







 本文详细介绍了如何使用TensorFlow的image_dataset_from_directory函数加载自己的天气数据集,包括数据预处理、神经网络构建、编译模型、训练过程以及结果分析。作者通过实际操作展示了如何在深度学习项目中应用TensorFlow进行模型训练。
本文详细介绍了如何使用TensorFlow的image_dataset_from_directory函数加载自己的天气数据集,包括数据预处理、神经网络构建、编译模型、训练过程以及结果分析。作者通过实际操作展示了如何在深度学习项目中应用TensorFlow进行模型训练。
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
前言
上周用官方提供的数据集对tensorflow学习框架有了大致了解,这周使用自己的数据集跑一下这个代码,平时在使用时基本上也是使用自己的数据集。
数据集介绍
这里有天气数据集有四种天气文件结构如下:

导入数据集
import matplotlib.pyplot as plt
import os,PIL
# 设置随机种子尽可能使结果可以重现
import numpy as np
np.random.seed(1)
# 设置随机种子尽可能使结果可以重现
import tensorflow as tf
tf.random.set_seed(1)
from tensorflow import keras
from tensorflow.keras import layers,models
import pathlib
data_dir = "./drive/MyDrive/My_files/365_program/weather_photos/"
data_dir = pathlib.Path(data_dir)
batch_size = 32
img_height = 180
img_width = 180
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)
#['cloudy', 'rain', 'shine', 'sunrise']
函数学习
tf.keras.preprocessing.image_dataset_from_directory
tf.keras.preprocessing.image_dataset_from_directory(
directory, # 数据集所在的目录路径
labels='inferred', # 标签的处理方式,'inferred' 表示从子目录中推断,也可以提供一个标签列表或标签文件的路径
label_mode='int', # 标签的数据类型,'int' 表示整数标签,'categorical' 表示独热编码,'binary' 表示二进制标签,None 表示不生成标签
class_names=None, # 类别名称列表,用于映射标签的字符串表示到整数标签
color_mode='rgb', # 图像的颜色模式,'rgb' 表示彩色,'grayscale' 表示灰度
batch_size=32, # 批量大小,每个批次的样本数
image_size=(256, 256), # 图像的目标大小,形状为 (height, width)
shuffle=True, # 是否在每个 epoch 开始时随机打乱数据
seed=None, # 随机种子,用于打乱数据
validation_split=None, # 用于验证集的数据拆分比例,例如 0.2 表示将 20% 的数据用于验证集
subset=None, # 选择数据集的子集,'training' 表示训练集,'validation' 表示验证集
interpolation='bilinear' # 图像插值方法,'bilinear' 表示双线性插值,'nearest' 表示最近邻插值
)
tf.keras.preprocessing.image_dataset_from_directory(
directory, # 数据集所在的目录路径
labels='inferred', # 标签的处理方式,默认为 'inferred'
label_mode='int', # 标签的数据类型,默认为 'int'
class_names=None, # 类别名称列表,默认为 None
color_mode='rgb', # 图像的颜色模式,默认为 'rgb'
batch_size=32, # 批量大小,默认为 32
image_size=(256, 256), # 图像的目标大小,默认为 (256, 256)
shuffle=True, # 是否在每个 epoch 开始时随机打乱数据,默认为 True
seed=None, # 随机种子,用于打乱数据,默认为 None
validation_split=None, # 用于验证集的数据拆分比例,默认为 None
subset=None, # 选择数据集的子集,默认为 None
