







原创文章
转载请注册来源
http://blog.csdn.net/tostq
上一节我们介绍了卷积神经网络的前向传播过程,这一节我们重点介绍反向传播过程,反向传播过程反映神经网络的学习训练过程。
误差反向传播方法是神经网络学习的基础,网络上已经有许多相关的内容了,不过关于卷积网络的误差反向传递的公式推导却比较少,而且也不是很清晰,本文将会详细推导这个过程,虽然内容很复杂,但却值得学习.
首先我们需要知道的是
误差反向传播的
学习方法,实际是梯度下降法求最小误差的权重过程。当然
我们的目的是求误差能量关于参数(权重)的导数.
梯度下降法更新权重公式如下所示:
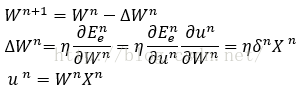
这里W表示权重,E表示误差能量,n表示第n轮更新迭代,η表示学习参数,Y表示输出,δ表示局域梯度。
而另一方面误差能量关于参数(权重)的导数同当前层输入是相关的,所以我们需要一个更好地将当前层误差传递给下一层的量,因为这个
δ同当前层的输出无关,其只是反映了当前层的固定结构,所以我们可以将这个固有性质δ反向传递给下一层,其定义为:

接下来我们分层分析整个网络的反向传播过程。
在本文的卷积神经网络中主要有以下四种情况:
一、输出层(单层神经网络层)
(1)误差能量定义为实际输出与理想输出的误差
这里的d是理想预期输出,y指实际输出,i指输出位,本文的网络输出为10位,所以N=10.
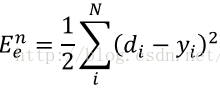
(2)
误差能量关于参数(权重)的导数。
这一层是比较简单的
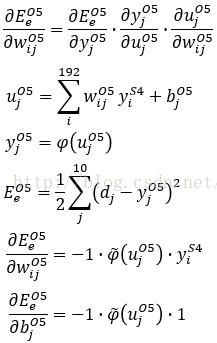
由于本文是采用Sigmoid系数的激活函数,所以其导数可以求出为:
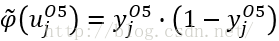
其
局域梯度
δ表示为:
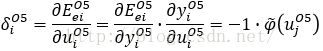
二、后接输出层的采样层S4
后接输出层的采样层向多层感知器的隐藏神经元的反向传播是类似的。
由于这一层没有权重,所以不需要进行权重更新,但是我们也需要将误差能量传递给下一层,所以需要计算
局域梯度δ,其定义如下,这里j指输出图像中的像素序号,S4层共有12*4*4=192个输出像素,所以j=1~192。
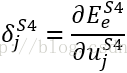
另外输出层O5的局域梯度δ也已经计算过了:
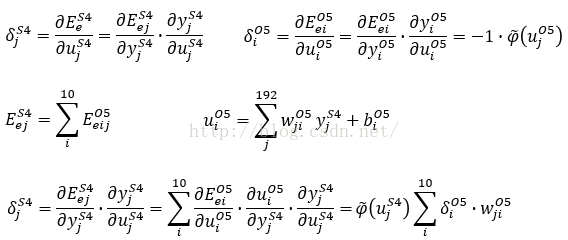
由于采样层没有激活函数,所以φ的导数为1,则最终可以得到

