






在https://www.yuque.com/treblez/qksu6c/ahgvn94c2nh1y34w?singleDoc# 《Redis集群:分布式的less is more》中我提到,无论是啥服务,想要达到操作视角的强一致性,要么使用类似TSO/原子钟的方案,要么有一套一致性协调服务。
clickhouse最初是用zookeeper的,在 21.8 版本中开始引入了 ClickHouse-Keeper ,直至 ClickHouse 21.12 发布公告提到 ClickHouse Keeper 功能基本完成。ClickHouse Keeper 是 ZooKeeper 的替代品,与 ZooKeeper 不同,ClickHouse Keeper 是用 C++ 编写的,并使用 RAFT 算法实现,该算法允许对读写具有线性化能力,具有多种不同语言的开源实现。
为什么要引入clickhouse-keeper呢?主要是ck使用zookeeper有着众多痛点
- 使用java开发
- 运维不便
- 要求独立部署
- zxid overflow问题
- snapshot和log没有经过压缩
- 不支持读的线性一致性
而ck-keeper存在着以下优点:
- 使用c++开发,技术栈与ck统一
- 即可独立部署,又可集成到ck中
- 没有zxid overflow问题
- 读性能更好,写性能相当
- 支持对snapshot和log的压缩和校验
- 支持读写的线性一致性
关于raft的知识点今天就不多讲了,感兴趣的可以看我之前写的https://blog.csdn.net/treblez/article/details/121577049?spm=1001.2014.3001.5502 。
今天主要是结合官方的博客[1],看看clickhouse keeper的源码实现,因为keeper用到了线程池,所以我们也会介绍一下ck的线程池。
[1] 下文的博客都是指这一篇 https://clickhouse.com/blog/clickhouse-keeper-a-zookeeper-alternative-written-in-cpp
线性一致
性能
值得注意的是,比较ck keeper和zookeeper大多数情况是在比较ZAB和Nuraft。
博客中提供了一个直观的图,这表明相同数据量和性能下,keeper具有更少的指令周期和更高的ipc,同时内存占用更少。
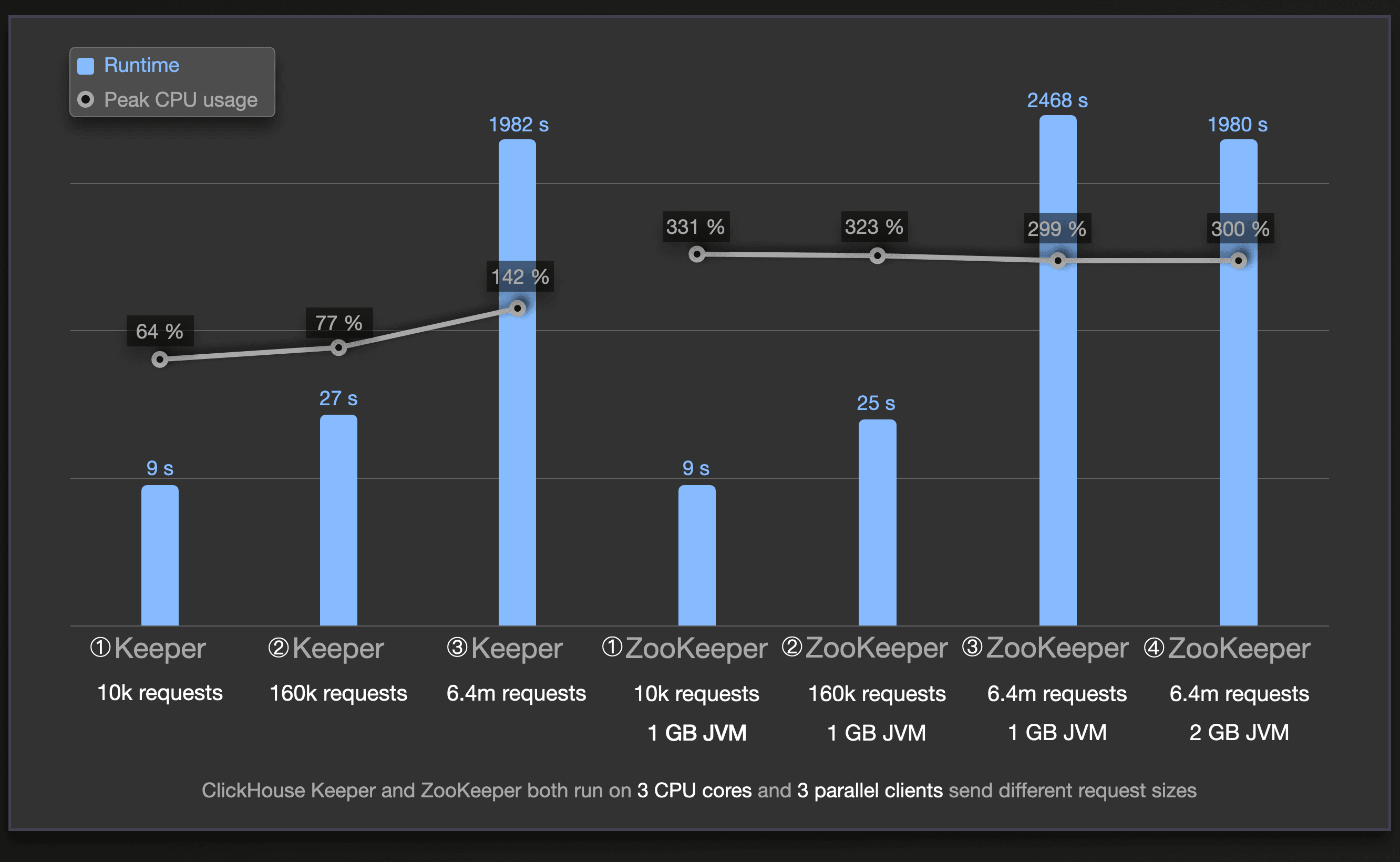
线性一致写
keeper和zookeeper在写上具有相同的一致性。
zookeeper通过SyncRequestProcessor做到强一致,keeper则通过single-threaded global queue做到强一致(如下图所示)。

这两个方案都没法做到垂直或者水平扩容:

但是cycles上keeper显然有巨大优势。我们看下这里的源码。
zookeeper
首先是zookeeper
SyncRequestProcessor在三种不同的情况下使用:
- Leader(领导者):
同步请求到磁盘,并将其转发到AckRequestProcessor,后者将确认(ack)返回给自身。
- Follower(跟随者):
同步请求到磁盘,并将请求转发到SendAckRequestProcessor,后者将数据包发送到领导者。
SendAckRequestProcessor是可刷新(flushable)的,允许强制推送数据包到领导者。
- Observer(观察者):
同步已提交的请求到磁盘(以INFORM数据包形式接收)。
不向领导者发送确认(ack),因此nextProcessor将为null。
这改变了观察者上的事务日志(txnlog)的语义,因为它仅包含已提交的事务。
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.zookeeper.server;
import java.io.Flushable;
import java.io.IOException;
import java.util.ArrayDeque;
import java.util.Objects;
import java.util.Queue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.Semaphore;
import java.util.concurrent.ThreadLocalRandom;
import java.util.concurrent.TimeUnit;
import org.apache.zookeeper.common.Time;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* This RequestProcessor logs requests to disk. It batches the requests to do
* the io efficiently. The request is not passed to the next RequestProcessor
* until its log has been synced to disk.
*
* SyncRequestProcessor is used in 3 different cases
* 1. Leader - Sync request to disk and forward it to AckRequestProcessor which
* send ack back to itself.
* 2. Follower - Sync request to disk and forward request to
* SendAckRequestProcessor which send the packets to leader.
* SendAckRequestProcessor is flushable which allow us to force
* push packets to leader.