interpolation='bilinear' # 图像插值方法,默认为 'bilinear'
)
这里对比一下pytorch加载数据集的方法
torch.utils.data .DataLoader
torch.utils.data.DataLoader 是 PyTorch 中用于批量加载数据的工具,主要用于处理和封装数据,方便进行训练。下面是 DataLoader 的主要参数和返回值:
主要参数:
dataset (Dataset):
数据集对象,通常是继承自 torch.utils.data.Dataset 的类的实例。
batch_size (int, optional):
每个批次中的样本数。默认值为 1。
shuffle (bool, optional):
是否在每个 epoch 开始时对数据进行随机排序。默认值为 False。
sampler (Sampler or Iterable, optional):
定义从数据集中提取样本的策略。如果指定,忽略 shuffle 参数。默认为 SequentialSampler。
batch_sampler (Sampler or Iterable, optional):
与 sampler 相似,但一次返回一个批次的索引列表。如果指定,忽略 batch_size,shuffle 和 sampler 参数。
num_workers (int, optional):
用于数据加载的子进程数。默认值为 0,表示在主进程中加载数据。
collate_fn (callable, optional):
用于将样本列表转换为批次的函数。默认使用 default_collate,它将样本列表转换为张量。
pin_memory (bool, optional):
如果为 True,将数据加载到 CUDA 固定内存中,可以加速数据传输。默认值为 False。
drop_last (bool, optional):
如果为 True,当样本数量不能被批次大小整除时,丢弃最后一个小于批次大小的批次。默认值为 False。
timeout (numeric, optional):
数据加载器超时时间,用于检测数据加载是否出现死锁。默认值为 0。
worker_init_fn (callable, optional):
每个 worker 初始化函数。在 worker 进程启动时调用。默认为 None。
返回值:
DataLoader 返回一个可迭代对象,可以通过迭代来获取每个批次的数据。
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
for batch in dataloader:
inputs, labels = batch
# 在此处执行训练逻辑
DataLoader 对象本身也是一个可迭代对象,可以通过 iter(dataloader) 获取迭代器,然后使用 next(iterator) 获取下一个批次。
dataloader_iterator = iter(dataloader)
batch = next(dataloader_iterator)
查看数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
shuffle(buffer_size, seed=None, reshuffle_each_iteration=None):
shuffle 方法用于对数据进行随机打乱,以提高模型训练的效果。它的参数如下:
buffer_size: 一个整数,表示用于在数据集中随机抽取元素的缓冲区大小。较大的 buffer_size 可以提高打乱的程度,但也会占用更多的内存。通常建议设置为数据集的大小或更大。
seed: 一个整数,用于设置随机数生成器的种子,以确保每次运行时打乱的顺序一致。如果不设置,将使用系统时间作为种子,导致每次运行时打乱的结果不同。
reshuffle_each_iteration: 一个布尔值,表示是否在每次迭代时重新打乱数据。如果设置为 True,则每次迭代时都会重新打乱数据;如果设置为 False,则只在第一次迭代时打乱一次数据,默认为 True。
prefetch(buffer_size)
prefetch 方法用于在训练模型时异步加载数据,以减少训练时的等待时间。它的参数如下:
buffer_size: 一个整数,表示在使用数据前,要在后台异步加载的元素数量。较大的 buffer_size 可以提高数据加载的效率。
这两个方法通常一起使用。shuffle 用于在每个 epoch 开始时对数据进行随机打乱,而 prefetch 则用于在模型训练时异步加载数据,从而减少训练过程中的等待时间,提高训练效率。
构建神经网络
num_classes = 5
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.3),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(num_classes) # 输出层,输出预期结果
