







 该专栏为热销专栏榜 第61名
该专栏为热销专栏榜 第61名1.CBAM介绍

摘要:我们提出了卷积块注意力模块(CBAM),这是一种用于前馈卷积神经网络的简单而有效的注意力模块。 给定中间特征图,我们的模块沿着两个独立的维度(通道和空间)顺序推断注意力图,然后将注意力图乘以输入特征图以进行自适应特征细化。 由于 CBAM 是一个轻量级通用模块,因此它可以无缝集成到任何 CNN 架构中,且开销可以忽略不计,并且可以与基础 CNN 一起进行端到端训练。 我们通过在 ImageNet-1K、MS COCO 检测和 VOC 2007 检测数据集上进行大量实验来验证我们的 CBAM。 我们的实验表明各种模型的分类和检测性能得到了一致的改进,证明了 CBAM 的广泛适用性。 代码和模型将公开。
官方论文地址:CBAM论文
官方代码地址:CBAM代码
简单介绍:CBAM的主要思想是通过关注重要的特征并抑制不必要的特征来增强网络的表示能力。模块首先应用通道注意力,关注"重要的"特征,然后应用空间注意力,关注这些特征的"重要位置"。通过这种方式,CBAM有效地帮助网络聚焦于图像中的关键信息,提高了特征的表示力度,下图为其原理结构图。

2.核心代码
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
"""Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet."""
def __init__(self, channels: int) -> None:
"""Initializes the class and sets the basic configurations and instance variables required."""
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
self.act = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Applies forward pass using activation on convolutions of the input, optionally using batch normalization."""
return x * self.act(self.fc(self.pool(x)))
class SpatialAttention(nn.Module):
"""Spatial-attention module."""
def __init__(self, kernel_size=7):
"""Initialize Spatial-attention module with kernel size argument."""
super().__init__()
assert kernel_size in (3, 7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):
"""Apply channel and spatial attention on input for feature recalibration."""
return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
class CBAM(nn.Module):
"""Convolutional Block Attention Module."""
def __init__(self, c1, kernel_size=7):
"""Initialize CBAM with given input channel (c1) and kernel size."""
super().__init__()
self.channel_attention = ChannelAttention(c1)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
"""Applies the forward pass through C1 module."""
return self.spatial_attention(self.channel_attention(x))3.YOLOv11中添加CBAM方式
3.1 在ultralytics/nn下新建Extramodule
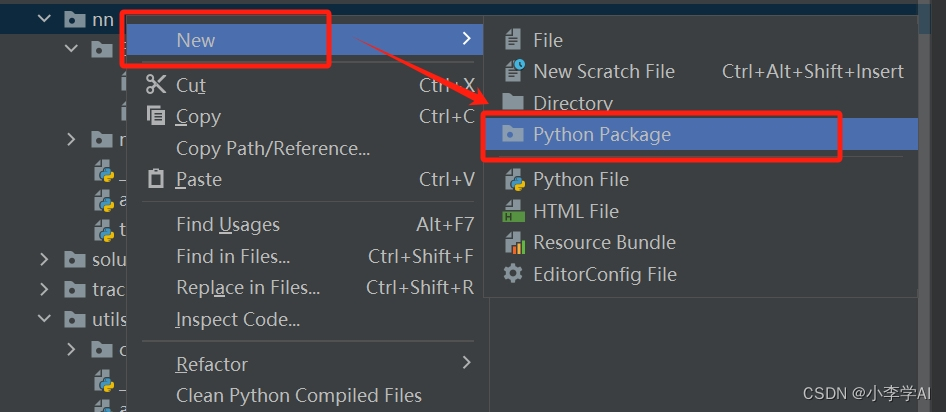

3.2 在Extramodule里创建CBAM


在CBAM.py文件里添加给出的CBAM代码
添加完CBAM代码后,在ultralytics/nn/Extramodule/__init__.py文件中引用

3.3 在tasks.py里引用
在ultralytics/nn/tasks.py文件里引用Extramodule

在tasks.py找到parse_model(ctrl+f可以直接搜索parse_model位置)
添加如下代码:

elif m in {CBAM}:
c2 = ch[f]
args = [c2, *args]4.新建一个yolo11CBAM.yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, CBAM, []]
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, CBAM, []]
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [-1, 1, CBAM, []]
- [[16, 20, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
大家根据自己的数据集实际情况,修改nc大小。
5.模型训练

import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO(r'D:\yolo\yolov11\ultralytics-main\datasets\yolo11CBAM.yaml')
model.train(data=r'D:\yolo\yolov11\ultralytics-main\datasets\data.yaml',
cache=False,
imgsz=640,
epochs=100,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
device='0',
optimizer='SGD',
amp=True,
project='runs/train',
name='exp',
)模型结构打印,成功运行 :

6.本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv11改进有效涨点专栏,本专栏目前为新开的,后期我会根据各种前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~


















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









