






[ GPT-SoVITS 镜像教程 ]
—— 欢迎使用星海智算 ——
“给我三分钟 偷走你的声音”
GPT-SoVITS✦
模型介绍
GPT-SoVITS是由RVC创始人RVC-Boss与AI声音转换技术专家Rcell共同开发的一款跨语言TTS克隆项目。它是一款强大的音色克隆模型,支持少量语音转换,支持中文、英文和日文的语音推理。基于深度学习技术,GPT-SoVITS能够生成与目标人物声音非常相似的音频,只需提供一分钟的语音即可进行有效的识别和训练,生成高度相似的语音模型。该软件适用于各种应用场景,如虚拟代言人、语音助手和有声读物等,用户可以轻松生成高质量的语音音频,以满足不同需求。
PART.01:启动应用
首先,进入星海智算平台,点击【GPU实例】,即可创建实例。
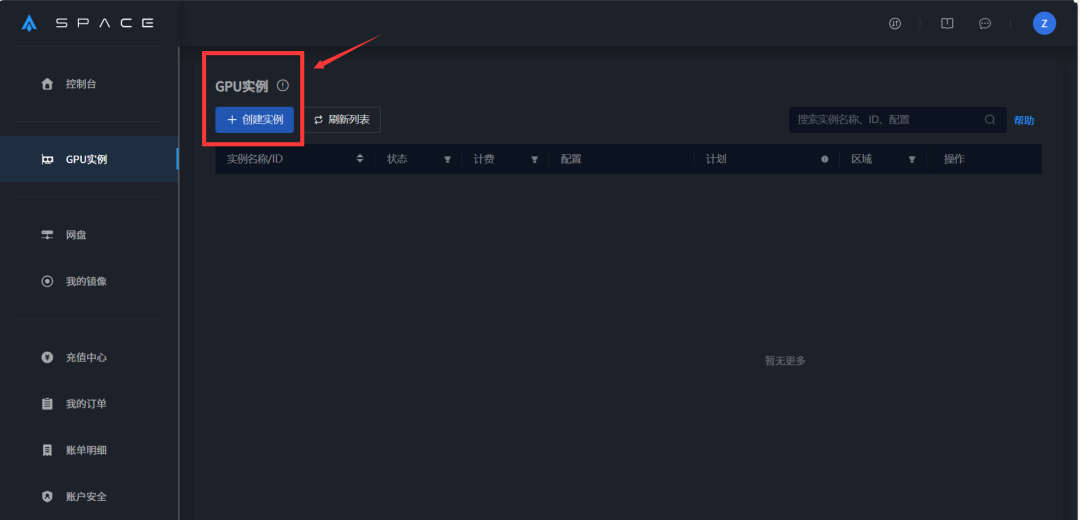
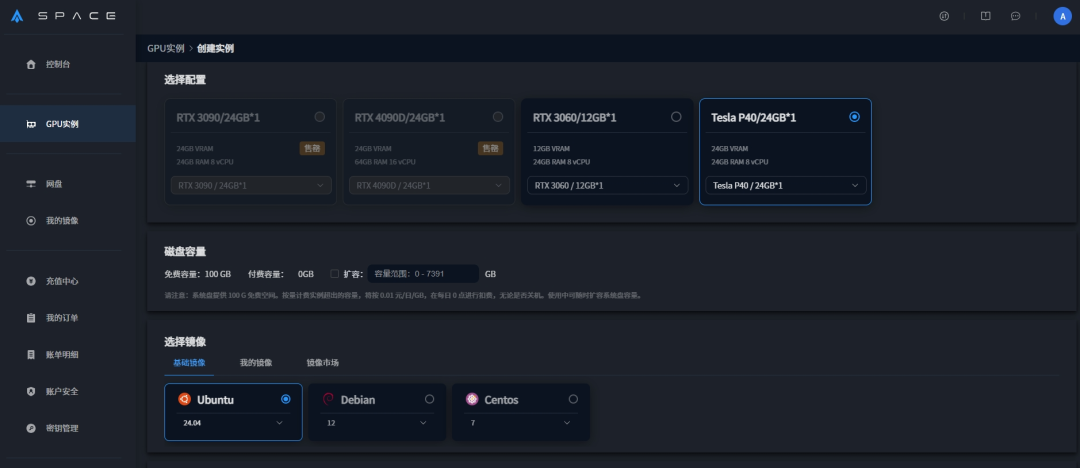
在【选择配置】中,可选择不同区域的显卡。
