







背景:python中有一个sklearn模块,全称scikit-learn。是一个集成了许多机器学习算法的第三方模块,包括回归(Regression)、分类(Classfication)、聚类(Clustering)、降维(Dimensionality Reduction)等方法。
算法选择流程图:
不同的评估器适合于不同类型的数据和不同的问题。以下是skl官方给出的粗略指引:
原图链接:https://scikit-learn.org/stable/tutorial/machine_learning_map/
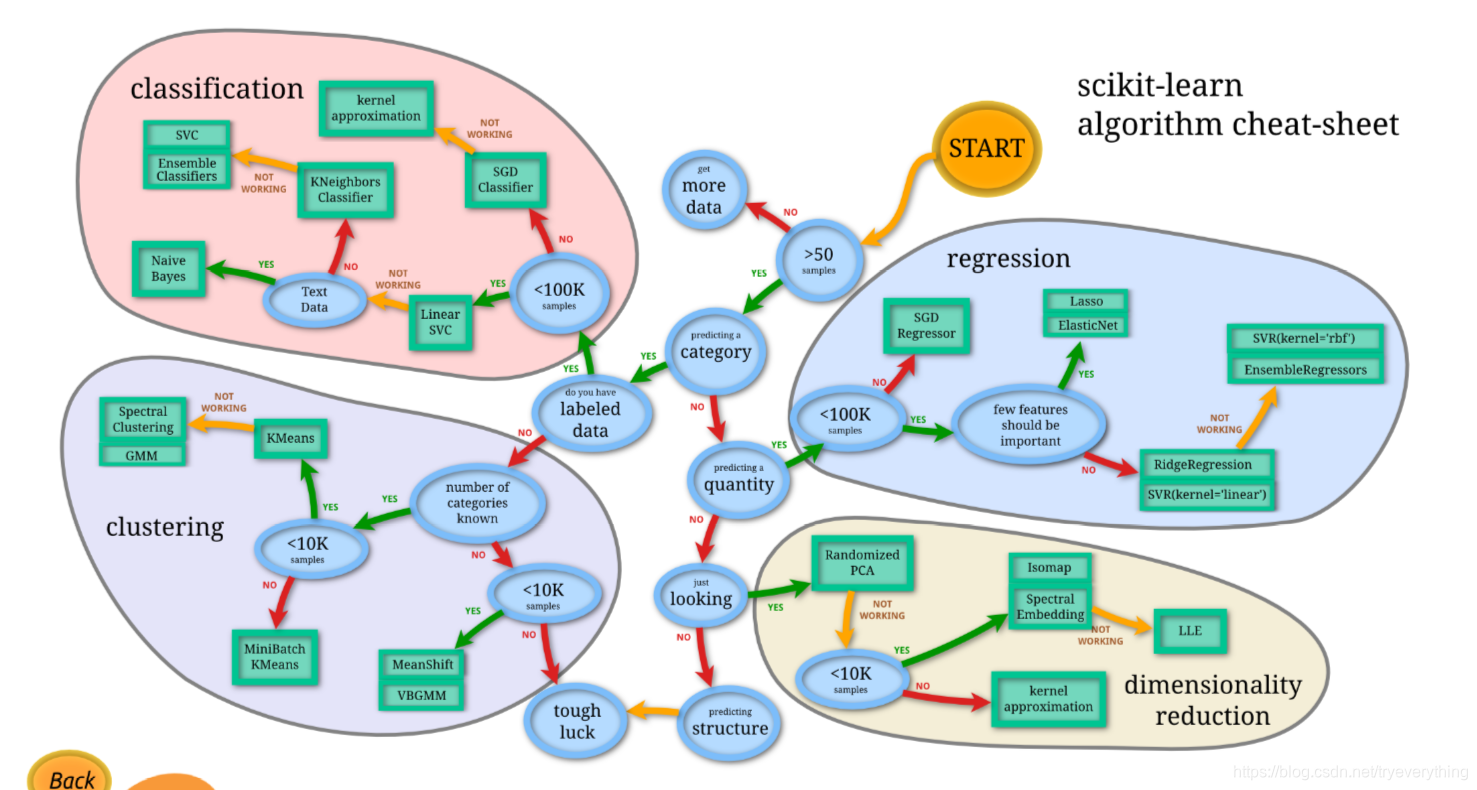
单击原图表中的任何评估器可以查看其文档。
skl通用学习模式:

















 5545
5545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