* 3. Observer - Sync committed request to disk (received as INFORM packet).
* It never send ack back to the leader, so the nextProcessor will
* be null. This change the semantic of txnlog on the observer
* since it only contains committed txns.
*/
public class SyncRequestProcessor extends ZooKeeperCriticalThread implements RequestProcessor {
private static final Logger LOG = LoggerFactory.getLogger(SyncRequestProcessor.class);
private static final Request REQUEST_OF_DEATH = Request.requestOfDeath;
/** The number of log entries to log before starting a snapshot */
private static int snapCount = ZooKeeperServer.getSnapCount();
/**
* The total size of log entries before starting a snapshot
*/
private static long snapSizeInBytes = ZooKeeperServer.getSnapSizeInBytes();
/**
* Random numbers used to vary snapshot timing
*/
private int randRoll;
private long randSize;
private final BlockingQueue<Request> queuedRequests = new LinkedBlockingQueue<>();
private final Semaphore snapThreadMutex = new Semaphore(1);
private final ZooKeeperServer zks;
private final RequestProcessor nextProcessor;
/**
* Transactions that have been written and are waiting to be flushed to
* disk. Basically this is the list of SyncItems whose callbacks will be
* invoked after flush returns successfully.
*/
private final Queue<Request> toFlush;
private long lastFlushTime;
public SyncRequestProcessor(ZooKeeperServer zks, RequestProcessor nextProcessor) {
super("SyncThread:" + zks.getServerId(), zks.getZooKeeperServerListener());
this.zks = zks;
this.nextProcessor = nextProcessor;
this.toFlush = new ArrayDeque<>(zks.getMaxBatchSize());
}
/**
* used by tests to check for changing
* snapcounts
* @param count
*/
public static void setSnapCount(int count) {
snapCount = count;
}
/**
* used by tests to get the snapcount
* @return the snapcount
*/
public static int getSnapCount() {
return snapCount;
}
private long getRemainingDelay() {
long flushDelay = zks.getFlushDelay();
long duration = Time.currentElapsedTime() - lastFlushTime;
if (duration < flushDelay) {
return flushDelay - duration;
}
return 0;
}
/** If both flushDelay and maxMaxBatchSize are set (bigger than 0), flush
* whenever either condition is hit. If only one or the other is
* set, flush only when the relevant condition is hit.
*/
private boolean shouldFlush() {
long flushDelay = zks.getFlushDelay();
long maxBatchSize = zks.getMaxBatchSize();
if ((flushDelay > 0) && (getRemainingDelay() == 0)) {
return true;
}
return (maxBatchSize > 0) && (toFlush.size() >= maxBatchSize);
}
/**
* used by tests to check for changing
* snapcounts
* @param size
*/
public static void setSnapSizeInBytes(long size) {
snapSizeInBytes = size;
}
private boolean shouldSnapshot() {
int logCount = zks.getZKDatabase().getTxnCount();
long logSize = zks.getZKDatabase().getTxnSize();
return (logCount > (snapCount / 2 + randRoll))
|| (snapSizeInBytes > 0 && logSize > (snapSizeInBytes / 2 + randSize));
}
private void resetSnapshotStats() {
randRoll = ThreadLocalRandom.current().nextInt(snapCount / 2);
randSize = Math.abs(ThreadLocalRandom.current().nextLong() % (snapSizeInBytes / 2));
}
@Override
public void run() {
try {
// we do this in an attempt to ensure that not all of the servers
// in the ensemble take a snapshot at the same time
resetSnapshotStats();
lastFlushTime = Time.currentElapsedTime();
while (true) {
ServerMetrics.getMetrics().SYNC_PROCESSOR_QUEUE_SIZE.add(queuedRequests.size());
long pollTime = Math.min(zks.getMaxWriteQueuePollTime(), getRemainingDelay());
Request si = queuedRequests.poll(pollTime, TimeUnit.MILLISECONDS);
if (si == null) {
/* We timed out looking for more writes to batch, go ahead and flush immediately */
flush();
si = queuedRequests.take();
}
if (si == REQUEST_OF_DEATH) {
break;
}
long startProcessTime = Time.currentElapsedTime();
ServerMetrics.getMetrics().SYNC_PROCESSOR_QUEUE_TIME.add(startProcessTime - si.syncQueueStartTime);
// track the number of records written to the log
if (!si.isThrottled() && zks.getZKDatabase().append(si)) {
if (shouldSnapshot()) {
resetSnapshotStats();
// roll the log
zks.getZKDatabase().rollLog();
// take a snapshot
if (!snapThreadMutex.tryAcquire()) {
LOG.warn("Too busy to snap, skipping");
} else {
new ZooKeeperThread("Snapshot Thread") {
public void run() {
try {
zks.takeSnapshot();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
snapThreadMutex.release();
}
}
}.start();
}
}
} else if (toFlush.isEmpty()) {
// optimization for read heavy workloads
// iff this is a read or a throttled request(which doesn't need to be written to the disk),
// and there are no pending flushes (writes), then just pass this to the next processor
if (nextProcessor != null) {
nextProcessor.processRequest(si);
if (nextProcessor instanceof Flushable) {
((Flushable) nextProcessor).flush();
}
}
continue;
}
toFlush.add(si);
if (shouldFlush()) {
flush();
}
ServerMetrics.getMetrics().SYNC_PROCESS_TIME.add(Time.currentElapsedTime() - startProcessTime);
}
} catch (Throwable t) {
handleException(this.getName(), t);
}
LOG.info("SyncRequestProcessor exited!");
}
private void flush() throws IOException, RequestProcessorException {
if (this.toFlush.isEmpty()) {
return;
}
ServerMetrics.getMetrics().BATCH_SIZE.add(toFlush.size());
long flushStartTime = Time.currentElapsedTime();
zks.getZKDatabase().commit();
ServerMetrics.getMetrics().SYNC_PROCESSOR_FLUSH_TIME.add(Time.currentElapsedTime() - flushStartTime);
if (this.nextProcessor == null) {
this.toFlush.clear();
} else {
while (!this.toFlush.isEmpty()) {
final Request i = this.toFlush.remove();
long latency = Time.currentElapsedTime() - i.syncQueueStartTime;
ServerMetrics.getMetrics().SYNC_PROCESSOR_QUEUE_AND_FLUSH_TIME.add(latency);
this.nextProcessor.processRequest(i);
}
if (this.nextProcessor instanceof Flushable) {
((Flushable) this.nextProcessor).flush();
}
}
lastFlushTime = Time.currentElapsedTime();
}
public void shutdown() {
LOG.info("Shutting down");
queuedRequests.add(REQUEST_OF_DEATH);
try {
this.join();
this.flush();
} catch (InterruptedException e) {
LOG.warn("Interrupted while wating for {} to finish", this);
Thread.currentThread().interrupt();
} catch (IOException e) {
LOG.warn("Got IO exception during shutdown");
} catch (RequestProcessorException e) {
LOG.warn("Got request processor exception during shutdown");
}
if (nextProcessor != null) {
nextProcessor.shutdown();
}
}
public void processRequest(final Request request) {
Objects.requireNonNull(request, "Request cannot be null");
request.syncQueueStartTime = Time.currentElapsedTime();
queuedRequests.add(request);
ServerMetrics.getMetrics().SYNC_PROCESSOR_QUEUED.add(1);
}
}
SyncRequestProcessor是单线程原因在于Zookeeper Server是单例的,它在这里(https://github.com/apache/zookeeper/blob/d79811bf28f00fb1db6ec6002e884af6cfd0d7fc/zookeeper-server/src/main/java/org/apache/zookeeper/server/ZooKeeperServer.java#L847)被初始化:
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor syncProcessor = new SyncRequestProcessor(this, finalProcessor);
((SyncRequestProcessor) syncProcessor).start();
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
((PrepRequestProcessor) firstProcessor).start();
}
clickhouse keeper
nuraft也是一样,用了一个单线程队列:
void nuraft_global_mgr::request_commit(ptr<raft_server> server) {
{
std::lock_guard<std::mutex> l(commit_queue_lock_);
// First search the set if the server is duplicate.
auto entry = commit_server_set_.find(server);
if (entry != commit_server_set_.end()) {
// `server` is already in the queue. Ignore it.
return;
}
// Put into queue.
commit_queue_.push_back(server);
commit_server_set_.insert(server);
ptr<logger>& l_ = server->l_;
p_tr("added commit request to global queue, "
"server %p, queue length %zu",
server.get(),
commit_queue_.size());
}
// Find a sleeping worker and invoke.
for (auto& entry: commit_workers_) {
ptr<worker_handle>& wh = entry;
if (wh->status_ == worker_handle::SLEEPING) {
wh->ea_.invoke();
break;
}
}
// If all workers are working, nothing to do for now.