通过上式,我们就可以算出由输出层O5传递到S4层的局域梯度δ值。
可以看出传递到采样层各输出像素j的
局域梯度
δ值,实际是相当于与其相连的下层输出的局域梯度δ值乘上相连权重的总和。
三、后接采样层的卷积层C1、C3
前面为了方便计算,S4层和O5层
的输出都被展开成了一维,所以像素都是以i和j作为标号的,到了C3层往前,我们以像素的坐标m(x,y)来标号,m(x,y)表示第m张输出模板的(x,y)位置的像素。局域梯度δ值定义为:
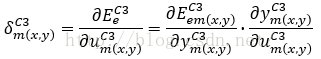
传递到该像素的误差能量等于所有与其相连的像素误差能量和,这里的i指的m(x,y)采样邻域Θ内的所有像素
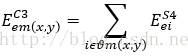
因为本文采用的是平均Pooling方法,
S4的输出就是该像素邻域内的所有像素的平均值,这里的S指邻域Θ内的所有像素的总数,本文采用的是2*2的采样块,所以S=4。
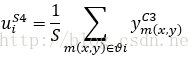
(1)
因此
由S4传递到C3层的
局域梯度
δ值为:
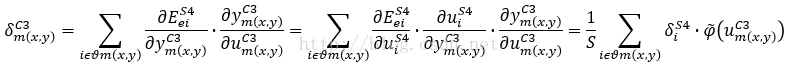
接下来我们依据局域梯度δ值,来计算C3层的权重更新值。
(2)C3层的权重更新值。
C3层共有6*12个5*5的模板,我们首先定义n=1~6,m=1~12表示模板的标号,s,t表示模板中参数的位置
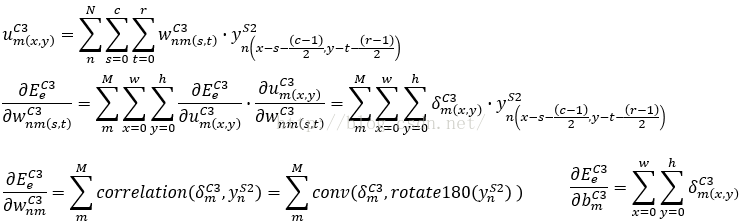
(3)C1层的权重更新公式和局域梯度δ值
同理,我们也可以得到C1层的权重更新公式,这里的M=6,N=1,而y是指输入图像
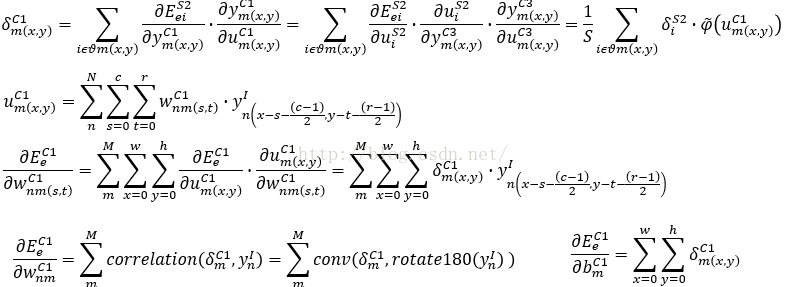
四、后接卷积层的采样层S2
这里的n为当前S2层的输出图像序号(n=1~6),n为当前C3层的输出图像序号(m=1~12)。
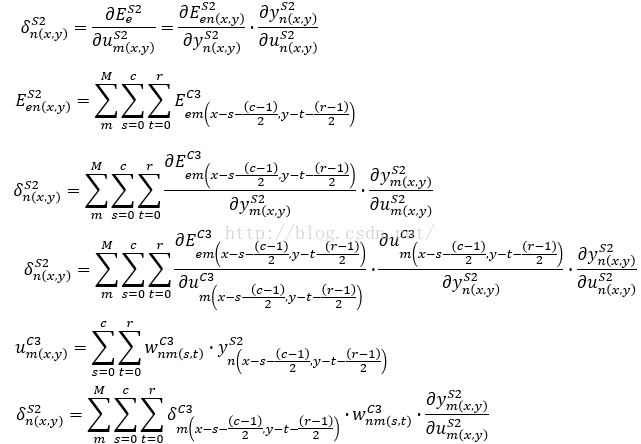
因此第n块图像的局域梯度δ值为

