







一 :共用体的类型定义、变量定义和使用
(1)共用体union和结构体struct在类型定义、变量定义、使用方法相似
#include <stdio.h>
//共用体类型定义
union myunion
{
int a;
char b;
};
int main(void)
{
//共用体变量定义
union myunion myu1;
return 0;
}(2)共用体和结构体的不同:结构体类似一个包裹,结构体中的成员是彼此独立存在的,分布在内存不同单元中,只是被打包变成一个整体;共用体各个元素其实是一体的,他们共用一个内存单元。可以理解为:有时候是这个元素,有时候是那个元素 更准确的说法:同一个内存空间有多种解释方式
#include <stdio.h>
//定义结构体类型
struct mystruct
{
int a;
char b;
};
//定义共用体类型
//其实a和b指向同一块内存空间,只是对这块内存空间有两种解析方式
//如果我们使用u1.a那么就是按照int类型来解析这块内存空间,如果是使用u1.b那么就是按照char类型解析这块内存空间
union myunion
{
int a;
int b;
};
int main(void)
{
struct mystruct s1; //定义结构体变量
s1.a = 12;
printf("s1.a = %d\n",s1.a); //输出结果:s1.a = 12;
printf("s1.b = %d\n",s1.b); //输出结果:s1.b = 0; 结论:彼此独立存在
union myunion u1; //定义共用体变量
un.a = 34;
printf("u1.a = %d\n",u1.a); //输出结果:u1.a = 34;
printf("u1.b = %d\n",u1.b); //输出结果:u1.b = 34; 结论:彼此是一体的
//通过编程证明结构体元素指向不同块内存空间