}
线性一致读
首先我们看zookeeper官方文档,理解zookeeper提供的一致性级别。
The consistency guarantees of ZooKeeper lie between sequential consistency and linearizability. In this section, we explain the exact consistency guarantees that ZooKeeper provides.
Write operations in ZooKeeper are linearizable. In other words, each write will appear to take effect atomically at some point between when the client issues the request and receives the corresponding response. This means that the writes performed by all the clients in ZooKeeper can be totally ordered in such a way that respects the real-time ordering of these writes. However, merely stating that write operations are linearizable is meaningless unless we also talk about read operations.
Read operations in ZooKeeper are not linearizable since they can return potentially stale data. This is because a read in ZooKeeper is not a quorum operation and a server will respond immediately to a client that is performing a read. ZooKeeper does this because it prioritizes performance over consistency for the read use case. However, reads in ZooKeeper are sequentially consistent, because read operations will appear to take effect in some sequential order that furthermore respects the order of each client’s operations. A common pattern to work around this is to issue a sync before issuing a read. This too does not strictly guarantee up-to-date data because sync is not currently a quorum operation. To illustrate, consider a scenario where two servers simultaneously think they are the leader, something that could occur if the TCP connection timeout is smaller than syncLimit * tickTime. Note that this is unlikely to occur in practice, but should be kept in mind nevertheless when discussing strict theoretical guarantees. Under this scenario, it is possible that the sync is served by the “leader” with stale data, thereby allowing the following read to be stale as well. The stronger guarantee of linearizability is provided if an actual quorum operation (e.g., a write) is performed before a read.
Overall, the consistency guarantees of ZooKeeper are formally captured by the notion of ordered sequential consistency or OSC(U) to be exact, which lies between sequential consistency and linearizability.
从这里面我们知道zookeeper提供的是线性一致性写和顺序一致性读。也就是OSC(U)。关于OSC(U)有一段形式化定义:

简单来说就是OSC3保证了前缀一致性,OSC2保证了顺序一致性,OSC1保证了写操作的线性一致性。
而CK keeper提供了读操作的线性一致性,是怎么做到的呢?
我们考虑raft协议的一致性。我们都知道,raft是一种共识协议,客户端的操作决定了读写的一致性。
顺序一致读:读固定follwer的已应用索引 (applied index)的最新数据
线性一致读:
- etcd的方案 如果当前节点只是一个 Follower,它首先会从 Leader 获取集群最新的已提交的日志索引 (committed index)。然后等待直到状态机已应用索引 (applied index) 大于等于 Leader 的已提交索引时 (committed Index),再读取数据返回。
- 全量proposal 和write一样,将read作为一条proposal,当该entry能够提交到状态机执行读取时,leader可以将结果返回给调用方。
- 读index leader在发起读时记录当前的commitIndex,然后在后续heartbeat请求中如果能获得多数派对leadership的确认,那么可以等待commitIndex提交到状态机后即可返回结果。
那么clickhouse keeper是哪一种呢?
ck keeper给配置项起了一个非常具有迷惑性的名字:仲裁一致读。很容易让我们误解为类似于dynamo那种基于严格法定人数的仲裁一致,但其实raft没有这种方案。这种方案保证不了读写间的线性一致。
