







rand 和 mt19937 介绍
众所周知,程序无法模拟出真正的随机数,所以我们所说的随机数都是相对随机的伪随机数。
rand 是一种常用的随机数,C++ 初学者一般接触的都是他,但是他有缺点,随机性不高,周期短,质量低。
Mt19937 用法与 rand 一样但是他随机性高,周期长,质量高。
先放上进行实验对比的两个代码:
我们通过多次随机数(0 到 100 的范围内随机)。
- rand 随机数
mt19937 myrand(time(0)); #define rd(l,r) (rand()%(r-l+1)+l) void solve(){ srand(time(0)); freopen("rd3.txt ","w",stdout); int n = 1e9; int sum = 0; For(i,1,n){ int tmp = rd(0,100); sum += tmp; cout<<(double)sum / (double) i<<endl; } cout<<(double)sum/double(n); }
- mt19937 随机数
mt19937 myrand(time(0)); #define rd(l,r) (myrand()%(r-l+1)+l) void solve(){ srand(time(0)); freopen("mt3.txt ","w",stdout); int n = 1e9; int sum = 0; For(i,1,n){ int tmp = rd(0,100); sum += tmp; cout<<(double)sum / (double) i<<endl; } cout<<(double)sum/double(n); }
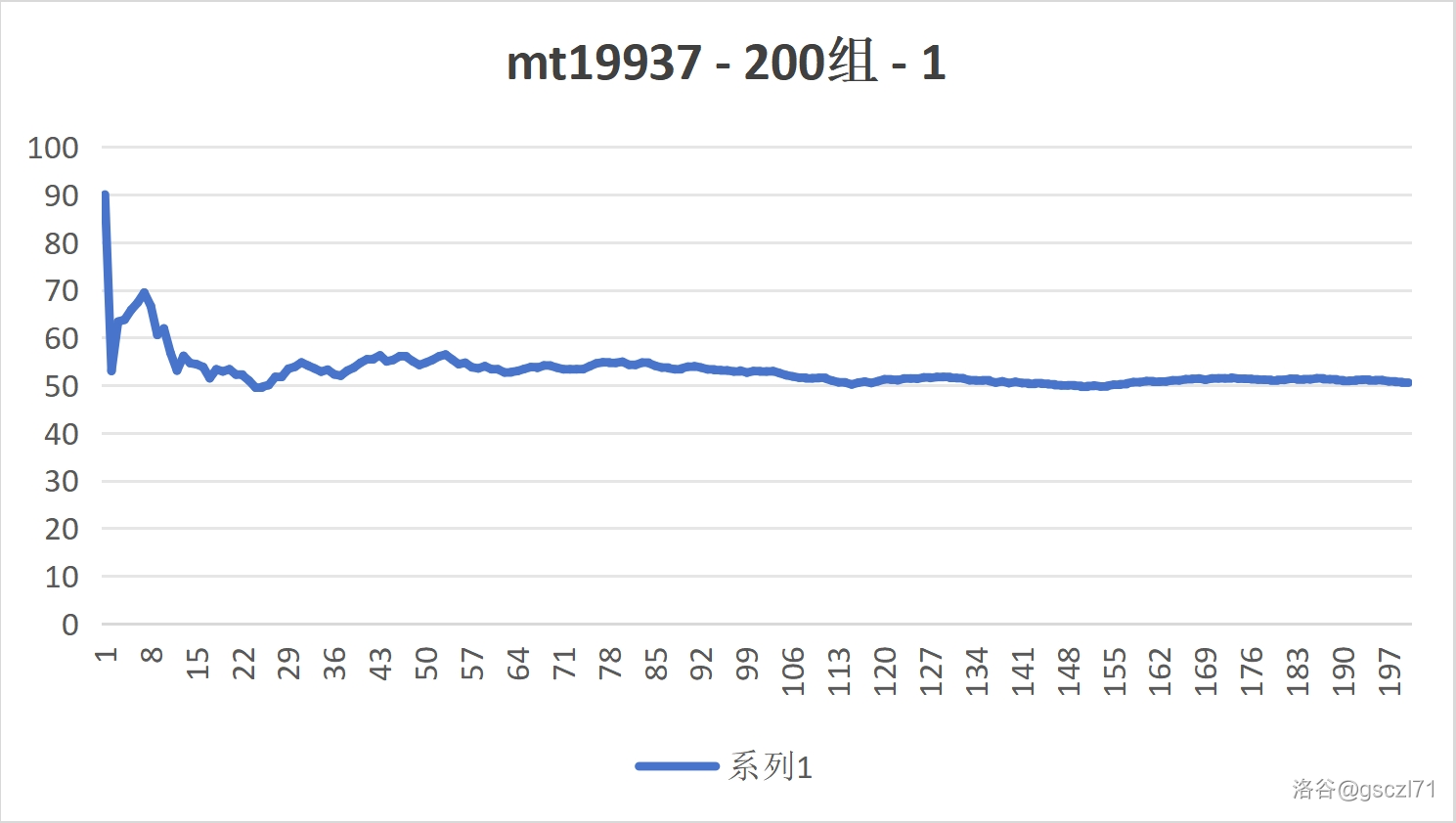
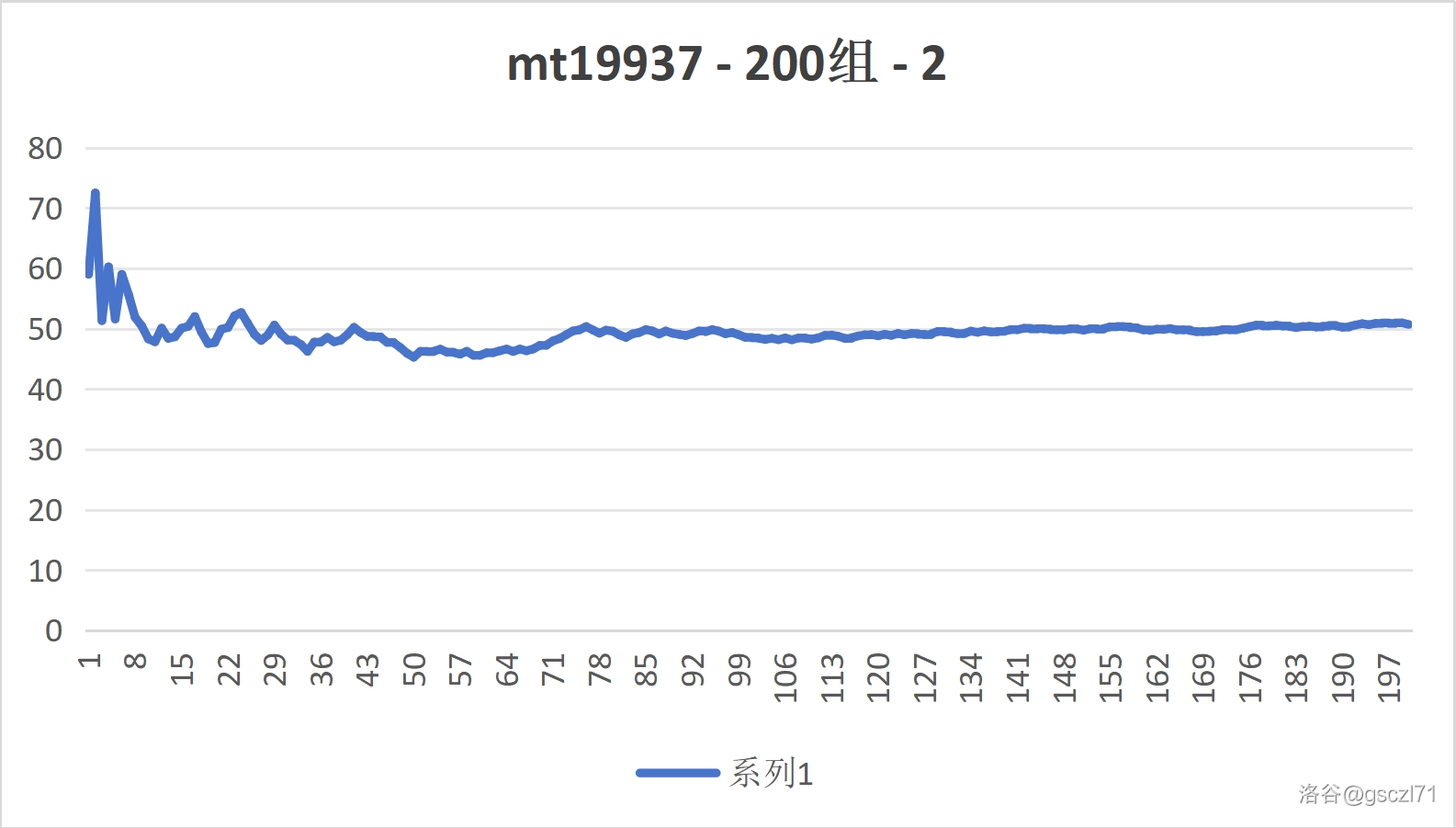
Part 1 对比随机数的实时平均数(200次)
- Mt19937
- Rand
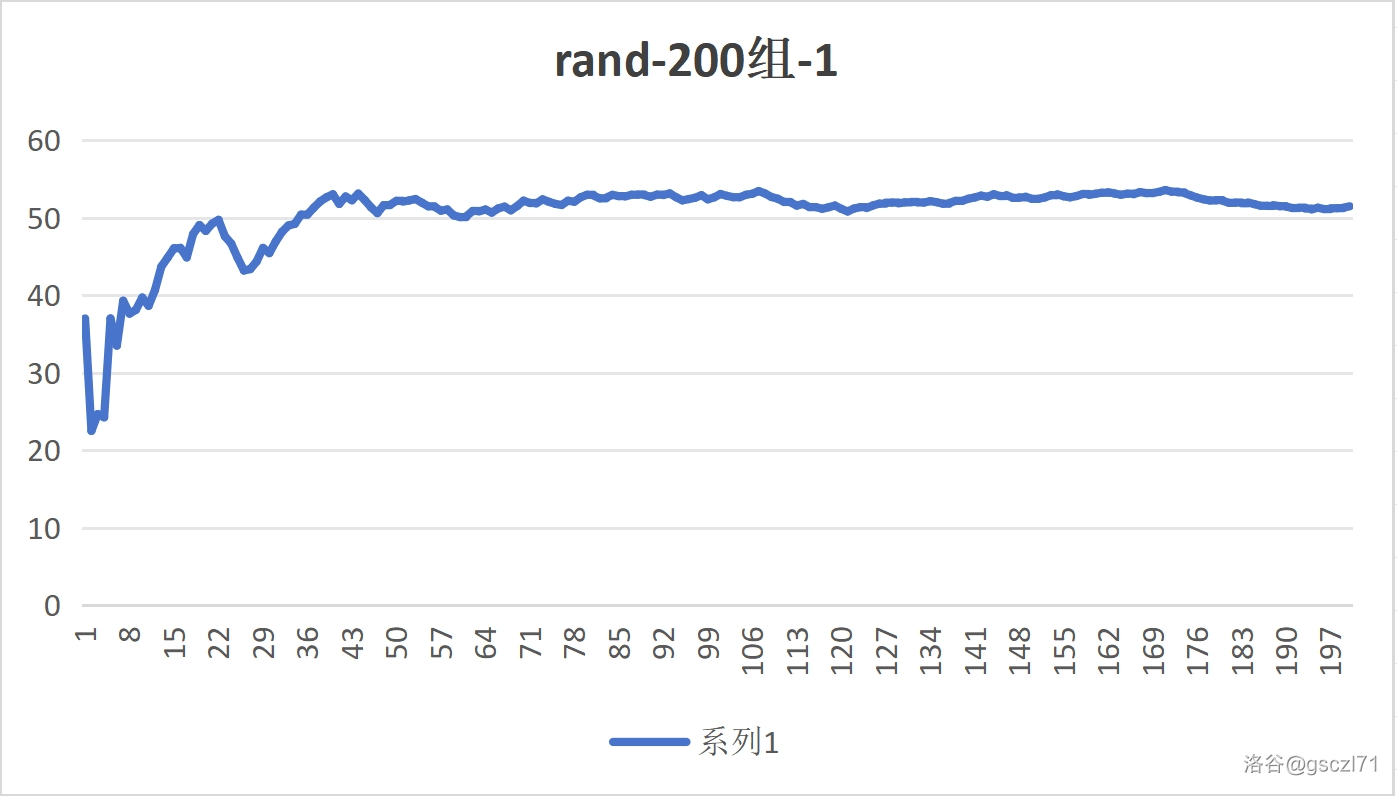
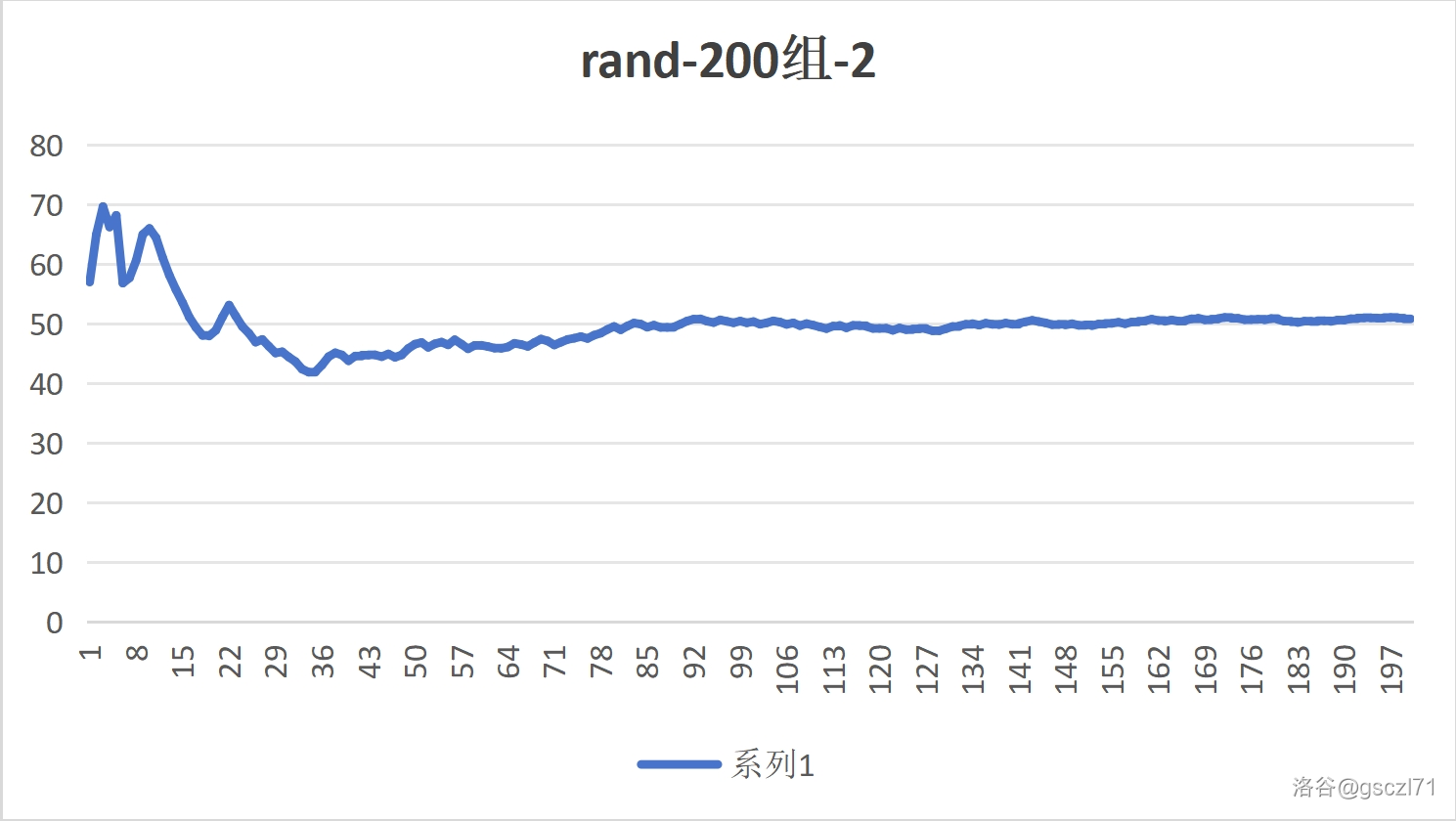