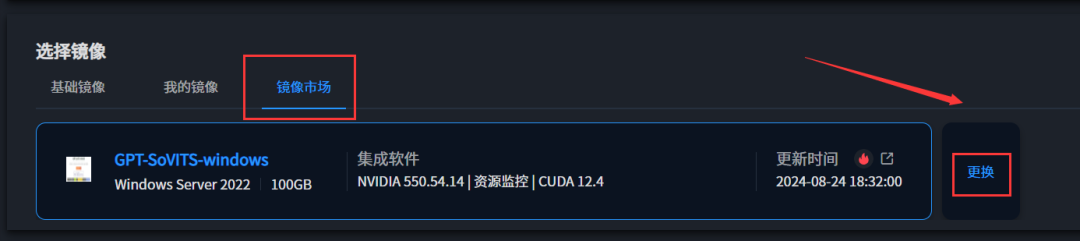
在【镜像市场】点击更换镜像,选择GPT-SoVITS镜像,确认后在实例创建页面点击<立即创建>即可。
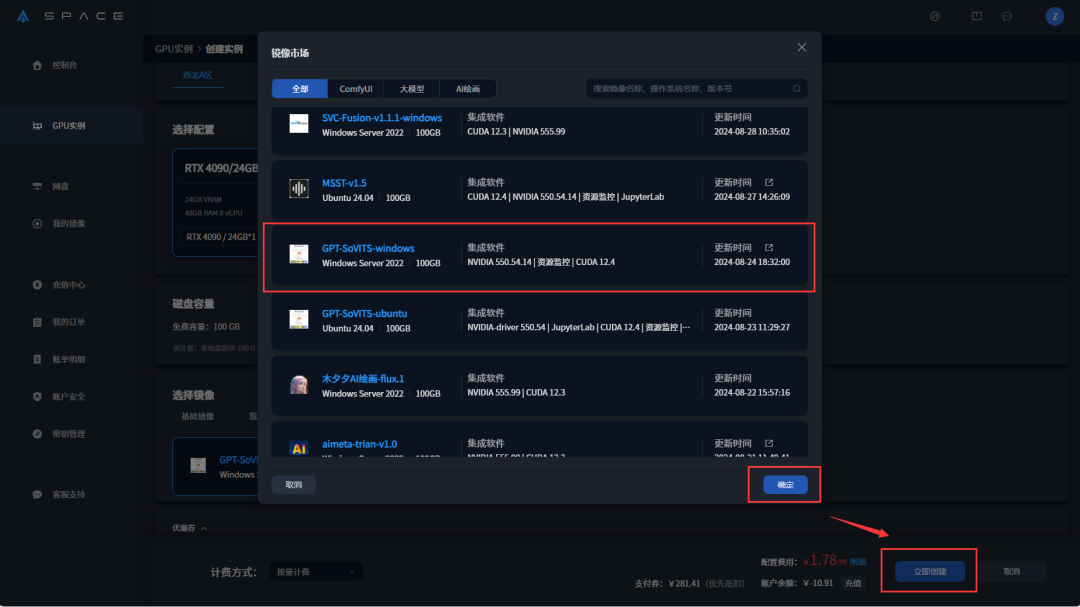
创建成功等待4-5分钟,看到状态栏跳转<运行中>且登录信息显现即可进行下一步操作。

接着进行远程连接,输入Win+R ,出现运行界面后输入 mstsc,点击确认。