其实ck是全量proposal的方案,这个方案比起3来IO更多,因此还有一定的改进空间。
自动重复插入数据消除
keeper的第一个场景是自动重复插入数据消除:
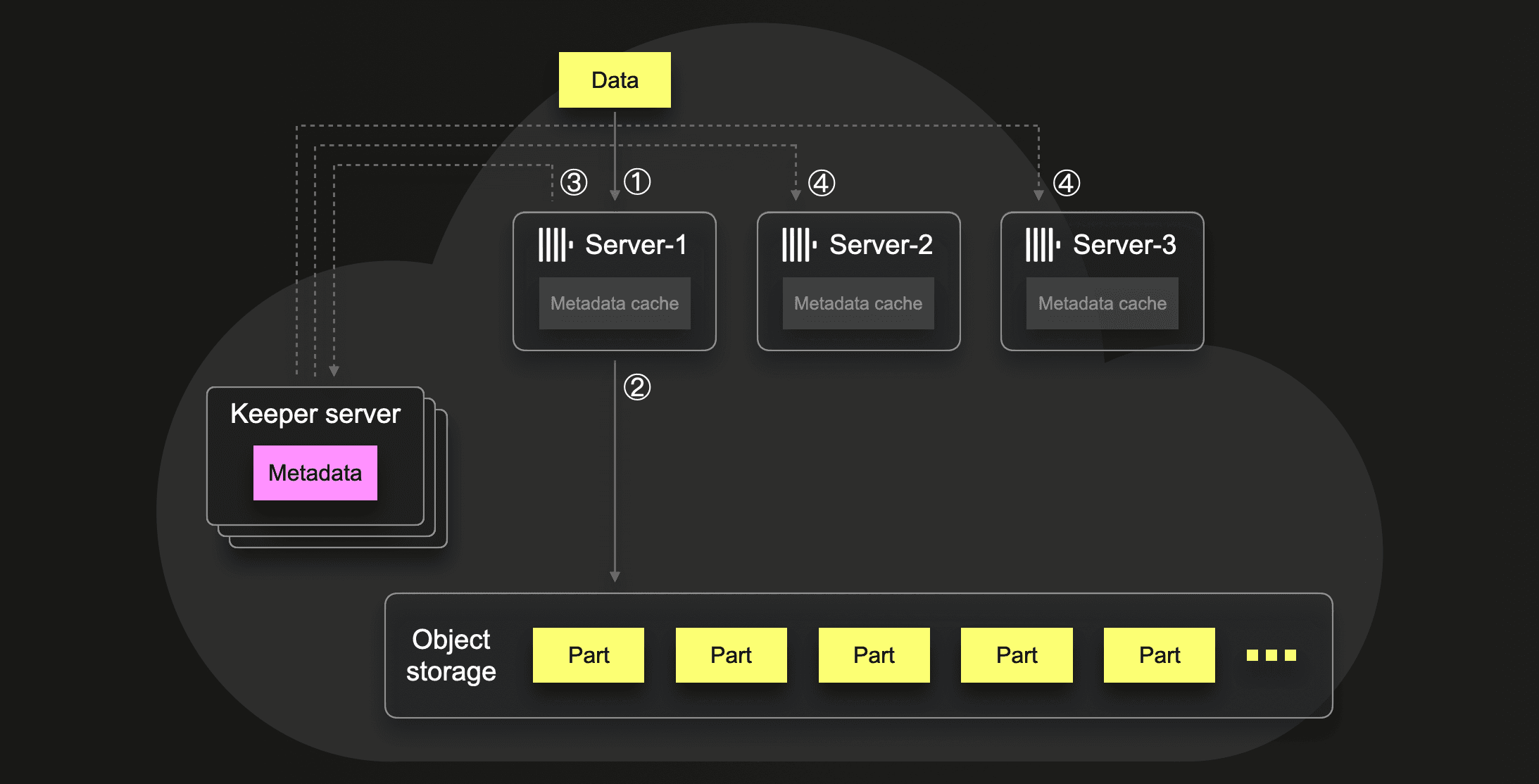
Server 1会在keeper中记录deduplication log的哈希和作为新插入数据的元数据,如果keeper中有相同的元数据就回滚,同时keeper会将元数据同步到其它server节点。
指定块合并
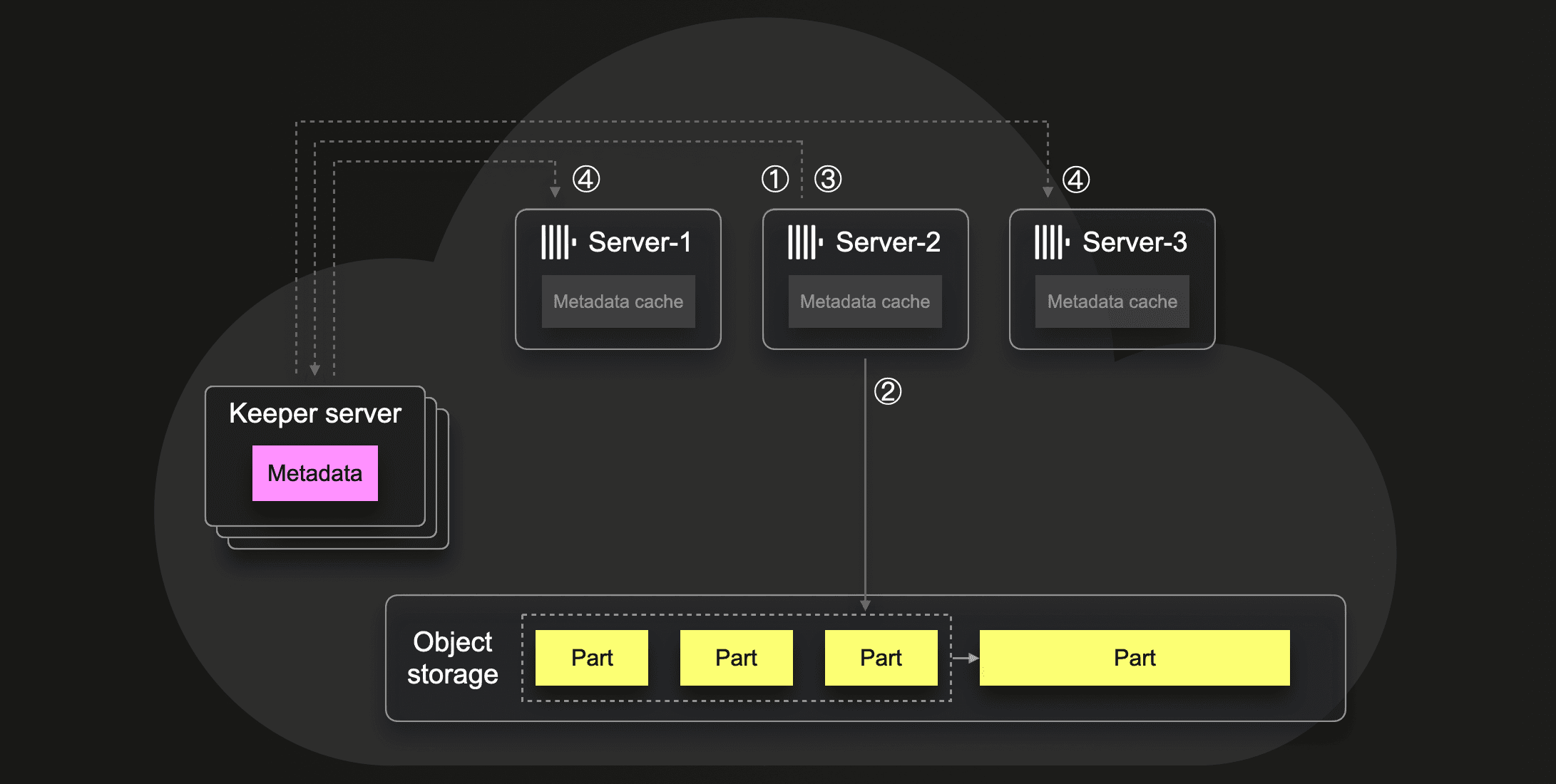
part合并时server先通过keeper锁定相应part,再进行合并,合并后通知其它server。
这里会用到keeper的all-or-nothing multi-write事务和线性一致写保障。
线程池
ThreadPool.h
clickhouse实现了一套类似boost::threadpool的线程池,不过比boost::threadpool好的地方在于可以在wait()后抛出第一个异常。
同时,clickhouse也实现了一个单例线程池,我们知道现在的编程范式是不鼓励单例的,那这个全局线程池优秀在哪儿呢?
- 因为避免了线性地址空间创建和销毁的开销,基于mutex和condvar的task线程池能够每秒处理200k个任务(而linux是100k),当然,这点不重要
- 对于TLD有较大的加速作用,尤其是使用jemalloc的时候,见 https://github.com/jemalloc/jemalloc/issues/1347
- AddressSanitizer和ThreadSanitizer这些分析工具不会因为pid太大失效
- 程序在gdb中运行的更快
线程池中有worker负责调度队列中的程序,这里用boost应该是因为stl的优先队列不支持迭代器。
#pragma once
#include <cstdint>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <functional>
#include <queue>
#include <list>
#include <optional>
#include <atomic>
#include <stack>
#include <boost/heap/priority_queue.hpp>
#include <Poco/Event.h>
#include <Common/ThreadStatus.h>
#include <Common/OpenTelemetryTraceContext.h>
#include <Common/CurrentMetrics.h>
#include <Common/ThreadPool_fwd.h>
#include <Common/Priority.h>
#include <Common/StackTrace.h>
#include <Common/Exception.h>
#include <base/scope_guard.h>
/** Very simple thread pool similar to boost::threadpool.
* Advantages:
* - catches exceptions and rethrows on wait.
*
* This thread pool can be used as a task queue.
* For example, you can create a thread pool with 10 threads (and queue of size 10) and schedule 1000 tasks
* - in this case you will be blocked to keep 10 tasks in fly.
*
* Thread: std::thread or something with identical interface.
*/
template <typename Thread>
class ThreadPoolImpl
{
public:
using Job = std::function<void()>;
using Metric = CurrentMetrics::Metric;
/// Maximum number of threads is based on the number of physical cores.
ThreadPoolImpl(Metric metric_threads_, Metric metric_active_threads_, Metric metric_scheduled_jobs_);
/// Size is constant. Up to num_threads are created on demand and then run until shutdown.
explicit ThreadPoolImpl(
Metric metric_threads_,
Metric metric_active_threads_,
Metric metric_scheduled_jobs_,
size_t max_threads_);
/// queue_size - maximum number of running plus scheduled jobs. It can be greater than max_threads. Zero means unlimited.
ThreadPoolImpl(
Metric metric_threads_,
Metric metric_active_threads_,
Metric metric_scheduled_jobs_,
size_t max_threads_,
size_t max_free_threads_,
size_t queue_size_,
bool shutdown_on_exception_ = true);
/// Add new job. Locks until number of scheduled jobs is less than maximum or exception in one of threads was thrown.
/// If any thread was throw an exception, first exception will be rethrown from this method,
/// and exception will be cleared.
/// Also throws an exception if cannot create thread.
/// Priority: lower is higher.
