







一、JPEG编解码原理
JPEG编码原理
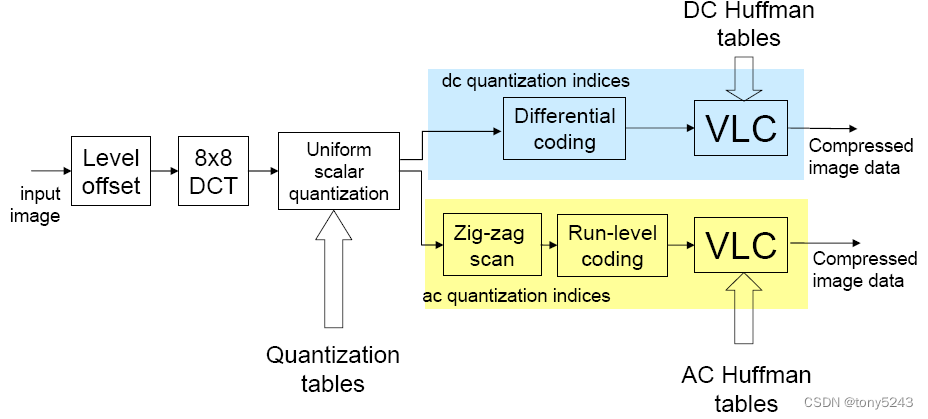
JPEG解码过程是编码的逆过程。
二、实验过程
1.JPG文件输出YUV文件
修改loadjpeg.c中的write_yuv()函数如下:
/**
* Save a buffer in three files (.Y, .U, .V) useable by yuvsplittoppm
*/
static void write_yuv(const char *filename, int width, int height, unsigned char **components)
{
FILE *F;
char temp[1024];
fwrite(components[0], width, height, F);
fwrite(components[1], width * height / 4, 1, F);
fwrite(components[2], width * height / 4, 1, F);
fclose(F);
}在运行的参数中输入:
test.jpg yuv420p test_yuv运行后,输出test_yuv.yuv文件,打开生成的yuv文件:

2.理解编解码过程
(1)理解程序设计的整体框架
- loadjpeg:通过命令行参数读取文件信息。
- convert_one_image:通过一系列判断是否成功打开文件,获得文件长度,是否成功读入缓存。
- tinyjpeg_parse_header:判断文件开头是是否满足jpg条件后,获得SOI后数据地址,文件长度信息。
- parse_JFIF函数,分析拆解每个文件块进行分析。
- 解析DQT块进入parse_DQT:通过 build_quantization_table建立量化表,只支持小于4张量化表,每个表64个数据。
- 解析DHT块进入parse_DHT:通过 build_huffman_table建立哈夫曼表。
- 解析 SOS调用parse_SOS:解析每个颜色分量的 DC、AC 值所使用的 Huffman 表序号(与 DHT中序号对应)。
- tinyjpeg_get_size:jpg图像的长宽。
- tinyjpeg_decode:解码。
- 对每个宏块进行Huffman解码,得到DCT系数
- 对每个宏块的DCT系数进行IDCT,得到Y、Cb、Cr遇到Segment Marker RST时,清空之前的DCT系数
(2)理解三个结构体的设计目的
- struct huffman_table:用于存储Huffman码表
struct huffman_table
{
/* 快速查找表,使用 HUFFMAN_HASH_NBITS 位我们可以直接得到符号,
* 如果符号 <0,那么我们需要查看树表 */
short int lookup[HUFFMAN_HASH_SIZE];
/* 码字长度:给出一个符号被编码的位数 */
unsigned char code_size[HUFFMAN_HASH_SIZE];
/* 存储未在查找表中编码的值的空间
* FIXME:计算256个值是否足以存储所有值 */
uint16_t slowtable[16-HUFFMAN_HASH_NBITS][256];
};- struct component:用于参与霍夫曼解码,反量化,IDCT 以及彩色空间变换,Hfactor和 Vfactor 用于说明水平与垂直的采样情况
struct component
{
unsigned int Hfactor; /* 水平采样因子 */
unsigned int Vfactor; /* 垂直采样因子 */
float *Q_table; /* 指向要使用的量化表的指针 */
struct huffman_table *AC_table; /* 交流哈夫曼表 */
struct huffman_table *DC_table; /* 直流哈夫曼表 */
short int previous_DC; /* 前直流系数 */
short int DCT[64]; /* DCT系数 */
#if SANITY_CHECK // 调试使用
unsigned int cid;
#endif
};- struct jdec_private:用于指示解码过程中的所有信息,量化表,霍夫曼码表以及图像数据