点击确认后会出现远程桌面连接,复制星海实例界面登录信息。
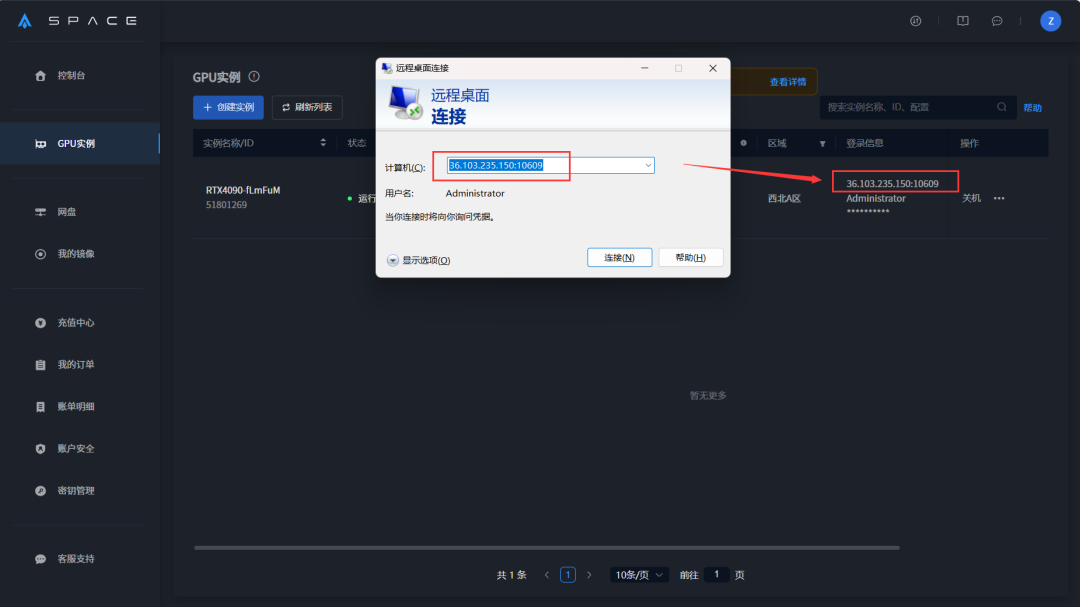
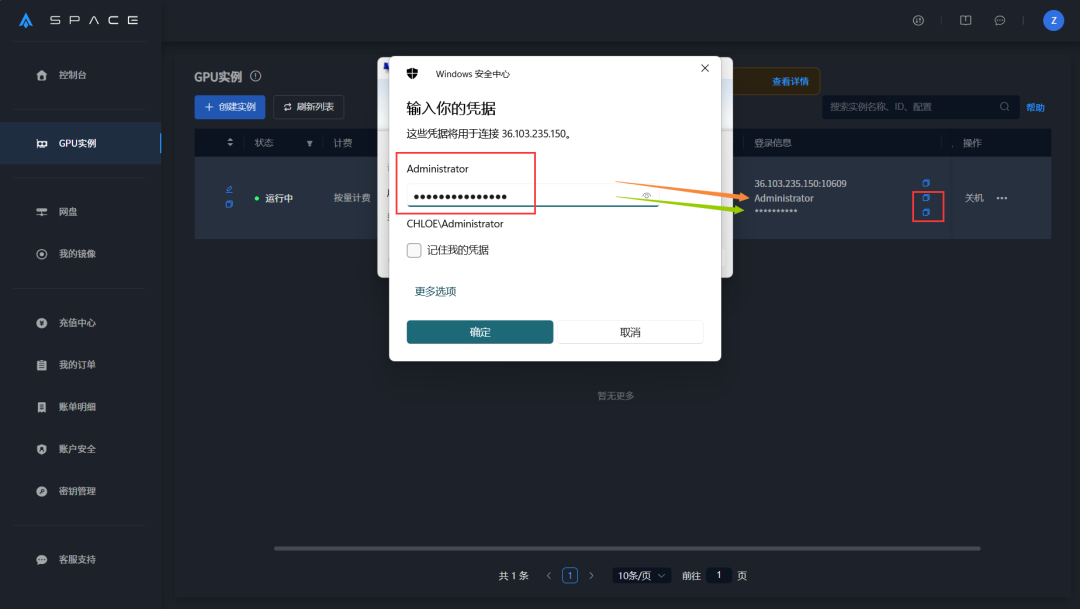
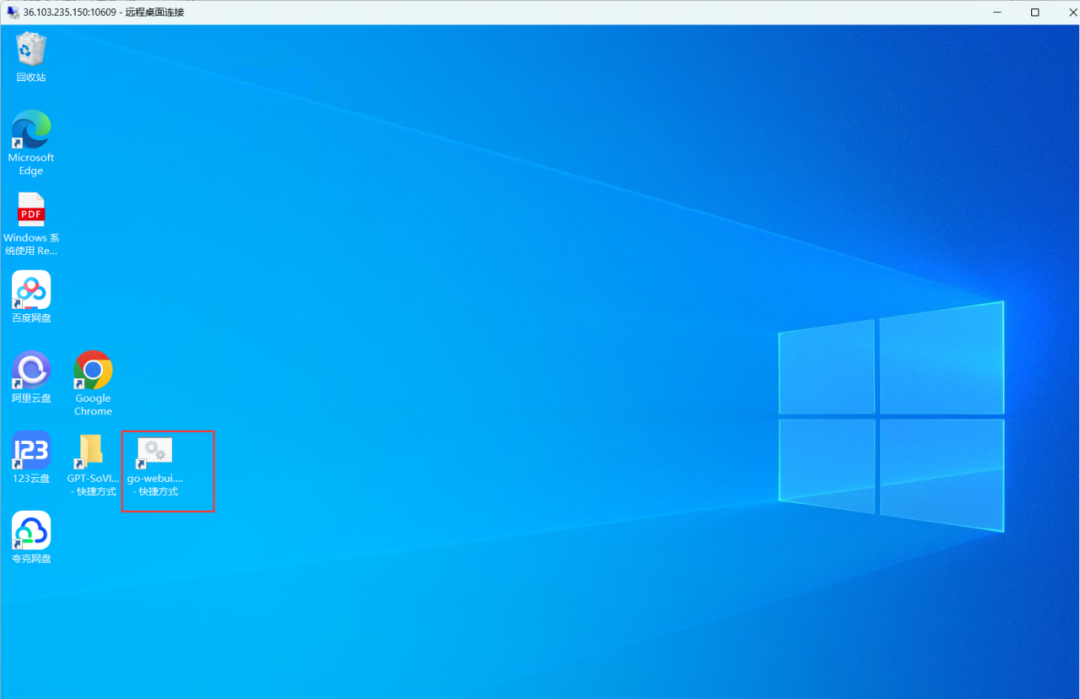
远程桌面连接后会弹出Windows系统,根据引导启动即可。

双击打开igo-webui.bat - 快捷方式,等待命令框显现,单击第二行,回车,就可以进入应用界面。