/// NOTE: Probably you should call wait() if exception was thrown. If some previously scheduled jobs are using some objects,
/// located on stack of current thread, the stack must not be unwinded until all jobs finished. However,
/// if ThreadPool is a local object, it will wait for all scheduled jobs in own destructor.
void scheduleOrThrowOnError(Job job, Priority priority = {});
/// Similar to scheduleOrThrowOnError(...). Wait for specified amount of time and schedule a job or return false.
bool trySchedule(Job job, Priority priority = {}, uint64_t wait_microseconds = 0) noexcept;
/// Similar to scheduleOrThrowOnError(...). Wait for specified amount of time and schedule a job or throw an exception.
void scheduleOrThrow(Job job, Priority priority = {}, uint64_t wait_microseconds = 0, bool propagate_opentelemetry_tracing_context = true);
/// Wait for all currently active jobs to be done.
/// You may call schedule and wait many times in arbitrary order.
/// If any thread was throw an exception, first exception will be rethrown from this method,
/// and exception will be cleared.
void wait();
/// Waits for all threads. Doesn't rethrow exceptions (use 'wait' method to rethrow exceptions).
/// You should not destroy object while calling schedule or wait methods from another threads.
~ThreadPoolImpl();
/// Returns number of running and scheduled jobs.
size_t active() const;
/// Returns true if the pool already terminated
/// (and any further scheduling will produce CANNOT_SCHEDULE_TASK exception)
bool finished() const;
void setMaxThreads(size_t value);
void setMaxFreeThreads(size_t value);
void setQueueSize(size_t value);
size_t getMaxThreads() const;
/// Adds a callback which is called in destructor after
/// joining of all threads. The order of calling callbacks
/// is reversed to the order of their addition.
/// It may be useful for static thread pools to call
/// function after joining of threads because order
/// of destructors of global static objects and callbacks
/// added by atexit is undefined for different translation units.
using OnDestroyCallback = std::function<void()>;
void addOnDestroyCallback(OnDestroyCallback && callback);
private:
mutable std::mutex mutex;
std::condition_variable job_finished;
std::condition_variable new_job_or_shutdown;
Metric metric_threads;
Metric metric_active_threads;
Metric metric_scheduled_jobs;
size_t max_threads;
size_t max_free_threads;
size_t queue_size;
size_t scheduled_jobs = 0;
bool shutdown = false;
bool threads_remove_themselves = true;
const bool shutdown_on_exception = true;
struct JobWithPriority
{
Job job;
Priority priority;
CurrentMetrics::Increment metric_increment;
DB::OpenTelemetry::TracingContextOnThread thread_trace_context;
/// Call stacks of all jobs' schedulings leading to this one
std::vector<StackTrace::FramePointers> frame_pointers;
bool enable_job_stack_trace = false;
JobWithPriority(
Job job_, Priority priority_, CurrentMetrics::Metric metric,
const DB::OpenTelemetry::TracingContextOnThread & thread_trace_context_,
bool capture_frame_pointers)
: job(job_), priority(priority_), metric_increment(metric),
thread_trace_context(thread_trace_context_), enable_job_stack_trace(capture_frame_pointers)
{
if (!capture_frame_pointers)
return;
/// Save all previous jobs call stacks and append with current
frame_pointers = DB::Exception::thread_frame_pointers;
frame_pointers.push_back(StackTrace().getFramePointers());
}
bool operator<(const JobWithPriority & rhs) const
{
return priority > rhs.priority; // Reversed for `priority_queue` max-heap to yield minimum value (i.e. highest priority) first
}
};
boost::heap::priority_queue<JobWithPriority> jobs;
std::list<Thread> threads;
std::exception_ptr first_exception;
std::stack<OnDestroyCallback> on_destroy_callbacks;
template <typename ReturnType>
ReturnType scheduleImpl(Job job, Priority priority, std::optional<uint64_t> wait_microseconds, bool propagate_opentelemetry_tracing_context = true);
void worker(typename std::list<Thread>::iterator thread_it);
/// Tries to start new threads if there are scheduled jobs and the limit `max_threads` is not reached. Must be called with `mutex` locked.
void startNewThreadsNoLock();
void finalize();
void onDestroy();
};
/// ThreadPool with std::thread for threads.
using FreeThreadPool = ThreadPoolImpl<std::thread>;
/** Global ThreadPool that can be used as a singleton.
* Why it is needed?
*
* Linux can create and destroy about 100 000 threads per second (quite good).
* With simple ThreadPool (based on mutex and condvar) you can assign about 200 000 tasks per second
* - not much difference comparing to not using a thread pool at all.
*
* But if you reuse OS threads instead of creating and destroying them, several benefits exist:
* - allocator performance will usually be better due to reuse of thread local caches, especially for jemalloc:
* https://github.com/jemalloc/jemalloc/issues/1347
* - address sanitizer and thread sanitizer will not fail due to global limit on number of created threads.
* - program will work faster in gdb;
*/
class GlobalThreadPool : public FreeThreadPool, private boost::noncopyable
{
static std::unique_ptr<GlobalThreadPool> the_instance;
GlobalThreadPool(
size_t max_threads_,
size_t max_free_threads_,
size_t queue_size_,
bool shutdown_on_exception_);
public:
static void initialize(size_t max_threads = 10000, size_t max_free_threads = 1000, size_t queue_size = 10000);
static GlobalThreadPool & instance();
};
/** Looks like std::thread but allocates threads in GlobalThreadPool.
* Also holds ThreadStatus for ClickHouse.
*
* NOTE: User code should use 'ThreadFromGlobalPool' declared below instead of directly using this class.
*
*/
template <bool propagate_opentelemetry_context = true>
class ThreadFromGlobalPoolImpl : boost::noncopyable
{
public:
ThreadFromGlobalPoolImpl() = default;
template <typename Function, typename... Args>
explicit ThreadFromGlobalPoolImpl(Function && func, Args &&... args)
: state(std::make_shared<State>())
{
/// NOTE:
/// - If this will throw an exception, the destructor won't be called
/// - this pointer cannot be passed in the lambda, since after detach() it will not be valid
GlobalThreadPool::instance().scheduleOrThrow([
my_state = state,
my_func = std::forward<Function>(func),
my_args = std::make_tuple(std::forward<Args>(args)...)]() mutable /// mutable is needed to destroy capture
{
SCOPE_EXIT(
my_state->thread_id = std::thread::id();
my_state->event.set();
);
my_state->thread_id = std::this_thread::get_id();
/// This moves are needed to destroy function and arguments before exit.
/// It will guarantee that after ThreadFromGlobalPool::join all captured params are destroyed.
auto function = std::move(my_func);
auto arguments = std::move(my_args);
/// Thread status holds raw pointer on query context, thus it always must be destroyed
/// before sending signal that permits to join this thread.
DB::ThreadStatus thread_status;
std::apply(function, arguments);
},
{}, // default priority
0, // default wait_microseconds
propagate_opentelemetry_context
);
}
ThreadFromGlobalPoolImpl(ThreadFromGlobalPoolImpl && rhs) noexcept
{
*this = std::move(rhs);
}
ThreadFromGlobalPoolImpl & operator=(ThreadFromGlobalPoolImpl && rhs) noexcept
{
if (initialized())
abort();
state = std::move(rhs.state);
return *this;
}
~ThreadFromGlobalPoolImpl()
{
if (initialized())
abort();
}
void join()
{
if (!initialized())
abort();
state->event.wait();
state.reset();
}
void detach()
{
if (!initialized())
abort();
state.reset();
}
bool joinable() const
{
if (!state)
return false;
/// Thread cannot join itself.
if (state->thread_id == std::this_thread::get_id())
return false;
return true;
}
std::thread::id get_id() const
{
return state ? state->thread_id.load() : std::thread::id{};
}
protected:
struct State
{
/// Should be atomic() because of possible concurrent access between
/// assignment and joinable() check.
std::atomic<std::thread::id> thread_id;
/// The state used in this object and inside the thread job.
