







 本文详细介绍了如何使用MapReduce在Hadoop系统上实现图的三角形计数任务,针对Twitter局部关系图,通过四个Job分别完成度统计、排序、边转换和三角形计数。实验还探讨了数据优化策略,如节点顺序化和使用Sequence文件,以提高性能。
本文详细介绍了如何使用MapReduce在Hadoop系统上实现图的三角形计数任务,针对Twitter局部关系图,通过四个Job分别完成度统计、排序、边转换和三角形计数。实验还探讨了数据优化策略,如节点顺序化和使用Sequence文件,以提高性能。
源代码放在我的github上,想细致了解的可以访问:TriangleCount on github
一、实验要求
1.1 实验背景
图的三角形计数问题是一个基本的图计算问题,是很多复杂网络分析(比如社交网络分析)的基础。目前图的三角形计数问题已经成为了 Spark 系统中 GraphX 图计算库所提供的一个算法级 API。本次实验任务就是要在 Hadoop 系统上实现图的三角形计数任务。
1.2 实验任务
一个社交网络可以看做是一张图(离散数学中的图)。社交网络中的人对应于图的顶点;社交网络中的人际关系对应于图中的边。在本次实验任务中,我们只考虑一种关系——用户之间的关注关系。假设“王五”在 Twitter/微博中关注了“李四”,则在社交网络图中,有一条对应的从“王五”指向“李四”的有向边。图 1 中展示了一个简单的社交网络图,人之间的关注关系通过图中的有向边标识了出来。本次的实验任务就是在给定的社交网络图中,统计图中所有三角形的数量。在统计前,需要先进行有向边到无向边的转换,依据如下逻辑转换:
请在无向图上统计三角形的个数。在图 1 的例子中,一共有 3 个三角形。
本次实验将提供一个 Twitter 局部关系图作为输入数据(给出的图是有向图),请统计该图对应的无向图中的三角形个数。
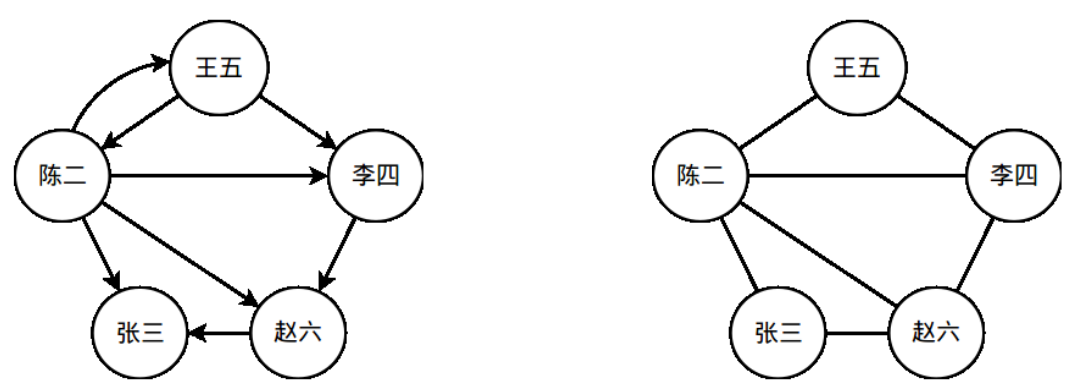
图 1 一个简单的社交网络示例。左侧的是一个社交网络图,右侧的图是将左侧图中的有向边转换为无向边后的无向图。
1.3 输入说明
输入数据仅一个文件。该文件由若干行组成,每一行由两个以空格分隔的整数组成:
A,B 分别是两个顶点的 ID。这一行记录表示图中具有一条由 A 到 B 的有向边。整个图的结构由该文件唯一确定。
下面的框中是文件部分内容的示例:
87982906 17975898
17809581 35664799
524620711 270231980
247583674 230498574
348281617 255810948
159294262 230766095
14927205 5380672
1.4 扩展
-
扩展一:挑战更大的数据集!使用 Google+的社交关系网数据集作为输入数据集。
-
扩展二:考虑将逻辑转换由or改为and的三角形个数是多少,改变后的逻辑转换如下:
二、实验设计与实现
2.1 算法设计
- step1:统计图中每一个点的度,不关心是入度还是出度,然后对统计到的所有点的度进行排序
- step2:将图中每一条单向边转换成双向边,对于图中a->b and b->a的两条边,分别转换后需要去重,在转换后的图中筛选出小度指向大度的边来建立邻接表,然后对每个点的邻接点按从小到大进行排序
- step3:对原图中的边进行转换,确保每条边是由数值小的点指向数值大的点并去重,然后遍历每一条边:求边的两个端点对应的邻接点集的交集大小即为包含这条边的三角形个数。对每条边对应的三角形个数进行累加即可得到全图包含的三角形个数。
2.2 程序设计
- 根据算法步骤将程序设计成4个job来实现:
- job:OutDegreeStat用于对每个点的度进行统计,在类OutDegreeStat中实现
- job:SortedOutDegree用于对所有点的度进行排序,在类OutDegreeStat中实现,在job1之后运行
- job:EdgeConvert用于建立存储小度指向大度的边的邻接表,在类EdgeConvert中实现
- job:GraphTriangleCount用于遍历每条边求端点对应邻接点集的交集来对三角形进行计数,在类GraphTriangleCount中实现
2.3 程序实现
-
job:OutDegreeStat的实现:
-
Map阶段:(vertex1: Text, vertex2: Text) -> (vertex1: Text, 1: IntWritable) and (vertex2: Text, 1: IntWritable),实现代码如下:
public static class OutDegreeStatMapper extends Mapper<Object, Text, Text, IntWritable> { private final IntWritable one = new IntWritable(1); @Override public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer itr = new StringTokenizer(line); Text vertex1 = new Text(itr.nextToken()); Text vertex2 = new Text(itr.nextToken()); if (!vertex1.equals(vertex2)) { context.write(vertex1, one); context.write(vertex2, one); } } } -
Reduce阶段:(vertex: Text, degree: Iterable<IntWritable>) -> (vertex: Text, degreeSum: IntWritable),实现代码如下:
public static class OutDegreeStatReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val: values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } -
Combiner阶段:Combiner逻辑与Reduce逻辑一致,只是为了减少数据量从而减少通信开销
-
-
job:SortedOutDegree的实现:
- Map阶段:由于mapreduce的reduce阶段会按key进行排序,为了按度进行排序,只需用hadoop自带的InverseMapper类对键值对做逆映射(vertex: Text, degree: IntWritable) -> (degree: IntWritable, vertex: Text)即可。
- Reduce阶段:无需设置Reducer类,hadoop的Reduce阶段自动会对degree进行排序
-
job:EdgeConvert的实现:
-
Map阶段:(vertex1: Text, vertex2: Text) -> (vertex1: Text, vertex2: Text) and (vertex2: Text, vertex1: Text),实现代码如下:
public static class EdgeConvertMapper extends Mapper<Object, Text, Text, Text> { @Override public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); Text vertex1 = new Text(itr.nextToken()); Text vertex2 = new Text(itr.nextToken()); if (!vertex1.equals(vertex2)) { context.write(vertex1, vertex2); context.write(vertex2, vertex1); } } } -
Reduce阶段:在setup函数中读取存储节点度的文件
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 799
799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