struct jdec_private
{
/* 全局变量 */
uint8_t *components[COMPONENTS];
unsigned int width, height; /* 图像大小 */
unsigned int flags;
/* 私有变量 */
const unsigned char *stream_begin, *stream_end;
unsigned int stream_length;
const unsigned char *stream; /* 指向当前流的指针 */
unsigned int reservoir, nbits_in_reservoir;
struct component component_infos[COMPONENTS];
float Q_tables[COMPONENTS][64]; /* 量化表 */
struct huffman_table HTDC[HUFFMAN_TABLES]; /* 直流哈夫曼表 */
struct huffman_table HTAC[HUFFMAN_TABLES]; /* 交流哈夫曼表 */
int default_huffman_table_initialized;
int restart_interval;
int restarts_to_go; /* 在此重启间隔内剩余的 MCU */
int last_rst_marker_seen; /* Rst标记每次递增 */
/* IDCT 之后用于存储每个组件的临时空间 */
uint8_t Y[64*4], Cr[64], Cb[64];
jmp_buf jump_state;
/* 内部指针用于色彩空间转换 */
uint8_t *plane[COMPONENTS];
};(3)理解在视音频编解码调试中TRACE的目的和含义
TRACE起追踪纠错作用,为1即可使用#if TRACE 所需输出内容 #endif在程序某一进程中输出到指定的文件,并且可以输出参数debug。
示例:
#if TRACE
/* 输出内容 */
p_trace=fopen(TRACEFILE,"w");
if (p_trace==NULL)
{
printf("trace file open error!");
}
#endif3.以txt文件输出所有的量化矩阵和所有的HUFFMAN码表
(1)量化矩阵:
static int parse_DQT(struct jdec_private *priv, const unsigned char *stream)
{
int qi;
int i;
int j;
float *table;
const unsigned char *dqt_block_end;
#if TRACE
fprintf(p_trace,"> DQT marker\n");
fflush(p_trace);
#endif
dqt_block_end = stream + be16_to_cpu(stream);
stream += 2; /* Skip length */
while (stream < dqt_block_end)
{
qi = *stream++;
#if SANITY_CHECK
if (qi>>4)
snprintf(error_string, sizeof(error_string),"16 bits quantization table is not supported\n");
if (qi>4)
snprintf(error_string, sizeof(error_string),"No more 4 quantization table is supported (got %d)\n", qi);
#endif
table = priv->Q_tables[qi];
build_quantization_table(table, stream);
stream += 64;
}
#if TRACE
/* 新增代码 */
for (i = 0; i < 8; ++i) {
for (j = 0; j < 8; ++j) {
fprintf(p_trace, "%f ", table[i * 8 + j]);
}
fprintf(p_trace, "\n");