Poco::Event event;
};
std::shared_ptr<State> state;
/// Internally initialized() should be used over joinable(),
/// since it is enough to know that the thread is initialized,
/// and ignore that fact that thread cannot join itself.
bool initialized() const
{
return static_cast<bool>(state);
}
};
/// Schedule jobs/tasks on global thread pool without implicit passing tracing context on current thread to underlying worker as parent tracing context.
///
/// If you implement your own job/task scheduling upon global thread pool or schedules a long time running job in a infinite loop way,
/// you need to use class, or you need to use ThreadFromGlobalPool below.
///
/// See the comments of ThreadPool below to know how it works.
using ThreadFromGlobalPoolNoTracingContextPropagation = ThreadFromGlobalPoolImpl<false>;
/// An alias of thread that execute jobs/tasks on global thread pool by implicit passing tracing context on current thread to underlying worker as parent tracing context.
/// If jobs/tasks are directly scheduled by using APIs of this class, you need to use this class or you need to use class above.
using ThreadFromGlobalPool = ThreadFromGlobalPoolImpl<true>;
/// Recommended thread pool for the case when multiple thread pools are created and destroyed.
///
/// The template parameter of ThreadFromGlobalPool is set to false to disable tracing context propagation to underlying worker.
/// Because ThreadFromGlobalPool schedules a job upon GlobalThreadPool, this means there will be two workers to schedule a job in 'ThreadPool',
/// one is at GlobalThreadPool level, the other is at ThreadPool level, so tracing context will be initialized on the same thread twice.
///
/// Once the worker on ThreadPool gains the control of execution, it won't return until it's shutdown,
/// which means the tracing context initialized at underlying worker level won't be deleted for a very long time.
/// This would cause wrong context for further jobs scheduled in ThreadPool.
///
/// To make sure the tracing context is correctly propagated, we explicitly disable context propagation(including initialization and de-initialization) at underlying worker level.
///
using ThreadPool = ThreadPoolImpl<ThreadFromGlobalPoolNoTracingContextPropagation>;
#include <Common/ThreadPool.h>
#include <Common/setThreadName.h>
#include <Common/Exception.h>
#include <Common/getNumberOfPhysicalCPUCores.h>
#include <Common/OpenTelemetryTraceContext.h>
#include <Common/noexcept_scope.h>
#include <cassert>
#include <type_traits>
#include <Poco/Util/Application.h>
#include <Poco/Util/LayeredConfiguration.h>
#include <base/demangle.h>
namespace DB
{
namespace ErrorCodes
{
extern const int CANNOT_SCHEDULE_TASK;
extern const int LOGICAL_ERROR;
}
}
namespace CurrentMetrics
{
extern const Metric GlobalThread;
extern const Metric GlobalThreadActive;
extern const Metric GlobalThreadScheduled;
}
static constexpr auto DEFAULT_THREAD_NAME = "ThreadPool";
template <typename Thread>
ThreadPoolImpl<Thread>::ThreadPoolImpl(Metric metric_threads_, Metric metric_active_threads_, Metric metric_scheduled_jobs_)
: ThreadPoolImpl(metric_threads_, metric_active_threads_, metric_scheduled_jobs_, getNumberOfPhysicalCPUCores())
{
}
template <typename Thread>
ThreadPoolImpl<Thread>::ThreadPoolImpl(
Metric metric_threads_,
Metric metric_active_threads_,
Metric metric_scheduled_jobs_,
size_t max_threads_)
: ThreadPoolImpl(metric_threads_, metric_active_threads_, metric_scheduled_jobs_, max_threads_, max_threads_, max_threads_)
{
}
template <typename Thread>
ThreadPoolImpl<Thread>::ThreadPoolImpl(
Metric metric_threads_,
Metric metric_active_threads_,
Metric metric_scheduled_jobs_,
size_t max_threads_,
size_t max_free_threads_,
size_t queue_size_,
bool shutdown_on_exception_)
: metric_threads(metric_threads_)
, metric_active_threads(metric_active_threads_)
, metric_scheduled_jobs(metric_scheduled_jobs_)
, max_threads(max_threads_)
, max_free_threads(std::min(max_free_threads_, max_threads))
, queue_size(queue_size_ ? std::max(queue_size_, max_threads) : 0 /* zero means the queue is unlimited */)
, shutdown_on_exception(shutdown_on_exception_)
{
}
template <typename Thread>
void ThreadPoolImpl<Thread>::setMaxThreads(size_t value)
{
std::lock_guard lock(mutex);
bool need_start_threads = (value > max_threads);
bool need_finish_free_threads = (value < max_free_threads);
max_threads = value;
max_free_threads = std::min(max_free_threads, max_threads);
/// We have to also adjust queue size, because it limits the number of scheduled and already running jobs in total.
queue_size = queue_size ? std::max(queue_size, max_threads) : 0;
jobs.reserve(queue_size);
if (need_start_threads)
{
/// Start new threads while there are more scheduled jobs in the queue and the limit `max_threads` is not reached.
startNewThreadsNoLock();
}
else if (need_finish_free_threads)
{
/// Wake up free threads so they can finish themselves.
new_job_or_shutdown.notify_all();
}
}
template <typename Thread>
size_t ThreadPoolImpl<Thread>::getMaxThreads() const
{
std::lock_guard lock(mutex);
return max_threads;
}
template <typename Thread>
void ThreadPoolImpl<Thread>::setMaxFreeThreads(size_t value)
{
std::lock_guard lock(mutex);
bool need_finish_free_threads = (value < max_free_threads);
max_free_threads = std::min(value, max_threads);
if (need_finish_free_threads)
{
/// Wake up free threads so they can finish themselves.
new_job_or_shutdown.notify_all();
}
}
template <typename Thread>
void ThreadPoolImpl<Thread>::setQueueSize(size_t value)
{
std::lock_guard lock(mutex);
queue_size = value ? std::max(value, max_threads) : 0;
/// Reserve memory to get rid of allocations
jobs.reserve(queue_size);
}
template <typename Thread>
template <typename ReturnType>
ReturnType ThreadPoolImpl<Thread>::scheduleImpl(Job job, Priority priority, std::optional<uint64_t> wait_microseconds, bool propagate_opentelemetry_tracing_context)
{
auto on_error = [&](const std::string & reason)
{
if constexpr (std::is_same_v<ReturnType, void>)
{
if (first_exception)
{
std::exception_ptr exception;
std::swap(exception, first_exception);
std::rethrow_exception(exception);
}
throw DB::Exception(DB::ErrorCodes::CANNOT_SCHEDULE_TASK,
"Cannot schedule a task: {} (threads={}, jobs={})", reason,
threads.size(), scheduled_jobs);
}
else
return false;
};
{
std::unique_lock lock(mutex);
auto pred = [this] { return !queue_size || scheduled_jobs < queue_size || shutdown; };
if (wait_microseconds) /// Check for optional. Condition is true if the optional is set and the value is zero.
{
if (!job_finished.wait_for(lock, std::chrono::microseconds(*wait_microseconds), pred))
return on_error(fmt::format("no free thread (timeout={})", *wait_microseconds));
}
else
job_finished.wait(lock, pred);
if (shutdown)
return on_error("shutdown");
/// We must not to allocate any memory after we emplaced a job in a queue.
/// Because if an exception would be thrown, we won't notify a thread about job occurrence.
/// Check if there are enough threads to process job.
if (threads.size() < std::min(max_threads, scheduled_jobs + 1))
{
try
{
threads.emplace_front();
}
catch (...)
{
/// Most likely this is a std::bad_alloc exception
return on_error("cannot allocate thread slot");
}
try
{
threads.front() = Thread([this, it = threads.begin()] { worker(it); });
}
catch (...)