printf("&s1.a = %p\n",&s1.a); // 结果:0x7fff8ebafc10
printf("&s1.b = %p\n",&s1.b); // 结果:0x7fff8ebafc14
//a和b地址不同,证明使用不同块的内存空间
//通过编程证明共用体元素指向同一块内存空间
printf("&u1.a = %p\n",&myu1.a); // 结果:0x7ffe475215e0
printf("&u1.b = %p\n",&myu1.b); // 结果:0x7ffe475215e0
//a和b地址相同,证明使用同一块内存空间,只是
//只是对这块内存空间的解析方式不同
retrun 0;
}(3)共用体union就是对同一块内存中存储的二进制不同的解析方式
(4)在有些书中将共用体union翻译成联合体,但是其实用共用体更形象准确一些
(5)union用sizeof测到的大小是各个元素中占用内存最大的那个元素的大小,因为可以存的下最大的元素那么其他元素也能存的下
(6)union不存在内存对齐的问题,因为union中实际只有一块内存空间,都是从同一个地址开始的(开始地址就是union占用内存空间的首地址),所以不存在内存对齐
#include <stdio.h>
union myunion
{
char a;
};
union myunion1
{
char b;
short cb;
};
union myunion2
{
int a;
char b;
short c;
};
union myunion3
{
int a;
char b;
short c;
double d;
};
int main(void)
{
printf("sizeof(union myunion) = %d\n",sizeof(union myunion)); //结果:1
