







KMV模型概述
KMV模型是一种估计企业违约概率的方法。KMV基于期权定价理论的信用风险评估模型,由美国旧金山市KMV公司于1997年开发。该模型的核心思想是将企业债务视为一种期权,通过分析企业资产价值与债务价值的相对关系,计算企业违约概率(Probability of Default, PD),从而评估其信用风险,还能根据历史数据推断违约概率(Expected Default Frequency, EDF)。
KMV 是三个创始人的姓氏首字母缩写,分别代表 KMV 公司的三位创始人:Kenneth D. KimballRobert H. MertonStanley B. Vasicek这三位专家在金融风险管理领域有着卓越的贡献,KMV 模型正是基于他们的研究和开发而得名。
模型的应用
1.上市公司信用风险评估:KMV模型特别适用于上市公司,因为它利用股票市场价格信息来动态评估企业的信用风险。
2.动态风险监测:由于基于股票市场数据,模型能够及时反映企业信用状况的变化,具有前瞻性。
3.商业银行信贷风险管理:KMV模型可以帮助银行评估信贷资产的风险,优化信贷决策。
模型的优势
动态性:模型能够根据市场信息实时更新,反映企业当前的信用状况。
前瞻性:通过市场预期而非历史数据评估风险,更符合现代风险管理需求。
量化分析:提供了一种系统化的信用风险量化方法。
模型的局限性
假设条件严格:假设资产价值服从正态分布,而实际情况中企业资产价值可能呈现非正态分布。
适用范围有限:对非上市公司,由于缺乏股票市场数据,模型的应用效果可能较差。
忽略信用等级变化:模型主要关注违约概率,而对企业的信用等级变化缺乏敏感性。
KMV模型算法流程
以下是一个简化的Python代码示例,展示如何实现KMV模型的关键计算步骤:
-
估算公司资产价值和资产波动率:首先,我们需要估算公司的资产价值(V)和资产波动率(σ_V)。这通常涉及到解决一个非线性方程组,可以使用
scipy.optimize中的fsolve函数来解决。 -
计算违约距离(DD):违约距离是公司资产价值与违约点(D)之间的差额,除以资产波动率。
-
计算违约概率(EDF):违约概率可以通过历史数据进行拟合。KMV公司提供了违约距离与违约概率之间的映射关系。


