




1. 前言
隐马尔科夫HMM模型是一类重要的机器学习方法,其主要用于序列数据的分析,广泛应用于语音识别、文本翻译、序列预测、中文分词等多个领域。虽然近年来,由于RNN等深度学习方法的发展,HMM模型逐渐变得不怎么流行了,但并不意味着完全退出应用领域,甚至在一些轻量级的任务中仍有应用。本系列博客将详细剖析隐马尔科夫链HMM模型,同以往网络上绝大多数教程不同,本系列博客将更深入地分析HMM,不仅包括估计序列隐状态的维特比算法(HMM解码问题)、前向后向算法等,而且还着重的分析HMM的EM训练过程,并将所有的过程都通过数学公式进行推导。
由于隐马尔科夫HMM模型是一类非常复杂的模型,其中包含了大量概率统计的数学知识,因此网络上多数博客一般都采用举例等比较通俗的方式来介绍HMM,这么做会让初学者很快明白HMM的原理,但要丢失了大量细节,让初学者处于一种似懂非懂的状态。而本文并没有考虑用非常通俗的文字描述HMM,还是考虑通过详细的数学公式来一步步引导初学者掌握HMM的思想。另外,本文重点分析了HMM的EM训练过程,这是网络上其他教程所没有的,而个人认为相比于维特比算法、前向后向算法,HMM的EM训练过程虽然更为复杂,但是一旦掌握这个训练过程,那么对于通用的链状图结构的推导、EM算法和网络训练的理解都会非常大的帮助。另外通过总结HMM的数学原理,也能非常方便将数学公式改写成代码。
最后,本文提供了一个简单版本的隐马尔科夫链HMM的Python代码,包含了高斯模型的HMM和离散HMM两种情况,代码中包含了HMM的训练、预测、解码等全部过程,核心代码总共只有200~300行代码,非常简单!个人代码水平比较渣=_=||,大家按照我的教程,应该都可以写出更鲁棒性更有高效的代码,附上Github地址:https://github.com/tostq/Easy_HMM
觉得好,就点星哦!
觉得好,就点星哦!
觉得好,就点星哦!

重要的事要说三遍!!!!
为了方便大家学习,我将整个HMM代码完善成整个学习项目,其中包括
hmm.py:HMM核心代码,包含了一个HMM基类,一个高斯HMM模型及一个离散HMM模型
DiscreteHMM_test.py及GaussianHMM_test.py:利用unnitest来测试我们的HMM,同时引入了一个经典HMM库hmmlearn作为对照组
Dice_01.py:利用离散HMM模型来解决丢色子问题的例子
Wordseg_02.py:解决中文分词问题的例子
Stock_03.py:解决股票预测问题的例子
2. 隐马尔科夫链HMM的背景
首先,已知一组序列 :

我们从这组序列中推导出产生这组序列的函数,假设函数参数为 ,其表示为
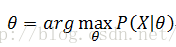
即使得序列X发生概率最大的函数参数,要解决上式,最简单的考虑是将序列 的每个数据都视为独立的,比如建立一个神经网络。然后这种考虑会随着序列增长,而导致参数爆炸式增长。因此可以假设当前序列数据只与其前一数据值相关,即所谓的一阶马尔科夫链:

有一阶马尔科夫链,也会有二阶马尔科夫链(即当前数据值取决于其前两个数据值)
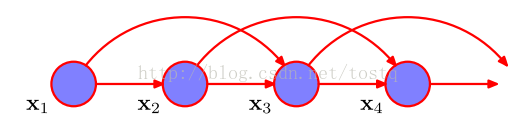
当前本文不对二阶马尔科夫链进行深入分析了,着重考虑一阶马尔科夫链,现在根据一阶马尔科夫链的假设,我们有:
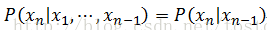
因此要解一阶马尔科夫链,其关键在于求数据(以下称观测值)之间转换函数 ,如果假设转换函数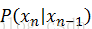
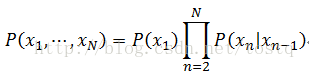
然而,如果观测值x的状态非常多(特别极端的情况是连续数据),转换函数
为了降低马尔科夫链的转换函数的参数量,我们引入了一个包含较少状态的隐状态值,将观测值的马尔科夫链转换为隐状态的马尔科夫链(即为隐马尔科夫链HMM)
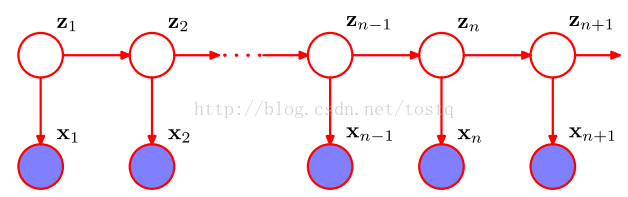
其包含了一个重要假设:当前观测值只由当前隐状态所决定。这么做的一个重要好处是,隐状态值的状态远小于观测值的状态,因此隐藏状态的转换函数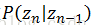
此时我们要决定的问题是:
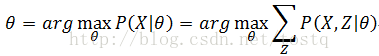
即在所有可能隐藏状态序列情况下,求使得序列 发生概率最大的函数参数 。
这里我们再总结下:
隐马尔科夫链HMM三个重要假设:
1. 当前观测值只由当前隐藏状态确定,而与其他隐藏状态或观测值无关(隐藏状态假设)
2. 当前隐藏状态由其前一个隐藏状态决定(一阶马尔科夫假设)
3. 隐藏状态之间的转换函数概率不随时间变化(转换函数稳定性假设)
隐马尔科夫链HMM所要解决的问题:
在所有可能隐藏状态序列情况下,求使得当前序列X产生概率最大的函数参数θ。

















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