printf("sizeof(union myunion1) = %d\n",sizeof(union myunion1)); //结果:2
printf("sizeof(union myunion2) = %d\n",sizeof(union myunion2)); //结果:4
printf("sizeof(union myunion3) = %d\n",sizeof(union myunion3)); //结果:8
return 0;
}二 :共用体和结构体的相同点和不同点
(1)相同点就是操作语法几乎相同
(2)不同点:struct结构体是多个元素(内存空间)打包放在一起;union共用体是一个元素(内存空间)多种不同解析方式
三 :共用体的主要用途
(1)共用体就用在一个内存单元需要多种规则解析的环境下
(2)C语言其实是不需要共用体的,用指针和强制类型转换可以替代共用体完成相同的功能,但是共用体的方式更好理解、更方便、更快捷
#include <stdio.h>
//定义结构体类型
union myunion3
{
int a;
char b;
short c;
float d;
};
int main(void)
{
union myunion3 u1; //定义结构体变量
u1.d =123.458;
printf("u1.d = %f\n",u1.d); //123.458000
printf("u1.a = %d\n",u1.a); //1123478143
u1.a = 1123478143;
printf("u1.a = %d\n",u1.a); //1123478143
printf("u1.d = %f\n",u1.d); //123.458000
//指针的方式实现共同体
int a = 1123478143;
printf("指针的方式:%f\n",*((float *) &a));
float b = 123.458000;
printf("指针的方式:%d\n",*((int *)&b));