五、误差反向传播过程的代码展示
void cnnbp(CNN* cnn,float* outputData) // 网络的后向传播
{
int i,j,c,r; // 将误差保存到网络中
for(i=0;i<cnn->O5->outputNum;i++)
cnn->e[i]=cnn->O5->y[i]-outputData[i];
/*从后向前反向计算*/
// 输出层O5
for(i=0;i<cnn->O5->outputNum;i++)
cnn->O5->d[i]=cnn->e[i]*sigma_derivation(cnn->O5->y[i]);
// S4层,传递到S4层的误差
// 这里没有激活函数
nSize outSize={cnn->S4->inputWidth/cnn->S4->mapSize,cnn->S4->inputHeight/cnn->S4->mapSize};
for(i=0;i<cnn->S4->outChannels;i++)
for(r=0;r<outSize.r;r++)
for(c=0;c<outSize.c;c++)
for(j=0;j<cnn->O5->outputNum;j++){
int wInt=i*outSize.c*outSize.r+r*outSize.c+c;
cnn->S4->d[i][r][c]=cnn->S4->d[i][r][c]+cnn->O5->d[j]*cnn->O5->wData[j][wInt];
}
// C3层
// 由S4层传递的各反向误差,这里只是在S4的梯度上扩充一倍
int mapdata=cnn->S4->mapSize;
nSize S4dSize={cnn->S4->inputWidth/cnn->S4->mapSize,cnn->S4->inputHeight/cnn->S4->mapSize};
// 这里的Pooling是求平均,所以反向传递到下一神经元的误差梯度没有变化
for(i=0;i<cnn->C3->outChannels;i++){
float** C3e=UpSample(cnn->S4->d[i],S4dSize,cnn->S4->mapSize,cnn->S4->mapSize);
for(r=0;r<cnn->S4->inputHeight;r++)
for(c=0;c<cnn->S4->inputWidth;c++)
cnn->C3->d[i][r][c]=C3e[r][c]*sigma_derivation(cnn->C3->y[i][r][c])/(float)(cnn->S4->mapSize*cnn->S4->mapSize);
for(r=0;r<cnn->S4->inputHeight;r++)
free(C3e[r]);
free(C3e);
}
// S2层,S2层没有激活函数,这里只有卷积层有激活函数部分
// 由卷积层传递给采样层的误差梯度,这里卷积层共有6*12个卷积模板
outSize.c=cnn->C3->inputWidth;
outSize.r=cnn->C3->inputHeight;
nSize inSize={cnn->S4->inputWidth,cnn->S4->inputHeight};
nSize mapSize={cnn->C3->mapSize,cnn->C3->mapSize};
for(i=0;i<cnn->S2->outChannels;i++){
for(j=0;j<cnn->C3->outChannels;j++){
float** corr=correlation(cnn->C3->mapData[i][j],mapSize,cnn->C3->d[j],inSize,full);
addmat(cnn->S2->d[i],cnn->S2->d[i],outSize,corr,outSize);
for(r=0;r<outSize.r;r++)
free(corr[r]);
free(corr);
}
/*
for(r=0;r<cnn->C3->inputHeight;r++)
for(c=0;c<cnn->C3->inputWidth;c++)
// 这里本来用于采样的激活
*/
}
// C1层,卷积层
mapdata=cnn->S2->mapSize;
nSize S2dSize={cnn->S2->inputWidth/cnn->S2->mapSize,cnn->S2->inputHeight/cnn->S2->mapSize};
// 这里的Pooling是求平均,所以反向传递到下一神经元的误差梯度没有变化
for(i=0;i<cnn->C1->outChannels;i++){
float** C1e=UpSample(cnn->S2->d[i],S2dSize,cnn->S2->mapSize,cnn->S2->mapSize);
for(r=0;r<cnn->S2->inputHeight;r++)
for(c=0;c<cnn->S2->inputWidth;c++)
cnn->C1->d[i][r][c]=C1e[r][c]*sigma_derivation(cnn->C1->y[i][r][c])/(float)(cnn->S2->mapSize*cnn->S2->mapSize);
for(r=0;r<cnn->S2->inputHeight;r++)
free(C1e[r]);
free(C1e);
}
}

















 1274
1274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