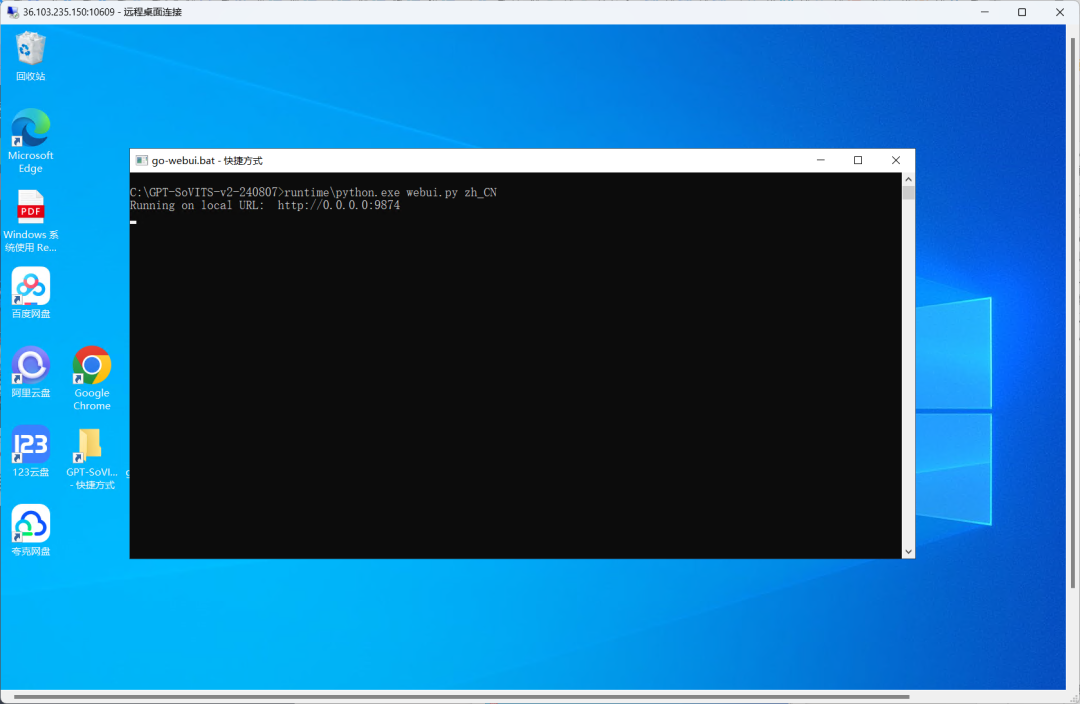
PART.02:镜像操作
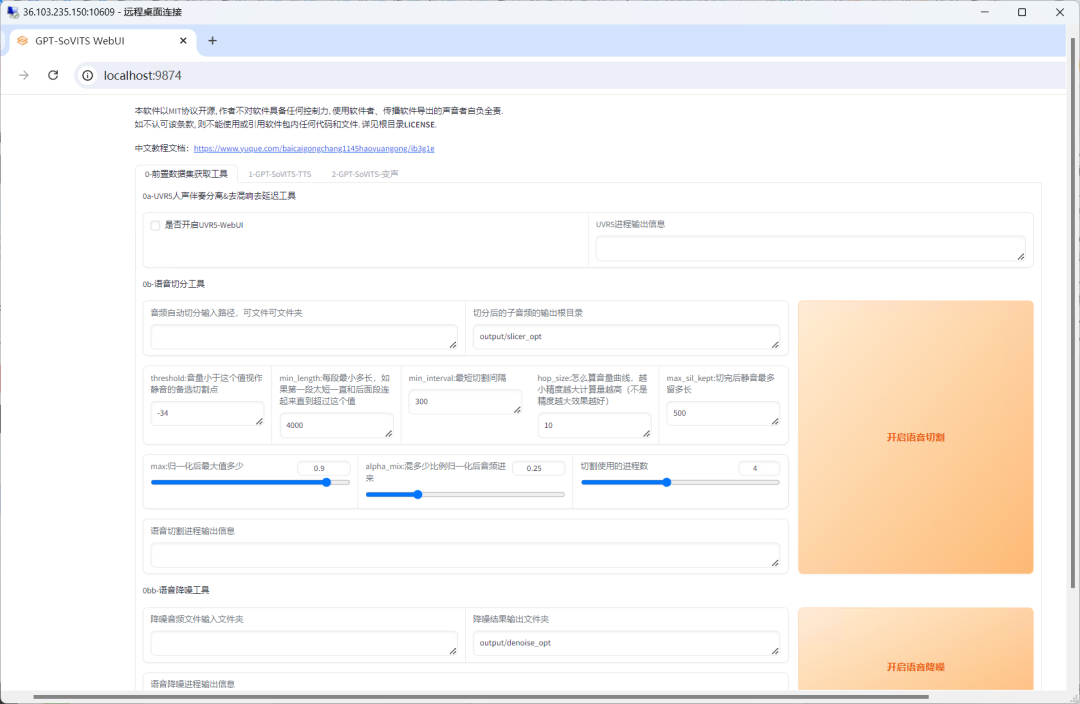
待程序打开后呈现的就是GPT-SoVITS主页面。
01
打开远程桌面中的GPT-SoVITS文件夹,再额外创建一个文件夹(可根据音频人物自由命名),用于放置我们的音频文件。
