










训练自己的数据集,首先需要安装Yolov5及创建数据集,这些部分在之前的文章中已经提到。
Yolov5安装及简单使用: Yolov5安装及简单使用
数据集标注: 数据集标注方法
1.创建数据集文件夹
coco数据集官网地址:https://cocodataset.org/
此处使用的是coco数据集来完成,选择Dataset

选择Download
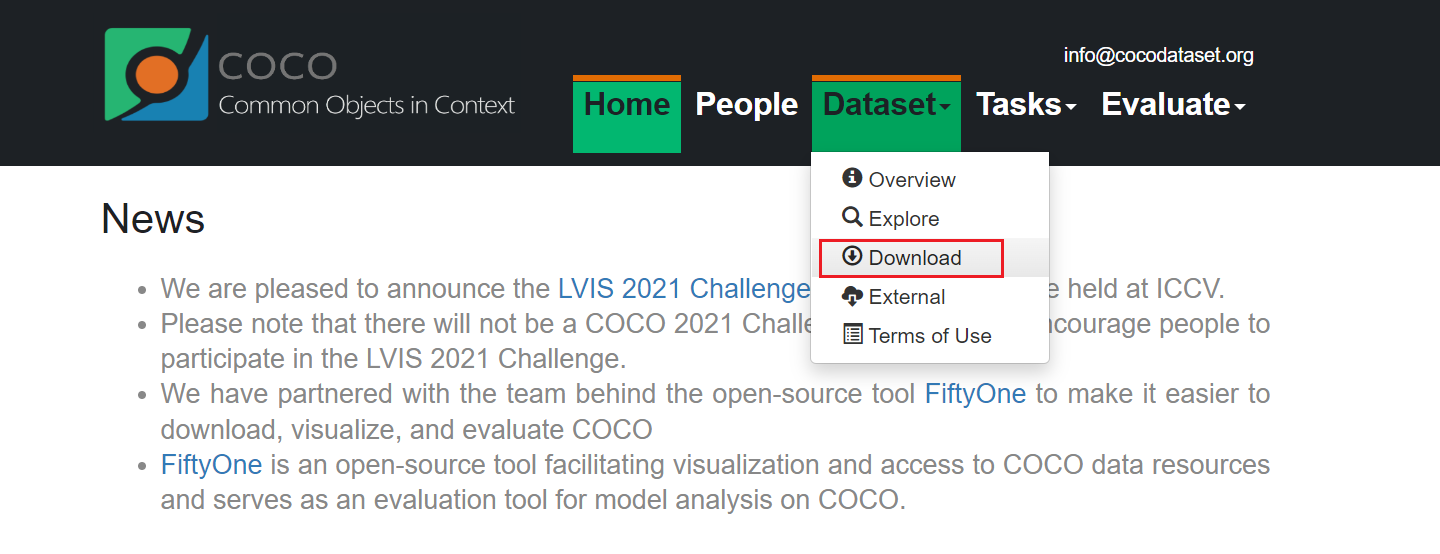
一般情况下,下载2017年的训练、测试、验证集加上2017年Annotations即可
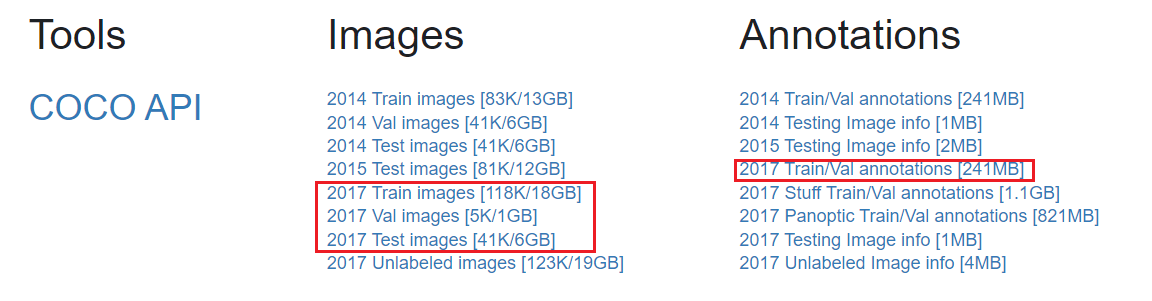
但由于硬件设备限制,在这里便使用验证集来进行训练
下载完成后,需要进行一定的处理来使其能够符合yolov5训练要求的格式,在此处使用一种开源工具来完成。
官网地址:https://github.com/ssaru/convert2Yolo
具体操作按官方文档操作即可。
注意: coco.names文件中只填入所需要的类别即可,之后会对对于无意义图片进行过滤删除,使模型更轻量化。
2.过滤
训练模型时,由于coco数据集存在很多实际项目并不需要的类别的数据,所以需要进行过滤。由于在之前数据格式转换时,已经通过coco.names指定了类别,故而生成的labels文档中存在许多无类别的项,此时需要将其这些无意义的内容删除,若图片要素全部无意义,则删除图片。
import os
url = './data/yolo/dataset/labels'
dirs = os.listdir(url)
pic_zero = []
# 删除labels文件中无意义的内容,并记录下内容全部无意义的文件
for file in dirs:
whole_url = url + '/' + file
f = open(whole_url, 'r+')
flag = 0
contents = []
while True:
content = f.readline()
if content != '':
if content[:4] != 'None':
flag += 1
contents.append(content)
continue
break
name = f.name[-16:-4]
f.close()
f1 = open(whole_url, 'w+')
f1.writelines(contents)
f1.close()
if flag == 0:
pic_zero.append(name)
os.remove(whole_url)
flag = 0
# 删除无意义的图片
for pic in pic_zero:
url_pic = './data/yolo/dataset/images/' + pic + '.jpg'
os.remove(url_pic)
3.训练前置准备
3.1 创建数据集目录
创建数据集目录,使其符合类似于以下的目录结构:
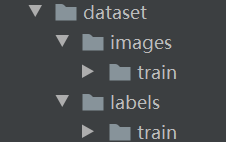
train文件夹中就是想要的图片和标签数据了。
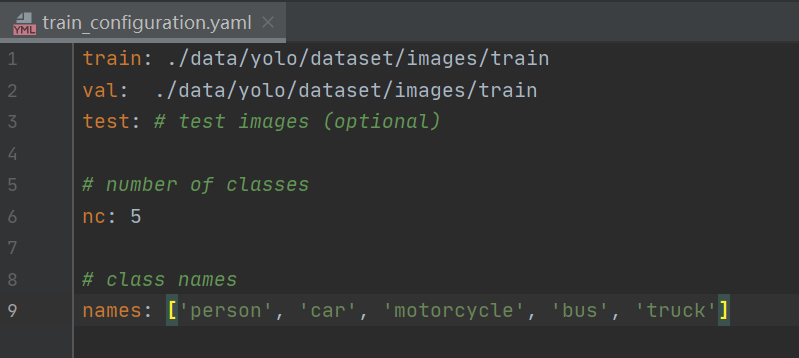
3.2 创建并写入配置文件
类似于以下文件内容即可:
3.3 修改训练参数
找到train.py文件,找到main函数,修改其中参数
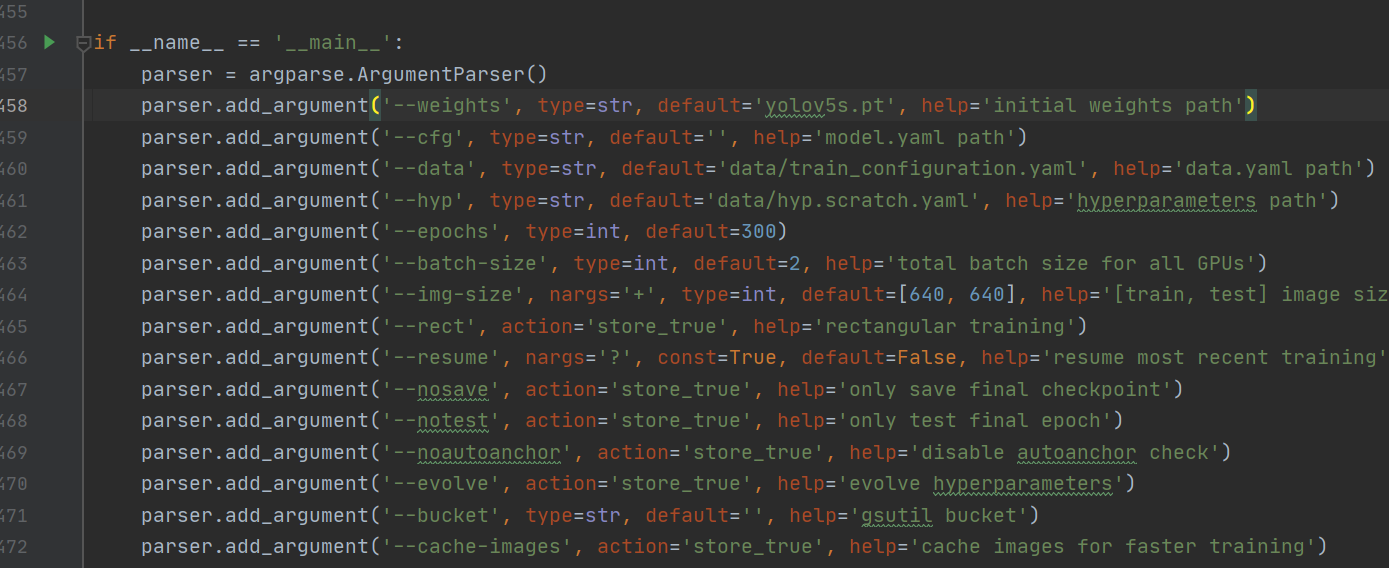
选择预训练模型,在此处选择yolov5s.pt