return 0;
}四 :大小端模式1
1:什么是大小端模式
(1)大端模式(big endian)和小端模式(little endian)
(2)计算机发展起来之后,遇到一个问题:在串行口通信中一次只能发送一个字节。当在一个需要发送一个int类型的数据时,int有四个字节,到底是由低位到高位byte->byte1->byte2->byte3还是从高位到低位byte3->byte2->byte1->byte0的顺序发送。规则就是发送方和接收方都要按照相同字节顺序来通信,否则就会出现错误。这就叫通信系统中的大小端模式
(3)现在讲的大小端模式,更多是指计算机存储系统的大小端。在计算机内存/硬盘/Nnad中。但是数据仍然是按照字节为单位的。于是乎一个32位的二进制在内存中存储时有两种分布方式:高字节对应低地址,低字节对应高地址(大端模式)、低字节对应低地址,高字节对应高地址(小端模式)
(4)大端模式和小端模式本身没有对错,没有优劣,理论上按照大端或小端都可以,但是存储时和读取时都需要按照同样的的大小端来进行,否则就会出错
(5)现实的情况:有些cpc用大端(c51单片机),有些cpu用小端(ARM)。于是乎我们写代码时,当不知道是大端模式还是小端模式时,就需要用代码来检测当前系统的大小端
经典笔试题:用C语言写一个函数来测试当前机器的大小端模式
2:用union来测试机器的大小端模式
#include <stdio.h>
//共用体中很重要的一点:a和b都是从u1的低地址开始的
//假设u1所在的4字节地址分别是:0、1、2、3的话,那么a自然就是0、1、2、3
//b所在的地址是0而不是3
union myunion
{
int a;
char b;
};
//小端模式返回,大端模式返回0
int is_big_little(void)
{
union myunion u1;
u1.a = 1; //地址为0的那个字节为1的话就是小端,地址为0的那个字节为0的话就是大端