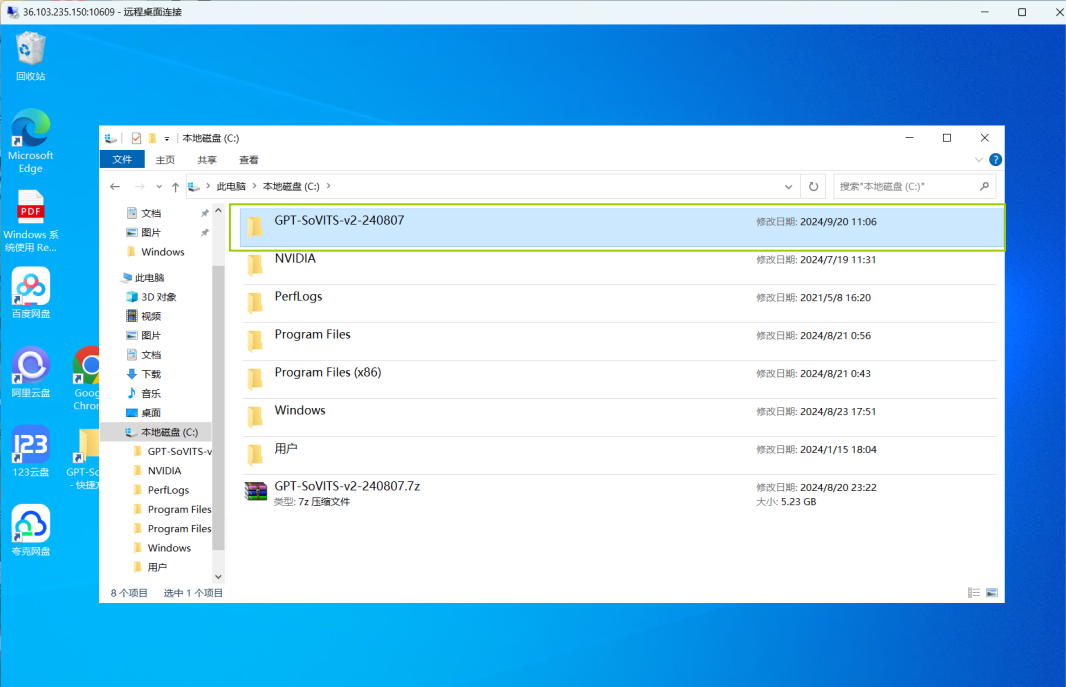
在新创建的文件夹中,另建两个文件夹,一个用于存放事先准备好的音频文件,另一个存放原始音频切片。

02
进入应用后,勾选【是否开启UVR5-WebUI】,对音频进行人声分离。
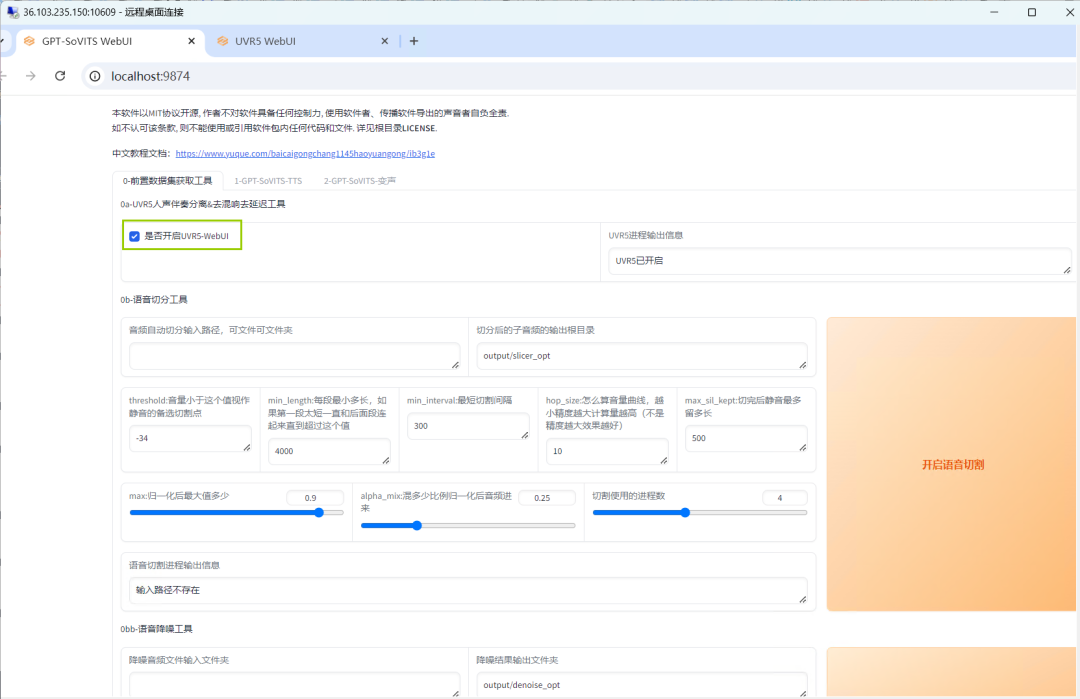
稍等片刻,跳转新的界面后,将需要处理的音频文件地址复制在【输入待处理音频文件夹路径】和【指定输出主人声文件夹】下栏中,选择第一个模型,点击转换,就会生成处理完的音频。