{
threads.pop_front();
return on_error("cannot allocate thread");
}
}
jobs.emplace(std::move(job),
priority,
metric_scheduled_jobs,
/// Tracing context on this thread is used as parent context for the sub-thread that runs the job
propagate_opentelemetry_tracing_context ? DB::OpenTelemetry::CurrentContext() : DB::OpenTelemetry::TracingContextOnThread(),
/// capture_frame_pointers
DB::Exception::enable_job_stack_trace);
++scheduled_jobs;
}
/// Wake up a free thread to run the new job.
new_job_or_shutdown.notify_one();
return static_cast<ReturnType>(true);
}
template <typename Thread>
void ThreadPoolImpl<Thread>::startNewThreadsNoLock()
{
if (shutdown)
return;
/// Start new threads while there are more scheduled jobs in the queue and the limit `max_threads` is not reached.
while (threads.size() < std::min(scheduled_jobs, max_threads))
{
try
{
threads.emplace_front();
}
catch (...)
{
break; /// failed to start more threads
}
try
{
threads.front() = Thread([this, it = threads.begin()] { worker(it); });
}
catch (...)
{
threads.pop_front();
break; /// failed to start more threads
}
}
}
template <typename Thread>
void ThreadPoolImpl<Thread>::scheduleOrThrowOnError(Job job, Priority priority)
{
scheduleImpl<void>(std::move(job), priority, std::nullopt);
}
template <typename Thread>
bool ThreadPoolImpl<Thread>::trySchedule(Job job, Priority priority, uint64_t wait_microseconds) noexcept
{
return scheduleImpl<bool>(std::move(job), priority, wait_microseconds);
}
template <typename Thread>
void ThreadPoolImpl<Thread>::scheduleOrThrow(Job job, Priority priority, uint64_t wait_microseconds, bool propagate_opentelemetry_tracing_context)
{
scheduleImpl<void>(std::move(job), priority, wait_microseconds, propagate_opentelemetry_tracing_context);
}
template <typename Thread>
void ThreadPoolImpl<Thread>::wait()
{
std::unique_lock lock(mutex);
/// Signal here just in case.
/// If threads are waiting on condition variables, but there are some jobs in the queue
/// then it will prevent us from deadlock.
new_job_or_shutdown.notify_all();
job_finished.wait(lock, [this] { return scheduled_jobs == 0; });
if (first_exception)
{
std::exception_ptr exception;
std::swap(exception, first_exception);
std::rethrow_exception(exception);
}
}
template <typename Thread>
ThreadPoolImpl<Thread>::~ThreadPoolImpl()
{
/// Note: should not use logger from here,
/// because it can be an instance of GlobalThreadPool that is a global variable
/// and the destruction order of global variables is unspecified.
finalize();
onDestroy();
}
template <typename Thread>
void ThreadPoolImpl<Thread>::finalize()
{
{
std::lock_guard lock(mutex);
shutdown = true;
/// We don't want threads to remove themselves from `threads` anymore, otherwise `thread.join()` will go wrong below in this function.
threads_remove_themselves = false;
}
/// Wake up threads so they can finish themselves.
new_job_or_shutdown.notify_all();
/// Wait for all currently running jobs to finish (we don't wait for all scheduled jobs here like the function wait() does).
for (auto & thread : threads)
thread.join();
threads.clear();
}
template <typename Thread>
void ThreadPoolImpl<Thread>::addOnDestroyCallback(OnDestroyCallback && callback)
{
std::lock_guard lock(mutex);
on_destroy_callbacks.push(std::move(callback));
}
template <typename Thread>
void ThreadPoolImpl<Thread>::onDestroy()
{
while (!on_destroy_callbacks.empty())
{
auto callback = std::move(on_destroy_callbacks.top());
on_destroy_callbacks.pop();
NOEXCEPT_SCOPE({ callback(); });
}
}
template <typename Thread>
size_t ThreadPoolImpl<Thread>::active() const
{
std::lock_guard lock(mutex);
return scheduled_jobs;
}
template <typename Thread>
bool ThreadPoolImpl<Thread>::finished() const
{
std::lock_guard lock(mutex);
return shutdown;
}
template <typename Thread>
void ThreadPoolImpl<Thread>::worker(typename std::list<Thread>::iterator thread_it)
{
DENY_ALLOCATIONS_IN_SCOPE;
CurrentMetrics::Increment metric_pool_threads(metric_threads);
bool job_is_done = false;
std::exception_ptr exception_from_job;
/// We'll run jobs in this worker while there are scheduled jobs and until some special event occurs (e.g. shutdown, or decreasing the number of max_threads).
/// And if `max_free_threads > 0` we keep this number of threads even when there are no jobs for them currently.
while (true)
{
/// This is inside the loop to also reset previous thread names set inside the jobs.
setThreadName(DEFAULT_THREAD_NAME);
/// Get a job from the queue.
std::optional<JobWithPriority> job_data;
{
std::unique_lock lock(mutex);
// Finish with previous job if any
if (job_is_done)
{
job_is_done = false;
if (exception_from_job)
{
if (!first_exception)
first_exception = exception_from_job;
if (shutdown_on_exception)
shutdown = true;
exception_from_job = {};
}
--scheduled_jobs;
job_finished.notify_all();
if (shutdown)
new_job_or_shutdown.notify_all(); /// `shutdown` was set, wake up other threads so they can finish themselves.
}
new_job_or_shutdown.wait(lock, [&] { return !jobs.empty() || shutdown || threads.size() > std::min(max_threads, scheduled_jobs + max_free_threads); });
if (jobs.empty() || threads.size() > std::min(max_threads, scheduled_jobs + max_free_threads))
{
// We enter here if:
// - either this thread is not needed anymore due to max_free_threads excess;
// - or shutdown happened AND all jobs are already handled.
if (threads_remove_themselves)
{
thread_it->detach();
threads.erase(thread_it);
}
return;
}
/// boost::priority_queue does not provide interface for getting non-const reference to an element
/// to prevent us from modifying its priority. We have to use const_cast to force move semantics on JobWithPriority.
job_data = std::move(const_cast<JobWithPriority &>(jobs.top()));
jobs.pop();
/// We don't run jobs after `shutdown` is set, but we have to properly dequeue all jobs and finish them.
if (shutdown)
{
job_is_done = true;
continue;
}
}
ALLOW_ALLOCATIONS_IN_SCOPE;
/// Set up tracing context for this thread by its parent context.
DB::OpenTelemetry::TracingContextHolder thread_trace_context("ThreadPool::worker()", job_data->thread_trace_context);
/// Run the job.
try
{
if (DB::Exception::enable_job_stack_trace)
DB::Exception::thread_frame_pointers = std::move(job_data->frame_pointers);
CurrentMetrics::Increment metric_active_pool_threads(metric_active_threads);
job_data->job();
if (thread_trace_context.root_span.isTraceEnabled())
{
/// Use the thread name as operation name so that the tracing log will be more clear.
/// The thread name is usually set in jobs, we can only get the name after the job finishes
std::string thread_name = getThreadName();
if (!thread_name.empty() && thread_name != DEFAULT_THREAD_NAME)
{
thread_trace_context.root_span.operation_name = thread_name;
}
else
{
/// If the thread name is not set, use the type name of the job instead
thread_trace_context.root_span.operation_name = demangle(job_data->job.target_type().name());
}
}
/// job should be reset before decrementing scheduled_jobs to
/// ensure that the Job destroyed before wait() returns.
job_data.reset();
}
catch (...)
