







首先需要使用Navicat在数据库建库santi,在santi内建表santi_001
表的格式需要与santi_001(lal: String,count:Int,time:String)相同。
代码如下。
使用SQL语句写入数据库
import java.sql.{DriverManager, Connection}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkContext, SparkConf}
object ToMysql{
/**
*’host’: “192.168.137.131”,
*’user’: “root”,
*’password’: “password”,
*’database’: “santi”,
*’charset’: ‘utf8’
* */
case class santi_001(lal: String,count:Int,time:String)
//模式匹配,测试后不模式匹配也写入成功
val url=”jdbc:mysql://192.168.137.131:3306/santi”
def myFun(iterator: Iterator[(String, Int,String)]): Unit = {
var conn: Connection= null
var ps:java.sql.PreparedStatement=null
//比Statement方便,S执行一条Sql就得执行一次Statement,而PS性能体现在多次执行Sql,而且参数设置更加方便
val sql=”insert into santi_001(lal, count,time) values (?,?,?)”
conn=DriverManager.getConnection(url,”root”,”password”)
ps = conn.prepareStatement(sql)
iterator.foreach(data => {
ps.setString(1, data._1)
ps.setInt(2, data._2)
ps.setString(3, data._3)
ps.executeUpdate() //执行了Sql语句
}
)
}
def main(args: Array[String]) {
//创建环境变量
val sparkConf = new SparkConf().setAppName(“PeakTimePeople”)
//创建环境变量实例
val sc = new SparkContext(sparkConf)
val a=List((“12@21”,12,”20160201”),(“13@12”,31,”20160831”),(“13@12”,31,”20160826”))
val data:RDD[(String, Int, String)] = sc.parallelize(a) //parallelize可分区的makeRDD
data.foreachPartition(myFun) //foreachPartition对每一个分区使用Function
sc.stop()
}
}
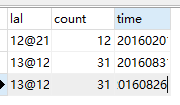
执行结果















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