])
model.summary() # 打印网络结构

编译训练
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.compile() 是 Keras 模型的一个关键步骤,它用于配置模型的训练过程。在这个函数中,你需要指定模型的优化器、损失函数和评估指标。
model.compile(
optimizer, # 优化器,如 tf.keras.optimizers.Adam 或字符串标识
loss, # 损失函数,如 tf.keras.losses.CategoricalCrossentropy 或字符串标识
metrics=None, # 评估指标,可以是字符串标识或列表
loss_weights=None, # 损失权重,用于多个损失函数的加权
weighted_metrics=None, # 加权评估指标,与 metrics 参数一起使用
run_eagerly=None, # 是否以 eager mode 运行
steps_per_execution=None, # 每个训练步骤执行的批次数
**kwargs # 其他参数
)
参数及其说明:
optimizer(优化器):
指定用于训练模型的优化器。可以传递优化器实例,如 tf.keras.optimizers.Adam(),也可以传递字符串标识来指定内置优化器,如 ‘adam’。如果不指定优化器,将使用 Keras 的默认优化器。
loss(损失函数):
指定用于训练模型的损失函数。可以传递损失函数实例,如 tf.keras.losses.CategoricalCrossentropy(),也可以传递字符串标识来指定内置损失函数,如 ‘sparse_categorical_crossentropy’。如果模型有多个输出,可以为每个输出指定不同的损失函数。
metrics(评估指标):
用于评估模型性能的指标,可以是字符串标识或指标实例。常见的指标包括 ‘accuracy’、‘mae’ 等。如果模型有多个输出,可以为每个输出指定不同的评估指标。也可以传递列表来使用多个评估指标。
loss_weights(损失权重):
用于指定不同损失函数的权重,用于多输出模型。
weighted_metrics(加权评估指标):
与 metrics 参数一起使用,用于为不同的输出加权计算评估指标。
run_eagerly(是否以 eager mode 运行):
如果设置为 True,则会以 eager mode 运行。这在调试时可能很有用。
steps_per_execution(每个训练步骤执行的批次数):
指定在每个训练步骤中执行的批次数。这可以优化训练速度。
kwargs(其他参数):
允许传递其他参数,用于底层优化器和损失函数的配置。
返回值:
该函数没有显式的返回值。它会在模型上进行原地修改,配置模型的训练过程。
其他损失函数
import tensorflow as tf
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=0.001)
# 均方误差损失函数,适用于回归问题
model.compile(
optimizer=opt,
loss='mean_squared_error',
metrics=['accuracy'] # 评估指标,这里选择准确率
)
# 交叉熵损失函数,适用于分类问题
model.compile(
optimizer=opt,
loss='categorical_crossentropy',
metrics=['accuracy']
)
# 交叉熵损失函数,适用于多类别分类问题
model.compile(
optimizer=opt,
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# 二元交叉熵损失函数,适用于二分类问题
model.compile(
optimizer=opt,
loss='binary_crossentropy',
metrics=['accuracy']
)
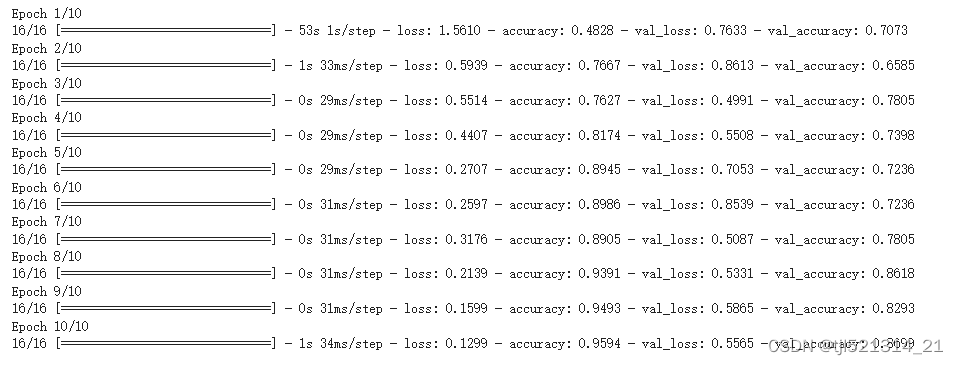
模型训练函数
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
结果如下
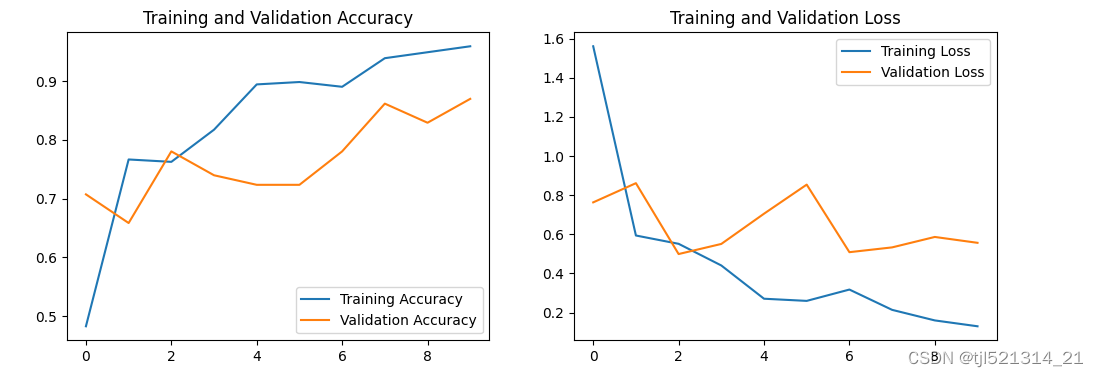
模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
总结
这周学习了使用tensorflow加载自己的数据集,为后续学习做好了铺垫。















 804
804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