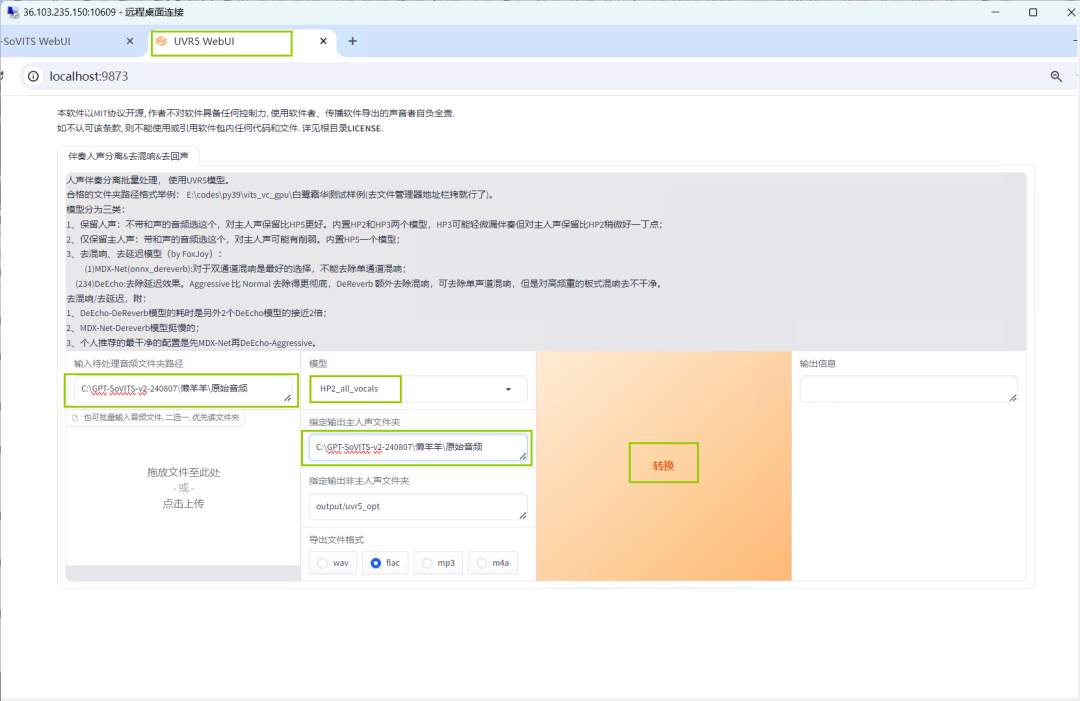
接着在存放原始音频文件夹中,将事先保存的待处理音频文件删除,只保留刚刚处理完成的新音频。
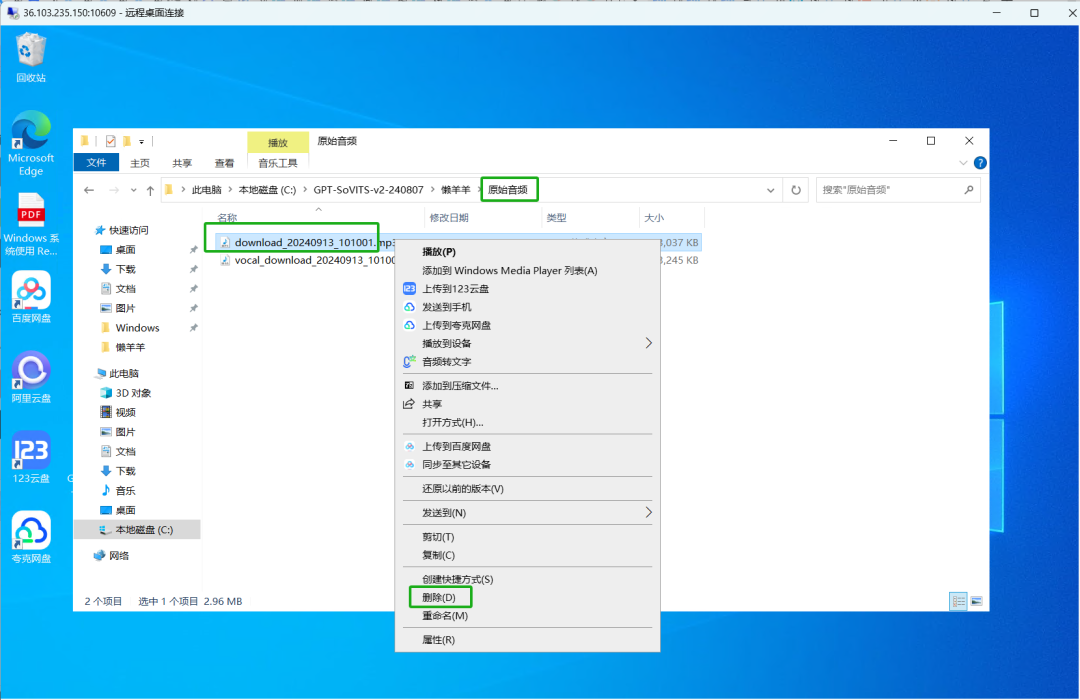
03
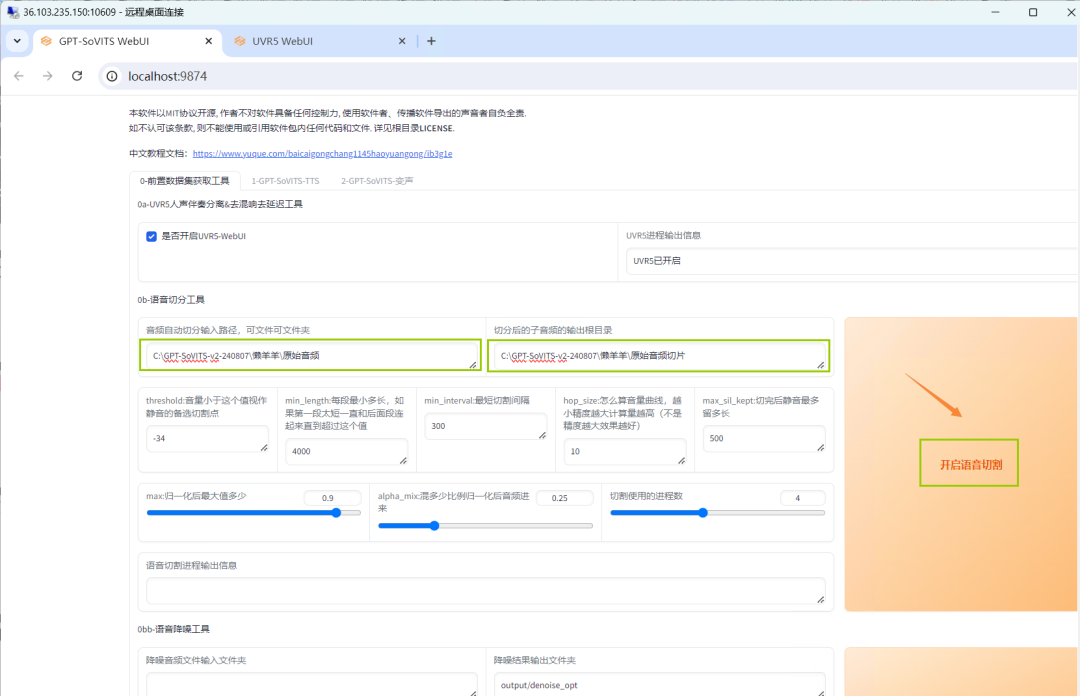
