







目录
1.数据集背景
乳腺癌数据集是一个非常经典的二元分类数据集,被广泛应用于机器学习和数据挖掘领域。该数据集包含了106个样本和30个特征,每个样本都有一个标签,表示该样本是否为癌症。标签值为0表示非癌症,标签值为1表示癌症。
这个数据集的特征包括了病人的年龄、肿瘤的大小、肿瘤的形状、肿瘤的位置、病人的淋巴结状态等信息。其中,一些特征是连续的数值型数据,例如病人的年龄和肿瘤的大小;而另一些特征则是二元或三元的分类数据,例如肿瘤的形状和位置。
乳腺癌数据集是一个非常实用的数据集,它可以帮助我们评估和比较机器学习算法的性能和准确性。由于该数据集相对较小,但是具有很多实用的特征,因此它可以很好地测试算法在处理多维数据时的效果和表现。同时,这个数据集也经常被用来作为示例数据集,用于介绍各种机器学习算法和技术的使用和实现方法。
在使用乳腺癌数据集时,需要注意以下几点。首先,由于该数据集是一个相对较小的数据集,因此在进行模型训练时,需要使用交叉验证等技术来评估模型的性能。其次,由于该数据集的特征包括了连续型和分类型两种类型的数据,因此在特征预处理时需要注意数据的规范化和编码方式。最后,由于该数据集的标签是二元分类问题,因此需要选择适合的评估指标来评估模型的性能,例如准确率、精确率、召回率等。
总之,乳腺癌数据集是一个非常实用的数据集,它可以帮助我们评估和比较机器学习算法的性能和准确性。在使用该数据集时,需要注意数据的预处理和特征选择等问题,以便得到更加准确和可靠的模型结果。
训练与测试的数据集大小为下图:

测试数据为:
2 集成学习方法
AdaBoost集成过程
AdaBoost算法是一种集成学习方法,其核心思想是通过组合多个弱分类器来构建一个性能更强的强分类器。它基于一个关键的观点:即使每个弱分类器的性能很差,但通过组合它们可以得到一个具有较高准确性的强分类器。
AdaBoost算法是一种非常著名的集成学习方法,它通过将多个弱分类器组合在一起,形成强分类器,从而提高分类性能。该算法的基本原理是将多个弱分类器组合在一起,使得整个集合的分类性能更好。
在AdaBoost算法中,每个新的弱分类器都会对之前分类错误的样本给予更大的权重,以便于该分类器能够更好地学习这些样本。具体来说,AdaBoost算法通过以下步骤来实现:
- 初始化样本权重分布
- 对于每个样本,赋予相同的权重,即Wi=1/N(N为样本总数)
- 训练弱分类器
- 根据样本的权重分布训练一个弱分类器,分类器预测正确的样本权重将减小,错误则增加,用EL(j)表示第j个弱分类器在训练集上的错误率,则:
EL(j)=∑Di*Ii/Zj
(Zj为规范化因子,D为样本权重分布,Ii为样本i是否被正确分类)
- 根据样本的权重分布训练一个弱分类器,分类器预测正确的样本权重将减小,错误则增加,用EL(j)表示第j个弱分类器在训练集上的错误率,则:
- 计算分类器权重
- 计算第j个弱分类器的权重W(j):W(j)=[(1-EL(j))]/∑(1-EL(i))
- 组合弱分类器
- 将每个弱分类器的输出乘以它的权重,然后求和得到最终的预测结果。
- 更新样本权重分布
- 对于每个样本,如果被正确分类,则降低其权重;如果错误分类,则增加其权重。
- 返回步骤2,直到弱分类器的数量达到预设值或无法进一步降低错误率为止。