选择配置文件,就是之前所创建的配置文件的路径

选择训练轮数,这个参数设置参考设备情况以及数据集大小情况

设置device,选择cpu或第几个gpu,此处选择第0gpu

设置结果保存路径,此处不作改变

设置结果目录名,此处不作改变

之后直接运用train.py文件即可
3.4 部分训练结果解释
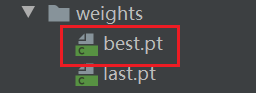
weights:训练所得的模型,有best.pt和last.pt,一般选择best.pt
confusion_matrix.png:混淆矩阵
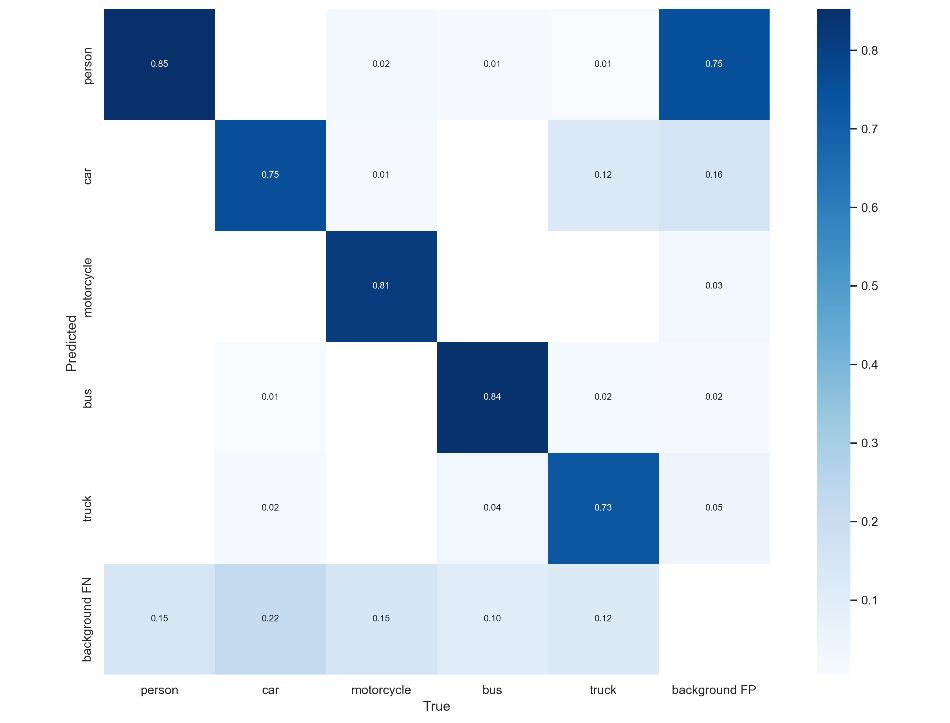
以上图为例,计算bus类别精确率与召回率如下所示:
精确率:0.84/(0.84+0.01+0.02+0.02)=0.94
召回率:0.84/(0.84+0.04+0.10+0.01)=0.85