}
fprintf(p_trace,"< DQT marker\n");
fflush(p_trace);
#endif
return 0;
}
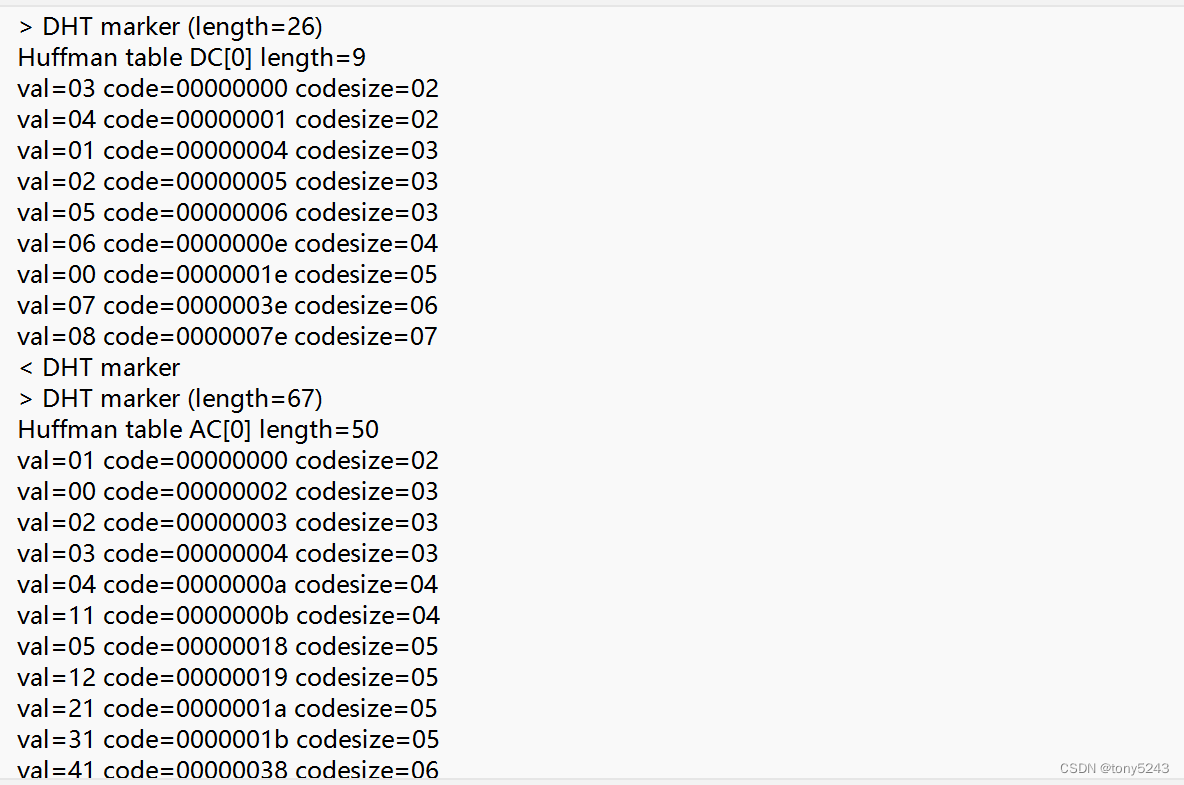
(2)Huffman表
static void build_huffman_table(const unsigned char *bits, const unsigned char *vals, struct huffman_table *table)
{
unsigned int i, j, code, code_size, val, nbits;
unsigned char huffsize[HUFFMAN_BITS_SIZE+1], *hz;
unsigned int huffcode[HUFFMAN_BITS_SIZE+1], *hc;
int next_free_entry;
/*
* Build a temp array
* huffsize[X] => numbers of bits to write vals[X]
*/
hz = huffsize;
for (i=1; i<=16; i++)
{
for (j=1; j<=bits[i]; j++)
*hz++ = i;
}
*hz = 0;
memset(table->lookup, 0xff, sizeof(table->lookup));
for (i=0; i<(16-HUFFMAN_HASH_NBITS); i++)
table->slowtable[i][0] = 0;
/* Build a temp array
* huffcode[X] => code used to write vals[X]
*/
code = 0;
hc = huffcode;
hz = huffsize;
nbits = *hz;
while (*hz)
{
while (*hz == nbits)
{
*hc++ = code++;
hz++;
}
code <<= 1;
nbits++;
}
/*
* Build the lookup table, and the slowtable if needed.
*/
next_free_entry = -1;
for (i=0; huffsize[i]; i++)
{
val = vals[i];
code = huffcode[i];
code_size = huffsize[i];
#if TRACE
fprintf(p_trace,"val=%2.2x code=%8.8x codesize=%2.2d\n", val, code, code_size);
fflush(p_trace);
#endif
table->code_size[val] = code_size;
if (code_size <= HUFFMAN_HASH_NBITS)
{
/*Good: val can be put in the lookup table, so fill all value of this
column with value val */
int repeat = 1UL<<(HUFFMAN_HASH_NBITS - code_size);
code <<= HUFFMAN_HASH_NBITS - code_size;
while ( repeat-- )
table->lookup[code++] = val;
}
else
{
/* Perhaps sorting the array will be an optimization */
uint16_t *slowtable = table->slowtable[code_size-HUFFMAN_HASH_NBITS-1];
while(slowtable[0])
slowtable+=2;
slowtable[0] = code;
slowtable[1] = val;
slowtable[2] = 0;
/* TODO: NEED TO CHECK FOR AN OVERFLOW OF THE TABLE */
}
}
}















 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