AdaBoost算法具有自适应能力,能够根据样本的错误率自动调整弱分类器的权重和组合权重。同时,AdaBoost算法还具有很强的鲁棒性,即使某个弱分类器出现较大的错误率,也不会对整个集合的分类性能产生太大的影响。因此,AdaBoost算法在很多领域都得到了广泛的应用。
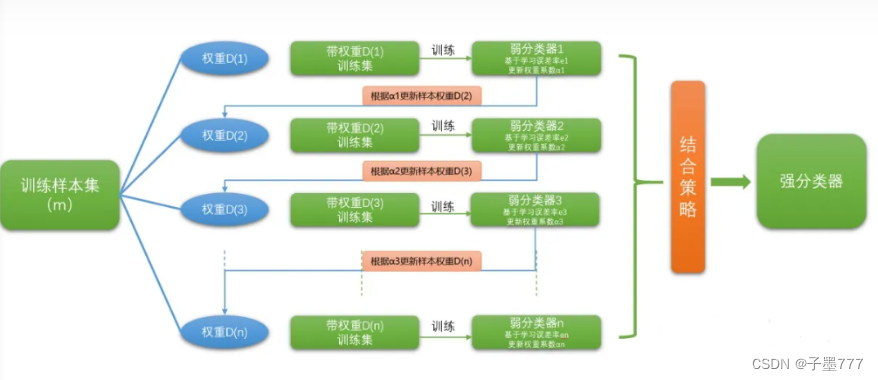
图1 AdaBoost集成过程
3 个体学习器
个体学习器是指基于单个模型进行学习的算法,如决策树、支持向量机、逻辑回归等。在机器学习中,个体学习器通常作为构建强分类器的起点,通过将多个个体学习器组合在一起,形成集体学习器,从而提高分类性能。
在本次大作业中,我们采用单层决策树作为个体学习器构建弱分类器。决策树是一种常见的机器学习算法,它通过将数据集划分成若干个分支,从而实现对数据的分类。在决策树中,每个节点代表一个特征或属性,每个分支代表一个决策规则,最终的分类结果由树的根节点到叶节点的路径决定。在构建决策树时,通常采用贪婪搜索算法进行特征选择和决策树的剪枝,以避免过拟合和欠拟合问题。这种方法在实际应用中被广泛使用,特别是在处理大规模数据和复杂特征的场景下,展现出了良好的效果和可扩展性。
结果评价
选择ROC曲线作为评价AdaBoost分类效果的指标,具体结果如下所示:
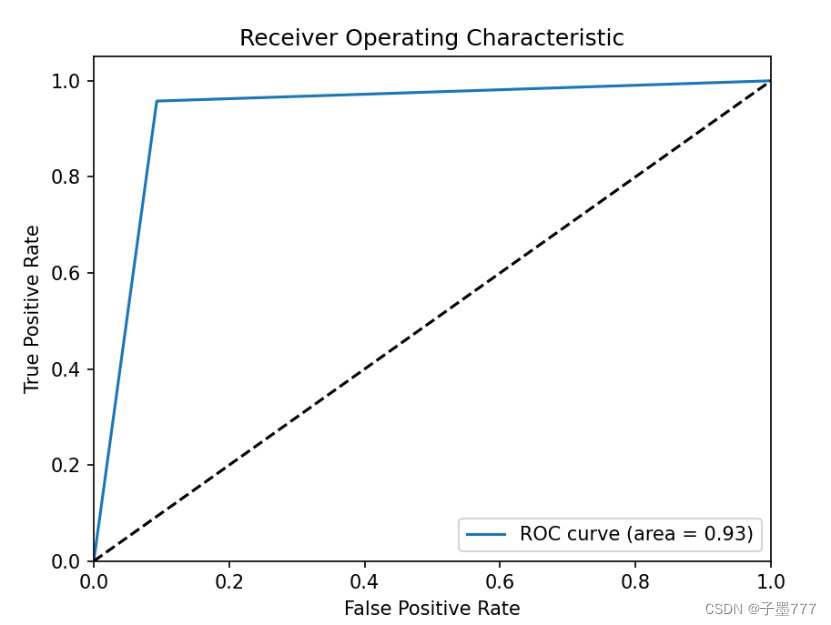
图2 ROC评价效果
ROC是反映敏感性和特异性连续变量的综合指标。以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。在ROC曲线上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。这也证明了AdaBoost分类效果较好。
准确率以及混淆矩阵
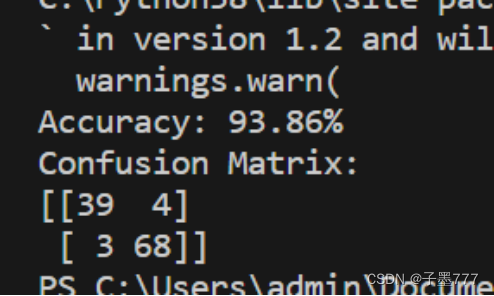
评估集成学习模型的泛化学习能力
评估集成学习模型的泛化学习能力是十分重要的,因为泛化能力决定了模型在未知数据上的表现。为了评估集成学习模型的泛化能力,我们可以采用以下方法:
验证集评估:将数据集划分为训练集、验证集和测试集,其中验证集用于调整模型参数和选择最佳的弱分类器组合,测试集用于评估模型的泛化能力。
交叉验证:通过将数据集划分为多个子集,依次将每个子集作为测试集,其余子集作为训练集进行训练和测试,最后取多个测试结果的平均值作为最终评估结果。
误差分析:分析模型的误差分布,检查误差的主要来源,从而评估模型在未知数据上的泛化能力。
鲁棒性分析:分析模型对噪声数据和异常值的鲁棒性,从而评估模型在未知数据上的泛化能力。
评估集成学习模型的多样性
评估集成学习模型的多样性是非常重要的,因为模型的多样性可以增强其对数据的适应能力,从而降低过拟合的风险。为了评估集成学习模型的多样性,我们可以采用以下方法:
1. 观察弱分类器的结构:检查每个弱分类器的结构是否相似,如果相似度很高,则说明模型缺乏多样性。
2. 计算弱分类器的输出:观察弱分类器的输出是否相似,如果相似度很高,则说明模型缺乏多样性。
3. 采用多样性度量:可以计算不同弱分类器之间的相似度或差异度,从而评估模型的多样性。
4. 观察模型的预测结果:对于测试集中的每个样本,观察模型的所有弱分类器的预测结果,如果预测结果相似,则说明模型缺乏多样性。
结论
所设计的集成学习模型具有以下优点:
提高了分类性能:通过将多个弱分类器组合在一起,形成强分类器,可以显著提高分类性能。
增强了鲁棒性:集成学习模型可以降低对单个分类器的要求,即使某个分类器出现较大的错误率,也不会对整个模型的分类性能产生太大的影响。
实现了自适应学习:AdaBoost算法能够根据样本的错误率自动调整弱分类器的权重和组合权重,实现了自适应学习。
然而,该模型也存在以下缺点:
易于过拟合:由于AdaBoost算法将每个弱分类器进行加权组合,容易导致过拟合问题。
对噪声数据敏感:如果数据集中存在噪声数据,AdaBoost算法可能会将这些噪声数据赋予较大的权重,从而影响整个模型的分类性能。
为了解决这些缺点,可以采取以下思路和解决方案:
降低模型复杂度:通过减少弱分类器的数量或降低每个弱分类器的复杂度,可以降低整个模型的复杂度,从而减少过拟合问题的发生。
加入正则化项:在训练过程中加入正则化项,可以限制模型的复杂度,从而减少过拟合问题的发生。
处理噪声数据:可以通过一些方法对噪声数据进行预处理,例如去除噪声数据或对其进行归一化处理,以减少其对整个模型分类性能的影响。
源码
#
导入需要的库
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import roc_curve, accuracy_score, confusion_matrix ,auc
import matplotlib.pyplot as plt
# 加载数据集
data = load_breast_cancer()
X = data.data
y = data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用决策树构建个体学习器
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
# 使用AdaBoost利用决策树构建集体学习器
ada = AdaBoostClassifier(base_estimator=clf, n_estimators=100, random_state=42)
ada.fit(X_train, y_train)
print("X_train shape is: ",X_train.shape)
print("X_test shape is: ",X_test.shape)
print("X_test is: ",X_test)
# 预测测试集结果
y_pred = ada.predict(X_test)
# 计算ROC曲线
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
roc_auc = auc(fpr, tpr)
# 输出ROC曲线图
plt.figure()
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy: {:.2f}%'.format(accuracy * 100))
# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(cm)














 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









