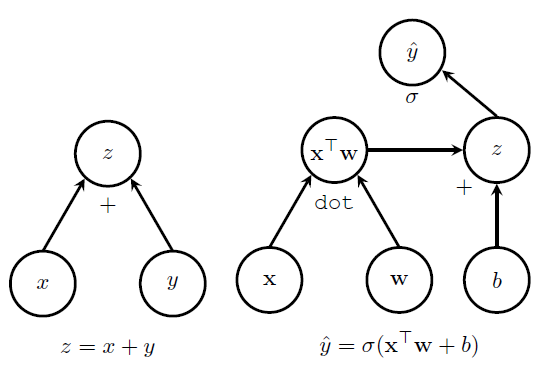
如图所示,左边的图表示 z=x+y 。从图中可以看到,x y z是图中的三个节点,x和y分别有一个箭头指到z,在z节点的下方有一个+号,表明是一个加法操作,因此最后的输出结果就是 z=x+y 。右图是一种相对复杂点的情况,随着计算图逐步分析可以得到 y^=σ(xTw+b) 。
在这样的数据流图中,有四个主要的元素:
* 操作(operations)
* 张量(tensors)
* 变量(variables)
* 会话(sessions)
操作
把算法表示成一个个操作的叠加,可以非常清晰地看到数据之间的关系,而且这样的基本操作也具有普遍性。在TensorFlow中,当数据流过操作节点的时候就可以对数据进行操作。一个操作可以有零个或多个输入,产生零个或多个输出。一个操作可能是一次数学计算,一个变量或常量,一个数据流走向控制,一次文件IO或者是一次网络通信。其中,一个常量可以看做是没有输入,只有一个固定输出的操作。具体操作如下所示:
| 操作类型 | 例子 |
|---|---|
| 元素运算 | Add,Mul |
| 矩阵运算 | MatMul,MatrixInverse |
| 数值产生 | Constant,Variable |
| 神经网络单元 | SoftMax,ReLU,Conv2D |
| I/O | Save,Restore |
每一种操作都需要相对应的底层计算支持,比如在GPU上使用就需要实现在GPU上的操作符,在CPU上使用就要实现在CPU上的操作符。
张量
在计算图中,每个边就代表数据从一个操作流到另一个操作。这些数据被表示为张量,一个张量可以看做是多维的数组或者高维的矩阵。
关于TensorFlow中的张量,需要注意的是张量本身并没有保存任何值,张量仅仅提供了访问数值的一个接口,可以看做是数值的一种引用。在TensorFlow实际使用中我们也可以发现,在run之前的张量并没有分配空间,此时的张量仅仅表示了一种数值的抽象,用来连接不同的节点,表示数据在不同操作之间的流动。
TensorFlow中还提供了SparseTensor数据结构,用来表示稀疏张量。
变量
变量是计算图中可以改变的节点。比如当计算权重的时候,随着迭代的进行,每次权重的值会发生相应的变化,这样的值就可以当做变量。在实际处理时,一般把需要训练的值指定为变量。在使用变量的时候,需要指定变量的初始值,变量的大小和数据类型就是根据初始值来推断的。
在构建计算图的时候,指定一个变量实际上需要增加三个节点:
* 实际的变量节点
* 一个产生初始值的操作,通常是一个常量节点
* 一个初始化操作,把初始值赋予到变量
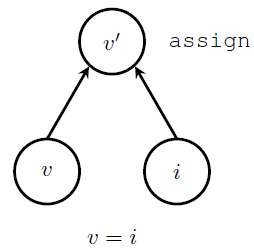
如图所示,v代表的是实际的变量,i是产生初始值的节点,上面的assign节点将初始值赋予变量,assign操作以后,产生已经初始化的变量值v'。
会话
在TensorFlow中,所有操作都必须在会话(session)中执行,会话负责分配和管理各种资源。在会话中提供了一个run方法,可以用它来执行计算图整体或者其中的一部分节点。在进行run的时候,还需要用feed_dict把相关数据输入到计算图。
当run被调用的时候,TensorFlow将会从指定的输出节点开始,向前查找所有的依赖界节点,所有依赖节点都将被执行。这些操作随后将被分配到物理执行单元上(比如CPU或GPU),这种分配规则由TensorFlow中的分配算法决定。
2 执行
在执行的时候,TensorFlow支持两种方式:一种是单机版本,可以在单机上支持多个计算设备,还有一种是分布式版本,支持多机多设备。在TensorFlow刚出来的时候,只支持第一种方式,后来开源了分布式版本。
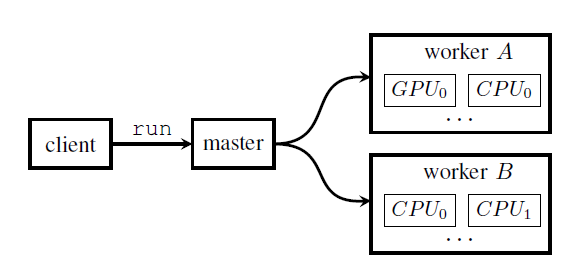
当client发出run请求时,master会将这个请求分配到不同的worker上,这些worker负责监控具体的计算设备。
计算设备
所有的计算任务最终都将分配到实际的硬件上执行。除了CPU和GPU之外,TensorFlow也支持自定义硬件,比如谷歌自己使用的TPU(Tensor Processing Unit)。一个worker需要管理多个设备,所以这些设备的名称需要加上wo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