return u1.b;
}
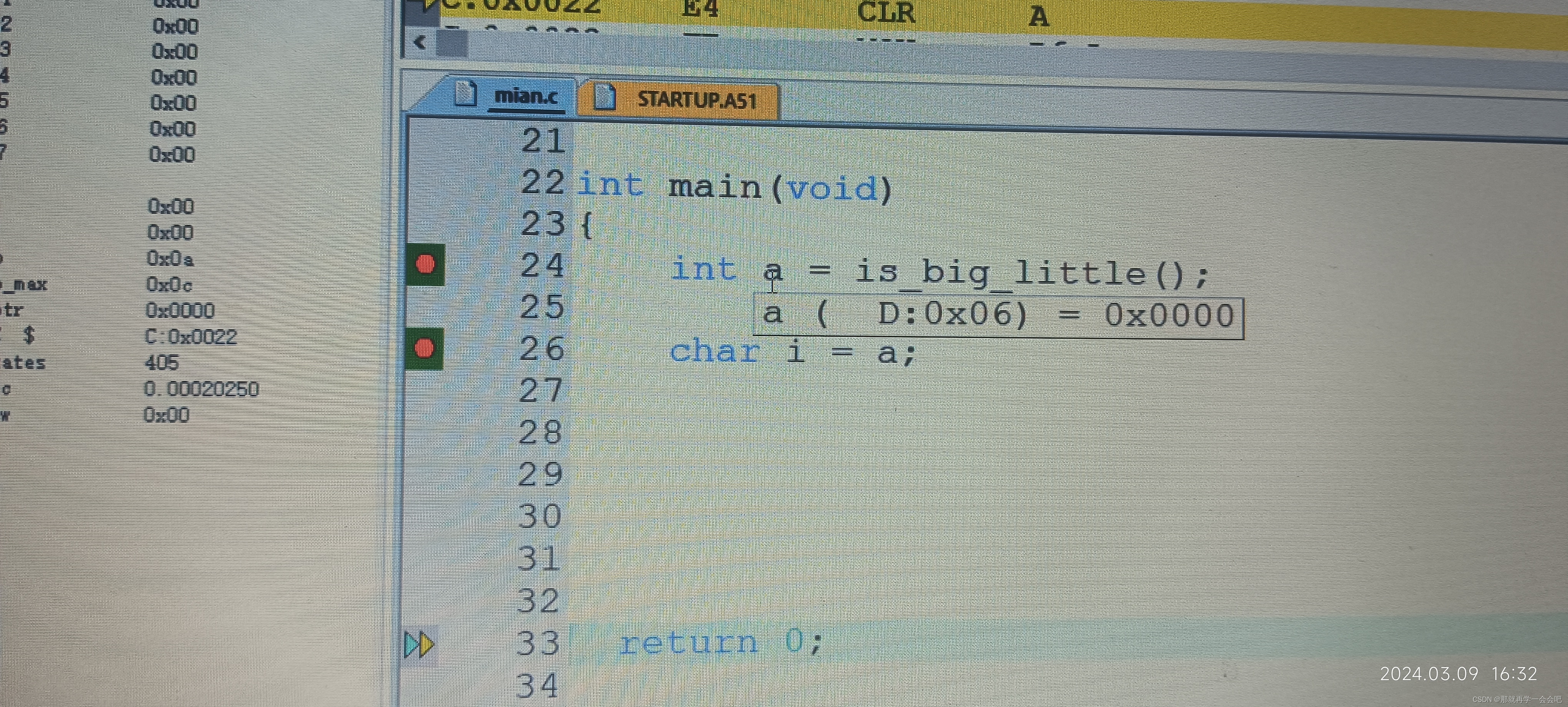
int main(void)
{
int i = is_big_little();
if(i==1)
{
printf("is little_endian\n");
}
else
{
printf("is big_endian");
}
return 0;
}在大端模式下的结果:低地址为0
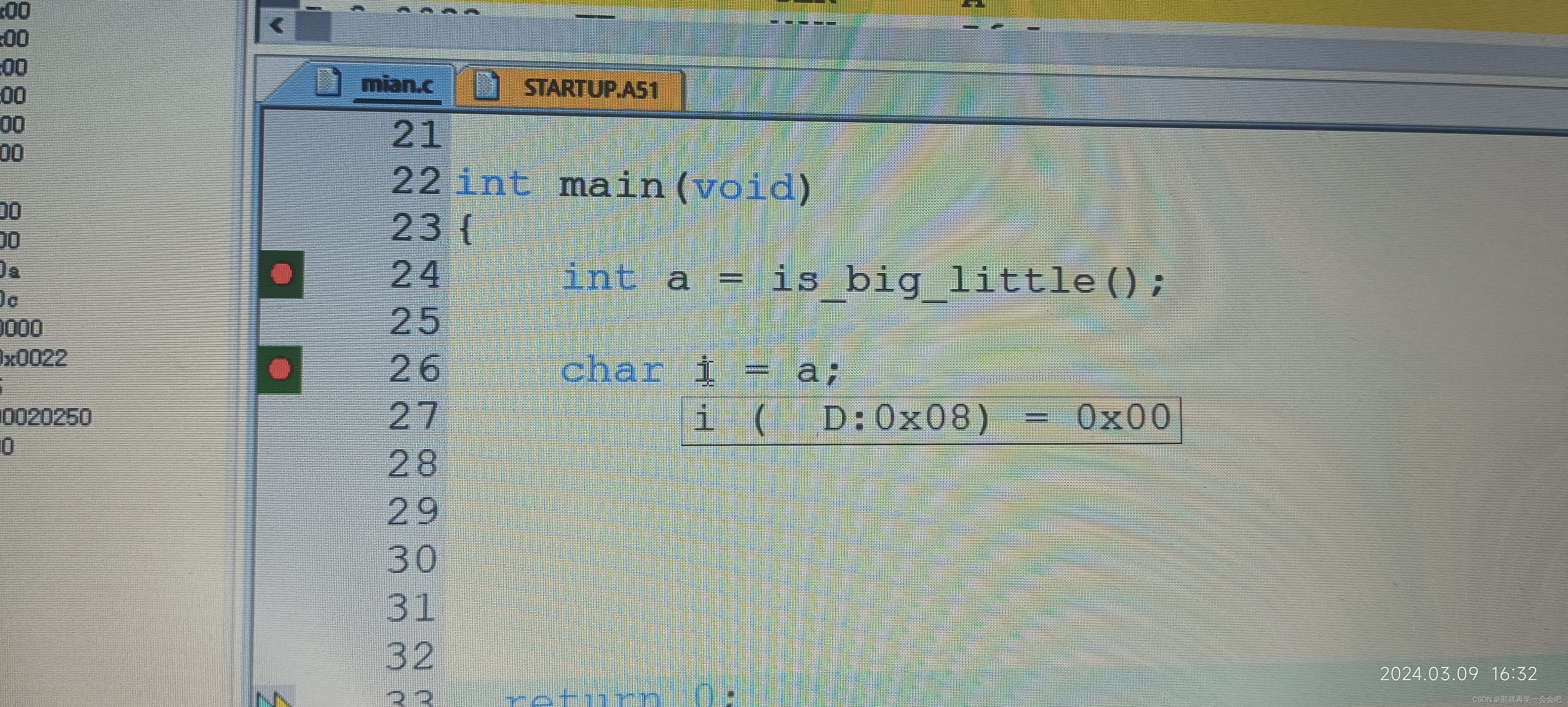
3:指针方式来测试机器的大小端
#include <stdio.h>
//共用体中很重要的一点:a和b都是从u1的低地址开始的
//假设u1所在的4字节地址分别是:0、1、2、3的话,那么a自然就是0、1、2、3
//b所在的地址是0而不是3
union myunion
{
int a;
char b;
};
//指针方式来测试机器的大小端
int is_big_litle1(void)
{
int a = 1;
char b = * ((char *)&a ); //指针方式其实就是共用体的本质
return b;
}
int main(void)
{
int i = is_big_litle1();
if(i==1)
{
printf("is little_endian\n");
}
else
{
printf("is big_endian");
}
return 0;
}
4:看似可以实则不行的大小端测试方式:位与、移位、强制类型转换
(1)位与运算
结论:位于的方式无法测试机器的大小端模式(原因是因为大端机器和小端机器的运算最后的结果是相同的无法分辨是大端模式还是小端模式)
#include <stdio.h>
int main(void)
{
int a = 1;
char b = a & 0xff;