请注意,以下代码是一个示例,实际应用中需要根据具体数据和模型参数进行调整。
import numpy as npfrom scipy.optimize import fsolvefrom scipy.stats import norm# 假设我们已经有了以下数据:equity_value = 1e9 # 股权市场价值equity_volatility = 0.2 # 股权波动率total_debt = 5e8 # 总负债risk_free_rate = 0.05 # 无风险利率# Black-Scholes公式def black_scholes(V, D, sigma_V, r, T=1):d1 = (np.log(V / D) + (r + 0.5 * sigma_V**2) * T) / (sigma_V * np.sqrt(T))d2 = d1 - sigma_V * np.sqrt(T)return V * norm.cdf(d1) - D * np.exp(-r * T) * norm.cdf(d2)# KMV模型方程def kmv_equation(x):V, sigma_V = xE = black_scholes(V, total_debt, sigma_V, risk_free_rate)return [E - equity_value, sigma_V * V - equity_volatility * equity_value]# 使用fsolve求解资产价值和资产波动率V, sigma_V = fsolve(kmv_equation, [equity_value, equity_volatility])# 计算违约距离(DD)DD = (V - total_debt) / (sigma_V * np.sqrt(equity_volatility**2 + sigma_V**2))# 计算违约概率(EDF)def dd_to_edf(dd):return norm.cdf(-dd)EDF = dd_to_edf(DD)print(f"公司的资产价值: {V}")print(f"公司的资产波动率: {sigma_V}")print(f"公司的违约距离: {DD}")print(f"公司的违约概率: {EDF}")
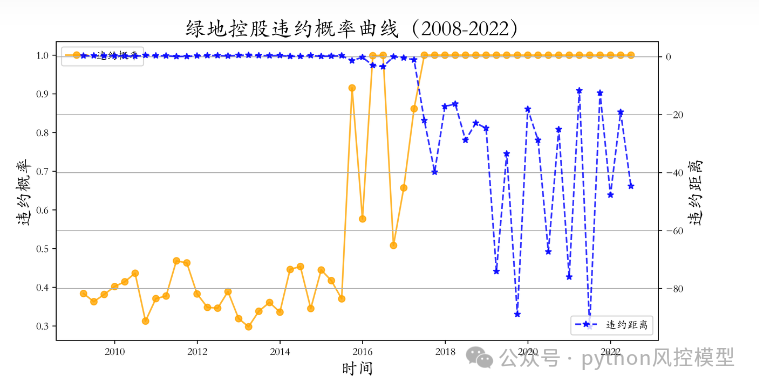
案例-绿地控股违约概率
import pandas as pdimport numpy as npimport warningsfrom scipy.optimize import fsolvefrom scipy.stats import norm # 正态分布累计概率函数def cal_Va_Sigma_a(V_e, Sigma_e, D, rf, t=1):"""计算资产市值以及资产波动率:param V_e: 股权市值:param Sigma_e: 股权波动率:param D: 债务面值:param rf: 无风险利率:param t: 无风险利率对应期限:return: 资产市值V_a和资产波动率的Series"""rf = (np.power(1 + rf, 1 / t) - 1) * tV_e, Sigma_e, D, rf = float(V_e), float(Sigma_e), float(D), float(rf)def solve_function(x):"""方程组,用于根据股权市值,股权波动率,债务面值,无风险利率,求解每只股票的资产市值V_a和资产波动率Sigma_a:param x: 列表,两个未知数,分别是资产市值以及资产波动率:return: 方程"""x0 = float(x[0]) # 资产市场价格, 未知数1x1 = float(x[1]) # 资产波动率,未知数2# 计算d1和d2d1 = (np.log(abs(x0)) - np.log(D) + (rf + 0.5 * (x1 ** 2)) * t) / (x1 * np.sqrt(t))d2 = d1 - x1 * np.sqrt(t)return [x0 * norm.cdf(d1) - D * np.exp(-rf * t) * norm.cdf(d2) - V_e,x0 * x1 * (norm.cdf(d1) / V_e) - Sigma_e]e_x = np.array([V_e, Sigma_e]) # 设定一个方程求解初始值# 求解方程组# bsm方程组是一个非线性方程组,fslove求得的是局部最优解,所以不一定能得到全局最优解# 迭代初始值x0对结果的影响可能很大, 不合适的初值可能导致结果不收敛或偏差太大,因而爆出警告warnings.filterwarnings('ignore') # 忽略warnings,有两个求解报了warning,想看warning就注释掉result = fsolve(solve_function, e_x)return pd.Series(result, index=['V_a', 'Sigma_a'])if __name__ == "__main__":# 读入2021年年报中的全A股数据(未发布年报则是采用2021年第三季度财务数据), 数据来源Wind# 列名说明:# board: 上市板块;Ve: 2022-01-01的股权市值;Sigma_e:股权过去252天波动率(年化%)# sw: 申万一级;D_s:流动负债;D_l:非流动负债;D:负债总额data = pd.read_excel('全市场2021年信息.xlsx', sheet_name=0)data.columns = ['stock_code', 'stock_name', 'sw', 'board', 'Ve', 'Sigma_e','D_s', 'D_l', 'D']# 读入无风险利率(包括各个期限国债到期收益率)Rf = pd.read_excel('BND_TreasYield.xlsx', sheet_name=0)# 使用十年期到期国债收益率(Maturity=10)Rf = Rf[Rf['Yeartomatu'] == 10].copy()Rf.drop(columns=['Cvtype'], inplace=True)Rf.columns = ['trade_date', 'Maturity', 'rf']# 计算2021年平均无风险收益率Rf['Year'] = Rf['trade_date'].apply(lambda x: int(x[:4])) # 生成Year这一列rf = Rf.loc[Rf.Year == 2021, 'rf'].mean() / 100 # 除以100# 'Ve', 'Sigma_e', 'D'为空或是0,则是无法进行计算,因此删除此部分样本data = data.replace(0, np.NaN)data.dropna(subset=['Ve', 'Sigma_e', 'D'], inplace=True)# 银行与非银金融流动与非流动负债数据没有,删除data = data[~data['sw'].isin(['银行', '非银金融'])].copy()data.dropna(subset=['sw'], inplace=True)# 其他情况是没有非流动负债,全部填充0data.fillna(0, inplace=True)# 波动率单位调整data['Sigma_e'] = data['Sigma_e'] / 100# 计算违约点Dpdata['Dp'] = data['D_s'] + 0.5 * data['D_l']# apply方法,逐行将股权市值、市值波动率、债务、无风险利率输入到cal_Va_Sigma_a()函数中,求解对应资产市值以及资产波动率Va_Sigma = data.apply(lambda x: cal_Va_Sigma_a(x['Ve'], x['Sigma_e'], x['D'], rf, t=1), axis=1)data = pd.concat([data, Va_Sigma], axis=1) # 结果合并到源数据中# 计算违约距离data['default_d'] = (data['V_a'] - data['Dp']) / data['V_a'] * data['Sigma_e']# 计算违约概率,逐行将违约距离映射到正态分布data['default_prob'] = data['default_d'].apply(lambda x: norm.cdf(-x))# 选择要输出的列,重命名成中文,加上时间以及无风险利率data = data[['stock_code', 'stock_name', 'sw', 'V_a', 'Sigma_a', 'Dp', 'default_d', 'default_prob']]data.rename(columns={'stock_code': '股票代码', 'stock_name': '股票名称', 'sw': '申万一级','V_a': '资产市值', 'Sigma_a': '资产波动率', 'Dp': '违约点','default_d': '违约距离', 'default_prob': '违约概率'}, inplace=True)data['时间'] = '2022-01-01'data['无风险利率'] = rfdata = data[['股票代码', '股票名称', '申万一级', '时间', '无风险利率','资产市值', '资产波动率', '违约点', '违约距离', '违约概率']].copy()data.to_excel('2021年报全A股市场违约概率表(除非银金融、银行).xlsx', index=False)
KMV模型作为一种创新的信用风险评估工具,为金融风险管理提供了新的视角和方法,但其应用仍需结合实际情况和数据可得性进行调整。在实际应用中,还需要考虑数据的获取、模型参数的估计、模型的验证和调整等多个方面。此外,KMV模型的实现可能需要专业的金融知识和对市场数据的深入理解。上述代码仅供参考,实际应用时需要根据具体情况进行调整和优化。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。


















 1637
1637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









