







 本文介绍了在365天深度学习训练营中,作者使用VGG16模型实现猫狗识别的过程,详细讲解了VGG网络结构,并重点展示了如何使用model.train_on_batch方法进行训练。
本文介绍了在365天深度学习训练营中,作者使用VGG16模型实现猫狗识别的过程,详细讲解了VGG网络结构,并重点展示了如何使用model.train_on_batch方法进行训练。
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
T8 猫狗识别
前言
前面已经对tensorflow训练框架已经有了熟悉的了解,这周主要使用VGG16实现猫狗识别,同时学习model.train_on_batch方法。
VGG网络介绍

VGG16总共有16层,13个卷积层和3个全连接层,第一次经过64个卷积核的两次卷积后,采用一次池化,第二次经过两次128个卷积核卷积后,再采用池化,再重复两次三个512个卷积核卷积后,再池化,最后经过三次全连接。
网络搭建
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
def VGG16(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 1st block
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)
# 2nd block
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)
# 3rd block
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)
# 4th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)
# 5th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)
# full connection
x = Flatten()(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)
model = Model(input_tensor, output_tensor)
return model
model=VGG16(1000, (img_width, img_height, 3))
model.summary()

模型训练
from tqdm import tqdm
import tensorflow.keras.backend as K
epochs = 10
lr = 1e-4
# 记录训练数据,方便后面的分析
history_train_loss = []
history_train_accuracy = []
history_val_loss = []
history_val_accuracy = []
for epoch in range(epochs):
train_total = len(train_ds)
val_total = len(val_ds)
"""
total:预期的迭代数目
ncols:控制进度条宽度
mininterval:进度更新最小间隔,以秒为单位(默认值:0.1)
"""
with tqdm(total=train_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=1,ncols=100) as pbar:
lr = lr*0.92
K.set_value(model.optimizer.lr, lr)
for image,label in train_ds:
history = model.train_on_batch(image,label)
train_loss = history[0]
train_accuracy = history[1]
pbar.set_postfix({"loss": "%.4f"%train_loss,
"accuracy":"%.4f"%train_accuracy,
"lr": K.get_value(model.optimizer.lr)})
pbar.update(1)
history_train_loss.append(train_loss)
history_train_accuracy.append(train_accuracy)
print('开始验证!')
with tqdm(total=val_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=0.3,ncols=100) as pbar:
for image,label in val_ds:
history = model.test_on_batch(image,label)
val_loss = history[0]
val_accuracy = history[1]
pbar.set_postfix({"loss": "%.4f"%val_loss,
"accuracy":"%.4f"%val_accuracy})
pbar.update(1)
history_val_loss.append(val_loss)
history_val_accuracy.append(val_accuracy)
print('结束验证!')
print("验证loss为:%.4f"%val_loss)
print("验证准确率为:%.4f"%val_accuracy)
model.train_on_batch 是 Keras 模型类中的一个方法,用于在一个批次上执行训练步骤。它的基本用法如下:
loss, metrics = model.train_on_batch(x, y)
x 是输入数据,可以是 Numpy 数组、列表或字典(具体格式取决于模型的输入层)。
y 是目标数据,同样可以是 Numpy 数组、列表或字典(具体格式取决于模型的输出层)。
这个方法会返回两个值:
loss 表示模型在这个批次上的损失值。
metrics 是一个列表,包含模型定义的各种指标的值。如果模型没有定义指标,这个值通常是空的列表。
注意:在最新版本的 Keras 中,train_on_batch 方法已经被废弃,推荐使用更加通用的 train_step 方法,这个方法同时支持自定义训练循环和自定义损失函数
训练结果

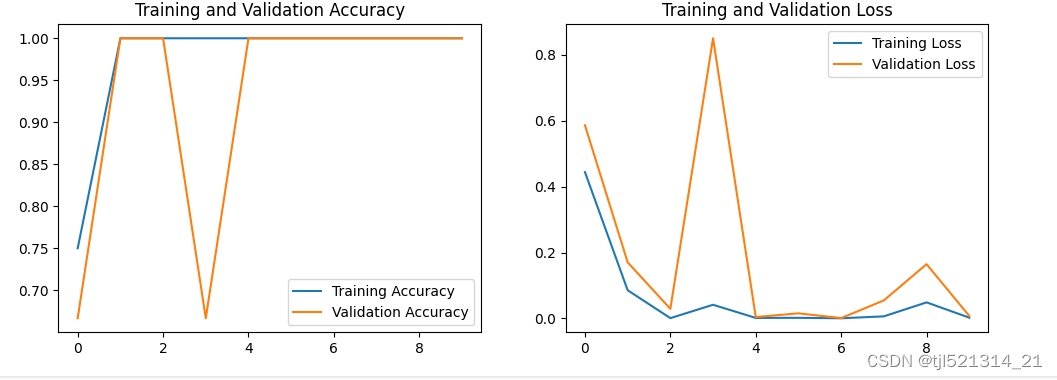
总结
这周熟悉了处理fit方法的另外一种训练方法,model.train_on_batch方法,这种方法封装程度低可操作性强,通过这种方法使用VGG网络实现了猫狗识别。















 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