printf("b = %d\n",b); //小端模式下b = 1
}大端模式下:结果与小端模式相同
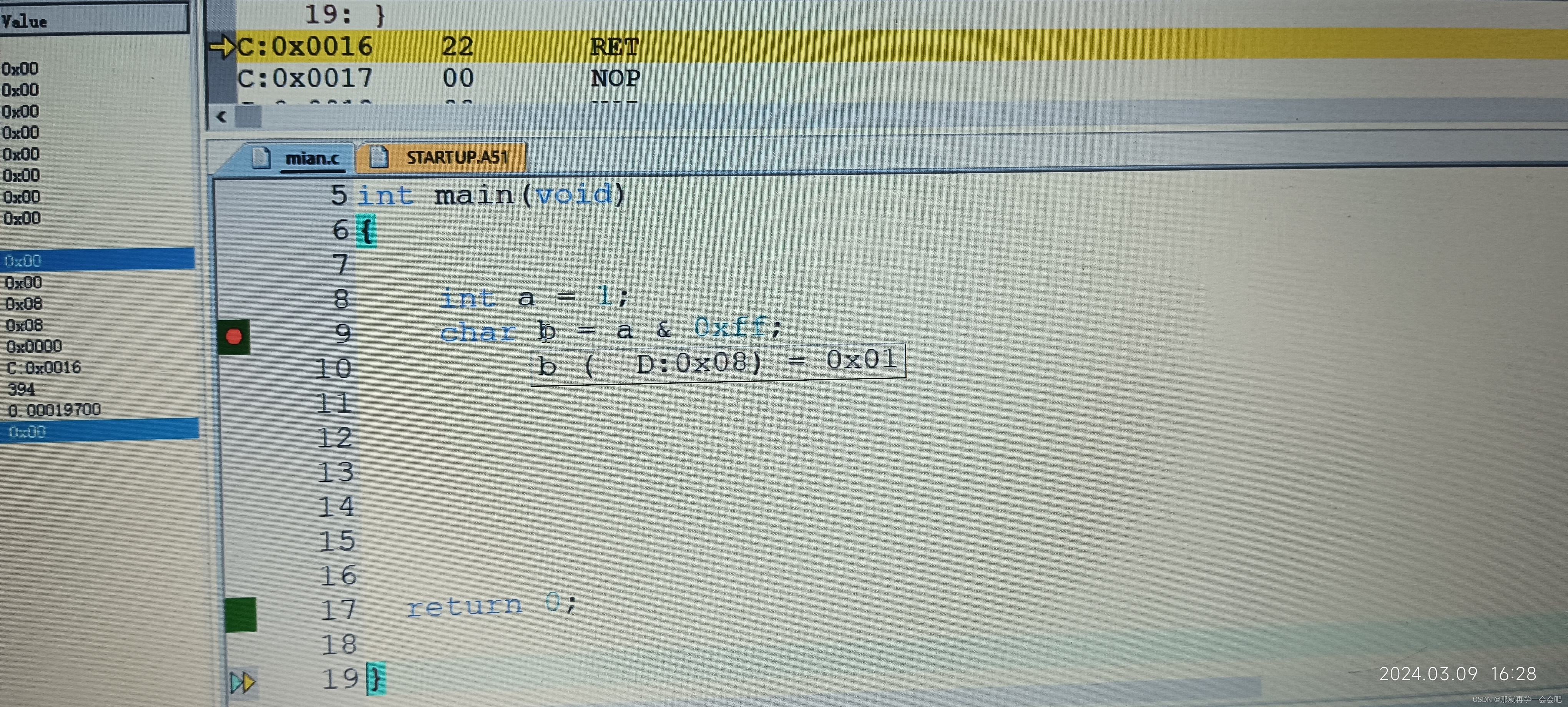
(2)移位
结论:移位的方式无法测试机器的大小端
理论分析:原因和&运算符不能测试一样,因为C语言对于运算符的级别是高于二进制层次的。右移运算永远是将低字节移除,而和二进制存储时这个低字节是在低位还是高位是无关的
#include <stdio.h>
int main(void)
{
int a,b;
a = 1;
b = a >> 1;
printf("b = %d\n",b); //b的结果为0
}
大端模式下:结果为0

(3)强制类型转换
结论:无法测试机器的大小端
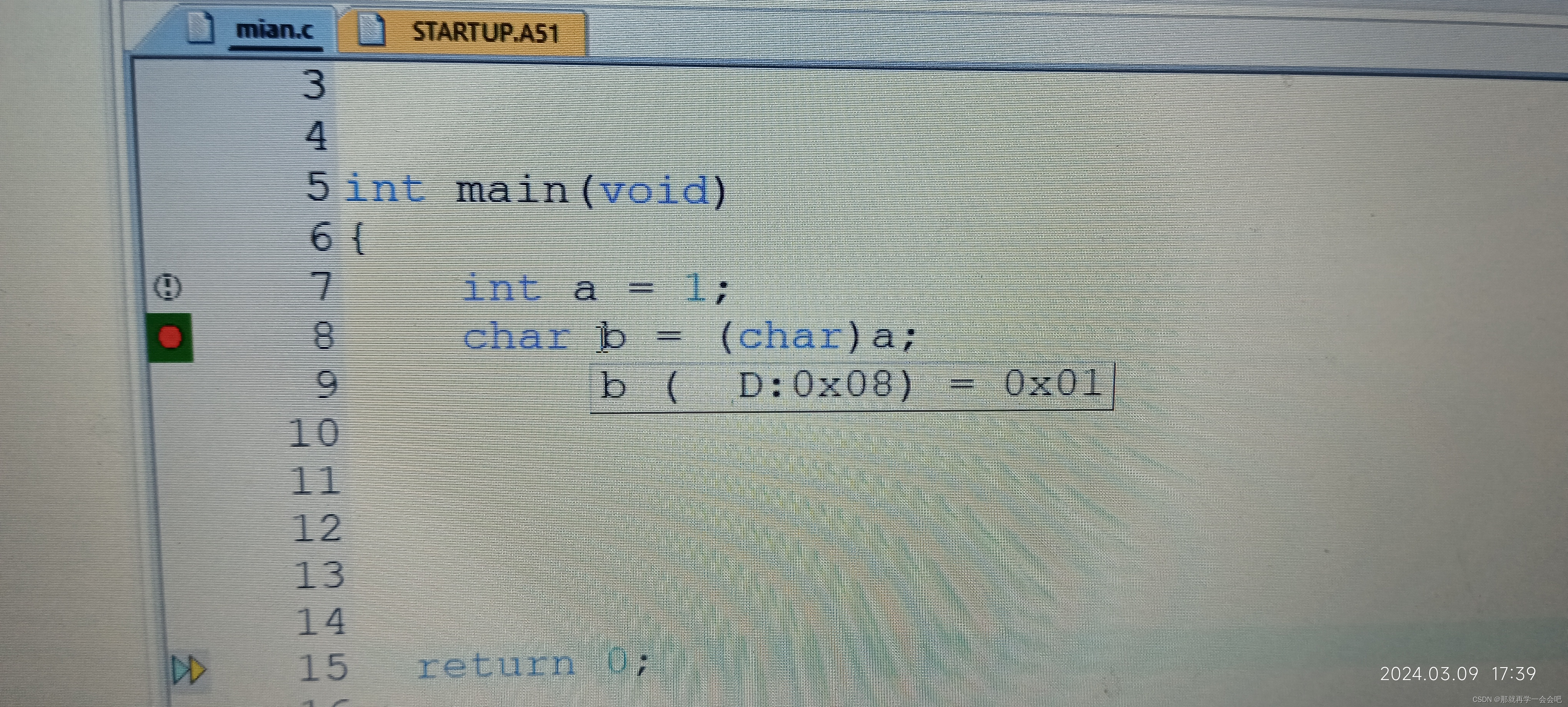
#include <stdio.h>
int main(void)
{
int a = 1;
char b = (char)a;
printf("b = %d\n",b); //结果为1
return 0;
}大端模式下:
5:通信系统中的大小端(数组中的大小端)
(1)譬如通过串口发送一个0x12345678给接收方,但是因为串口本身的限制,只能以字节为单位来发送;接收方分四次来接收,内容分别是0x12,0x34,0x56,0x78。接受方接收到这四个字节后需要去重组得到0x12345678(而不是得到0x78563412)
(2)所以在通信双方需要有一个默契:就是:先发/先收的是高位还是低位?这就是通信中的大小端问题
(3)一般来说是:先发低字节叫小端,先发高字节就叫大端(不能确定)。 在实际操作中,通信协议里面会定义大小端,会明确的告诉你先发的是高字节还是低字节















 1319
1319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