results.png:
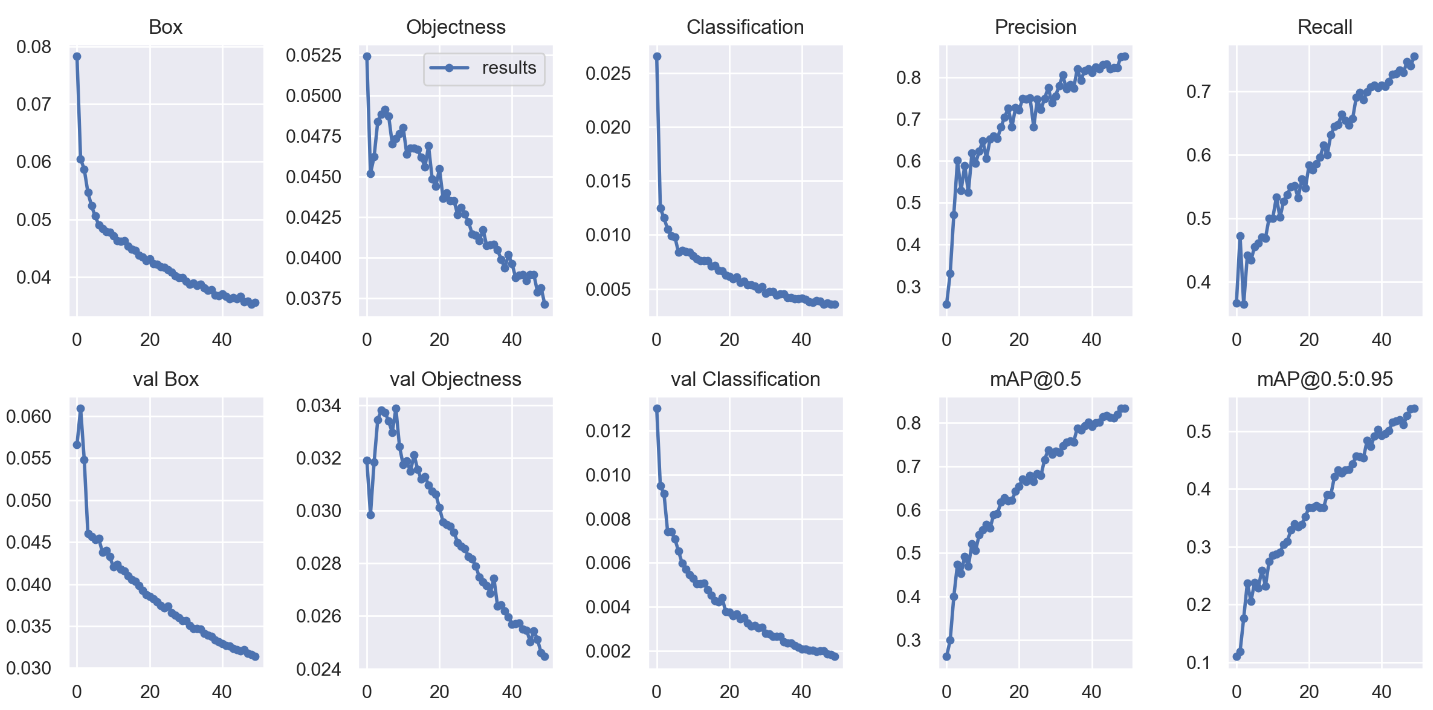
第一个图表示的是训练轮数与损失函数均值之间的关系,box表示GIOU损失函数均值,一般值越小,预测框越准;第二个图则表示目标检测loss均值,越小目标检测越准;第三个图是分类loss均值,越小分类越准;val表示验证集的情况;mAP是用Precision和Recall作为两轴作图后围成的面积,@后面的数表示判定iou为正负样本的阈值,@0.5:0.95表示阈值取0.5:0.05:0.95后取均值。
其余结果大部分较易理解,便不再解释。
由结果可以得出,模型训练效果较为优秀。
















 9205
9205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