{
exception_from_job = std::current_exception();
thread_trace_context.root_span.addAttribute(exception_from_job);
/// job should be reset before decrementing scheduled_jobs to
/// ensure that the Job destroyed before wait() returns.
job_data.reset();
}
job_is_done = true;
}
}
template class ThreadPoolImpl<std::thread>;
template class ThreadPoolImpl<ThreadFromGlobalPoolImpl<false>>;
template class ThreadFromGlobalPoolImpl<true>;
std::unique_ptr<GlobalThreadPool> GlobalThreadPool::the_instance;
GlobalThreadPool::GlobalThreadPool(
size_t max_threads_,
size_t max_free_threads_,
size_t queue_size_,
const bool shutdown_on_exception_)
: FreeThreadPool(
CurrentMetrics::GlobalThread,
CurrentMetrics::GlobalThreadActive,
CurrentMetrics::GlobalThreadScheduled,
max_threads_,
max_free_threads_,
queue_size_,
shutdown_on_exception_)
{
}
void GlobalThreadPool::initialize(size_t max_threads, size_t max_free_threads, size_t queue_size)
{
if (the_instance)
{
throw DB::Exception(DB::ErrorCodes::LOGICAL_ERROR,
"The global thread pool is initialized twice");
}
the_instance.reset(new GlobalThreadPool(max_threads, max_free_threads, queue_size, false /*shutdown_on_exception*/));
}
GlobalThreadPool & GlobalThreadPool::instance()
{
if (!the_instance)
{
// Allow implicit initialization. This is needed for old code that is
// impractical to redo now, especially Arcadia users and unit tests.
initialize();
}
return *the_instance;
}
ThreadPoolImpl::scheduleImpl
这里如果线程数不足的话会启动一个线程。
为了防止std::bad_alloc,会先在list前面分配一个空位置,然后再插入job。
template <typename Thread>
template <typename ReturnType>
ReturnType ThreadPoolImpl<Thread>::scheduleImpl(Job job, Priority priority, std::optional<uint64_t> wait_microseconds, bool propagate_opentelemetry_tracing_context)
{
auto on_error = [&](const std::string & reason)
{
if constexpr (std::is_same_v<ReturnType, void>)
{
if (first_exception)
{
std::exception_ptr exception;
std::swap(exception, first_exception);
std::rethrow_exception(exception);
}
throw DB::Exception(DB::ErrorCodes::CANNOT_SCHEDULE_TASK,
"Cannot schedule a task: {} (threads={}, jobs={})", reason,
threads.size(), scheduled_jobs);
}
else
return false;
};
{
std::unique_lock lock(mutex);
auto pred = [this] { return !queue_size || scheduled_jobs < queue_size || shutdown; };
if (wait_microseconds) /// Check for optional. Condition is true if the optional is set and the value is zero.
{
if (!job_finished.wait_for(lock, std::chrono::microseconds(*wait_microseconds), pred))
return on_error(fmt::format("no free thread (timeout={})", *wait_microseconds));
}
else
job_finished.wait(lock, pred);
if (shutdown)
return on_error("shutdown");
/// We must not to allocate any memory after we emplaced a job in a queue.
/// Because if an exception would be thrown, we won't notify a thread about job occurrence.
/// Check if there are enough threads to process job.
if (threads.size() < std::min(max_threads, scheduled_jobs + 1))
{
try
{
threads.emplace_front();
}
catch (...)
{
/// Most likely this is a std::bad_alloc exception
return on_error("cannot allocate thread slot");
}
try
{
threads.front() = Thread([this, it = threads.begin()] { worker(it); });
}
catch (...)
{
threads.pop_front();
return on_error("cannot allocate thread");
}
}
jobs.emplace(std::move(job),
priority,
metric_scheduled_jobs,
/// Tracing context on this thread is used as parent context for the sub-thread that runs the job
propagate_opentelemetry_tracing_context ? DB::OpenTelemetry::CurrentContext() : DB::OpenTelemetry::TracingContextOnThread(),
/// capture_frame_pointers
DB::Exception::enable_job_stack_trace);
++scheduled_jobs;
}
/// Wake up a free thread to run the new job.
new_job_or_shutdown.notify_one();
return static_cast<ReturnType>(true);
}
ThreadPoolImpl::worker
这里就是一个中规中矩的事件循环实现,非常适合拿来借鉴(抄)。
值得注意的是,缩容的时候这里要detach一下。
template <typename Thread>
void ThreadPoolImpl<Thread>::worker(typename std::list<Thread>::iterator thread_it)
{
DENY_ALLOCATIONS_IN_SCOPE;
CurrentMetrics::Increment metric_pool_threads(metric_threads);
bool job_is_done = false;
std::exception_ptr exception_from_job;
/// We'll run jobs in this worker while there are scheduled jobs and until some special event occurs (e.g. shutdown, or decreasing the number of max_threads).
/// And if `max_free_threads > 0` we keep this number of threads even when there are no jobs for them currently.
while (true)
{
/// This is inside the loop to also reset previous thread names set inside the jobs.
setThreadName(DEFAULT_THREAD_NAME);
/// Get a job from the queue.
std::optional<JobWithPriority> job_data;
{
std::unique_lock lock(mutex);
// Finish with previous job if any
if (job_is_done)
{
job_is_done = false;
if (exception_from_job)
{
if (!first_exception)
first_exception = exception_from_job;
if (shutdown_on_exception)
shutdown = true;
exception_from_job = {};
}
--scheduled_jobs;
job_finished.notify_all();
if (shutdown)
new_job_or_shutdown.notify_all(); /// `shutdown` was set, wake up other threads so they can finish themselves.
}
new_job_or_shutdown.wait(lock, [&] { return !jobs.empty() || shutdown || threads.size() > std::min(max_threads, scheduled_jobs + max_free_threads); });
if (jobs.empty() || threads.size() > std::min(max_threads, scheduled_jobs + max_free_threads))
{
// We enter here if:
// - either this thread is not needed anymore due to max_free_threads excess;
// - or shutdown happened AND all jobs are already handled.
if (threads_remove_themselves)
{
thread_it->detach();
threads.erase(thread_it);
}
return;
}
/// boost::priority_queue does not provide interface for getting non-const reference to an element
/// to prevent us from modifying its priority. We have to use const_cast to force move semantics on JobWithPriority.
job_data = std::move(const_cast<JobWithPriority &>(jobs.top()));
jobs.pop();
/// We don't run jobs after `shutdown` is set, but we have to properly dequeue all jobs and finish them.
if (shutdown)
{
job_is_done = true;
continue;
}
}
ALLOW_ALLOCATIONS_IN_SCOPE;
/// Set up tracing context for this thread by its parent context.
DB::OpenTelemetry::TracingContextHolder thread_trace_context("ThreadPool::worker()", job_data->thread_trace_context);
/// Run the job.
try
{
if (DB::Exception::enable_job_stack_trace)
DB::Exception::thread_frame_pointers = std::move(job_data->frame_pointers);
CurrentMetrics::Increment metric_active_pool_threads(metric_active_threads);
job_data->job();
if (thread_trace_context.root_span.isTraceEnabled())
{
/// Use the thread name as operation name so that the tracing log will be more clear.
/// The thread name is usually set in jobs, we can only get the name after the job finishes
std::string thread_name = getThreadName();
if (!thread_name.empty() && thread_name != DEFAULT_THREAD_NAME)
{
thread_trace_context.root_span.operation_name = thread_name;
}
else
{
/// If the thread name is not set, use the type name of the job instead
thread_trace_context.root_span.operation_name = demangle(job_data->job.target_type().name());
}
}
/// job should be reset before decrementing scheduled_jobs to
/// ensure that the Job destroyed before wait() returns.
job_data.reset();
}
catch (...)
{
exception_from_job = std::current_exception();
thread_trace_context.root_span.addAttribute(exception_from_job);
/// job should be reset before decrementing scheduled_jobs to
/// ensure that the Job destroyed before wait() returns.
job_data.reset();
}
job_is_done = true;
}
}















 5422
5422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