通过用眼睛直接看,我们可以感受到他们都逐渐趋于中间的一个数 50,那是理论上的平均数,证明,在多次实验之后,频率 趋近于 概率。
此时,两个随机方法的区别都不大,都有不小的波动。
因为次数太少了。接下来,增大次数。
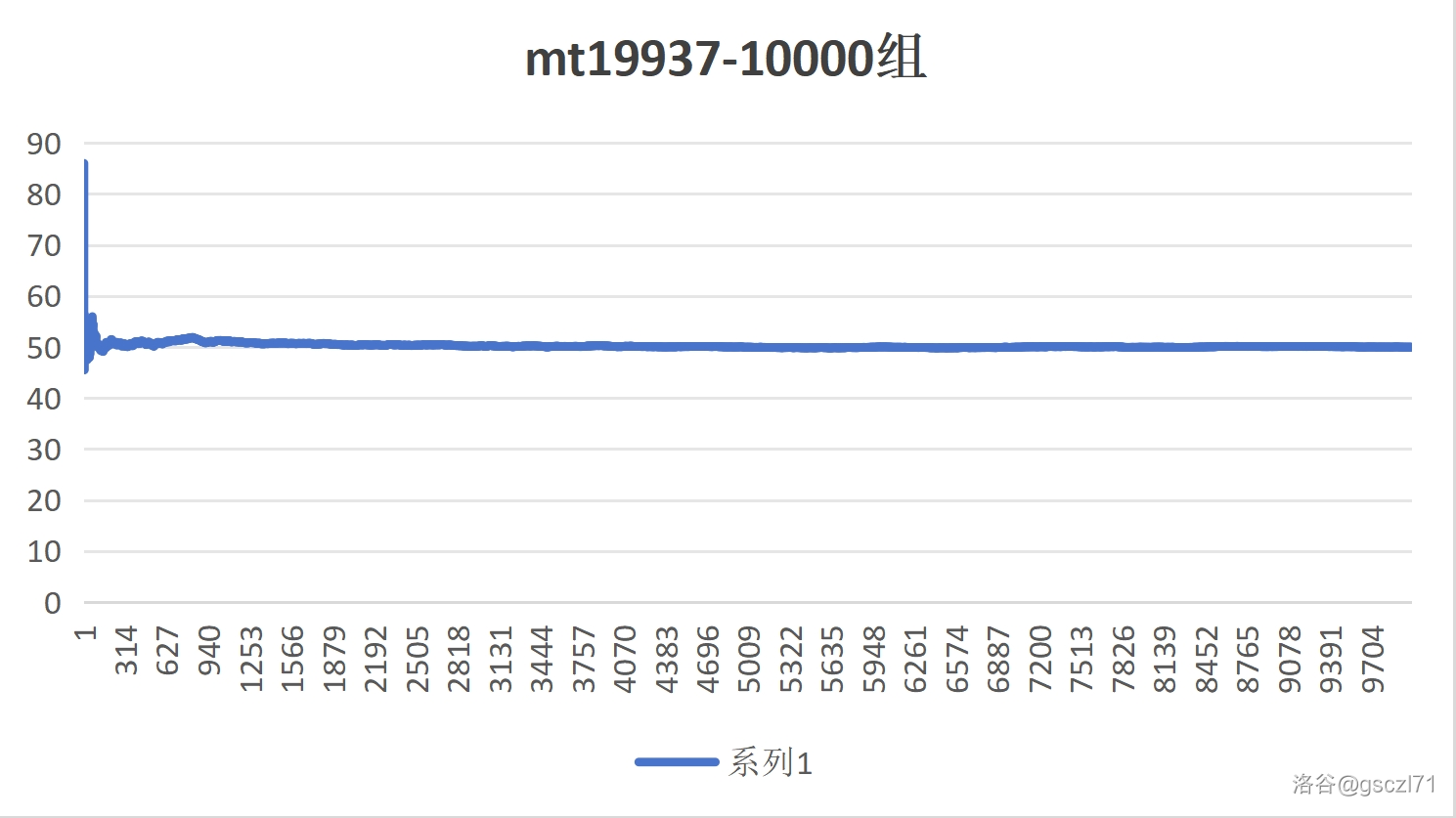
Part 2 对比随机数的实时平均数(10000次)
- Mt19937
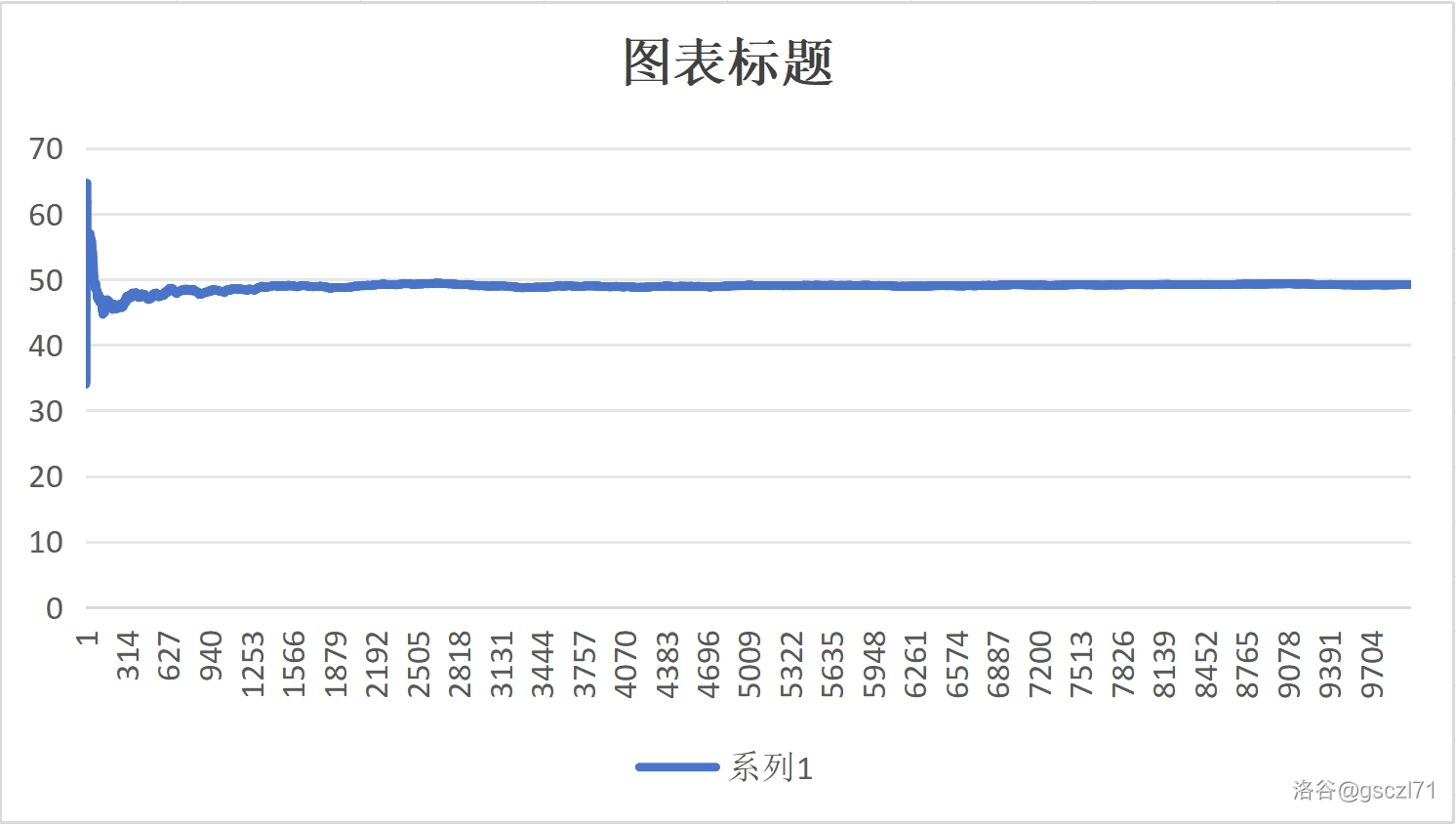
- Rand
由此可见,前者大约在 1000 次的时候就已经趋近于一个常数了,直线也不再曲折
而后者在 4000 到 5000 次的时候还有一些波折。
因此看得出来 Mt19937 更加稳定,也就是他的随机性更加分布均匀,更加“随机”。显然前者要优于后者。
Part 3 对比最后的平均数(10000000次)
我们对两个代码进行了 107 次随机数。
结果如下:
-
Mt19937
50.0005,50.0002,49.9965,49.9984。
平均数:49.9989。与理论答案相差 0.0011。- rand
49.9637,49.9656,49.96,49.9592。
平均数:49.962125,与理论答案相差 0.037875。约为 0.0379。
显然相差越小,随机数质量更高,因此 Mt19937 有优于rand。
虽然相差小,但是在 Sa 种有时候取决了你的程序是否通过。
如果想看 Sa,请看:
Part 4 对比最后的平均数(1000000000次)
这一次,我们进行了 109 次随机数,随机数逐渐稳定,几乎可以达到一个常数,精度也非常高,我们看实验结果吧!
mt19937 :50.001
rand:49.9613
尽管次数很多很多,但是 rand 却依然保持在 49.96 左右,证明,rand 还是有一定的偏差,而且不小。达到 0.04,而 mt 的误差我认为几乎可以省略。
总结
通过各种实验数据的对比,mt19937 的随机数质量远高于rand,所以我们在写代码或在写对拍的时候尽量用 mt19937,提高随机数质量。
















 3869
3869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