将刚刚处理完的音频文件地址(输入地址)和原始音频切片文件地址(输出地址)分别复制在【音频自动切分输入路径,可文件可文件夹】和【切分后的子音频的输出根目录】下栏中,点击【开启语音切割】,进行音频剪切。
剪切完的音频便保存在了原始音频切片文件夹中。
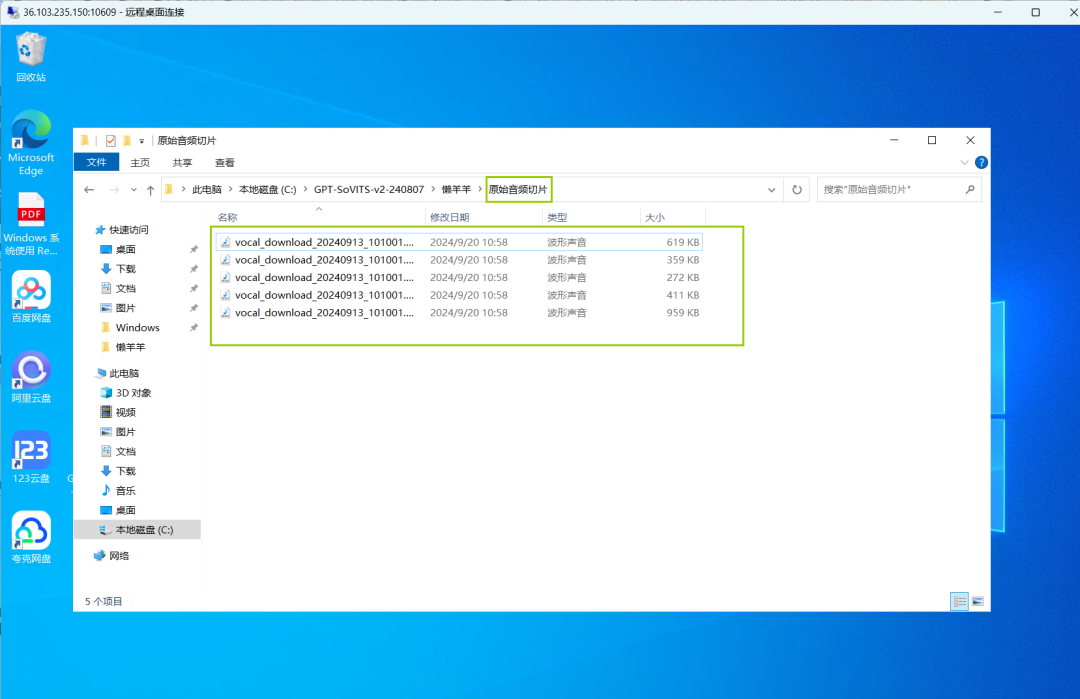
04
接着进行ASR进程,将文件输入输出地址分别填入,单击【开启批量离线ASR】。
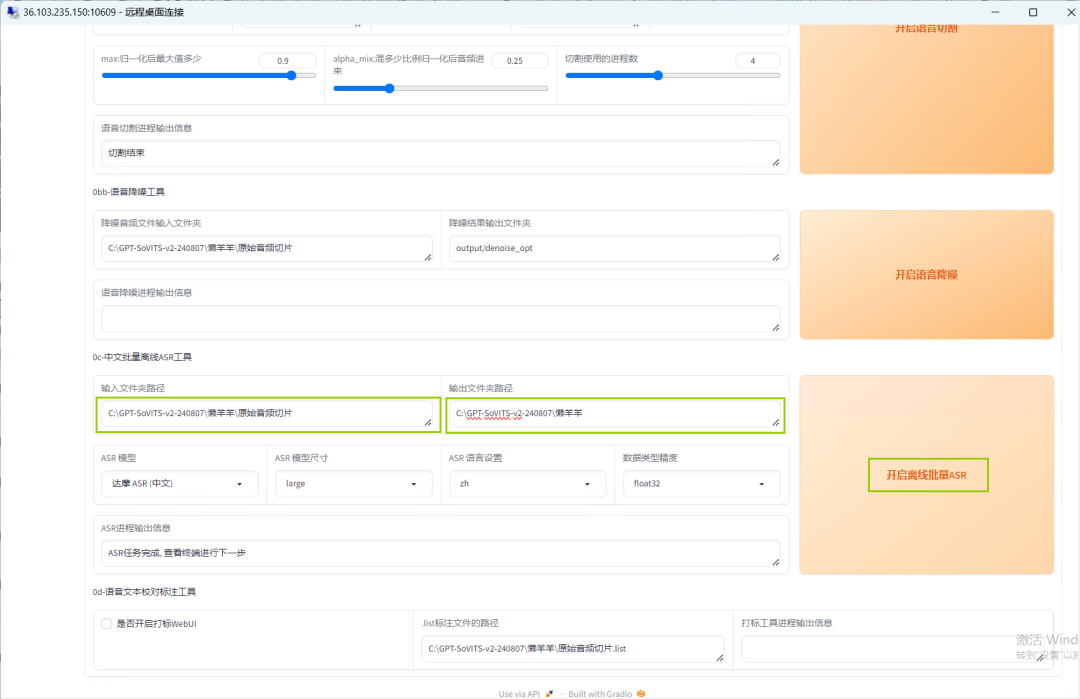
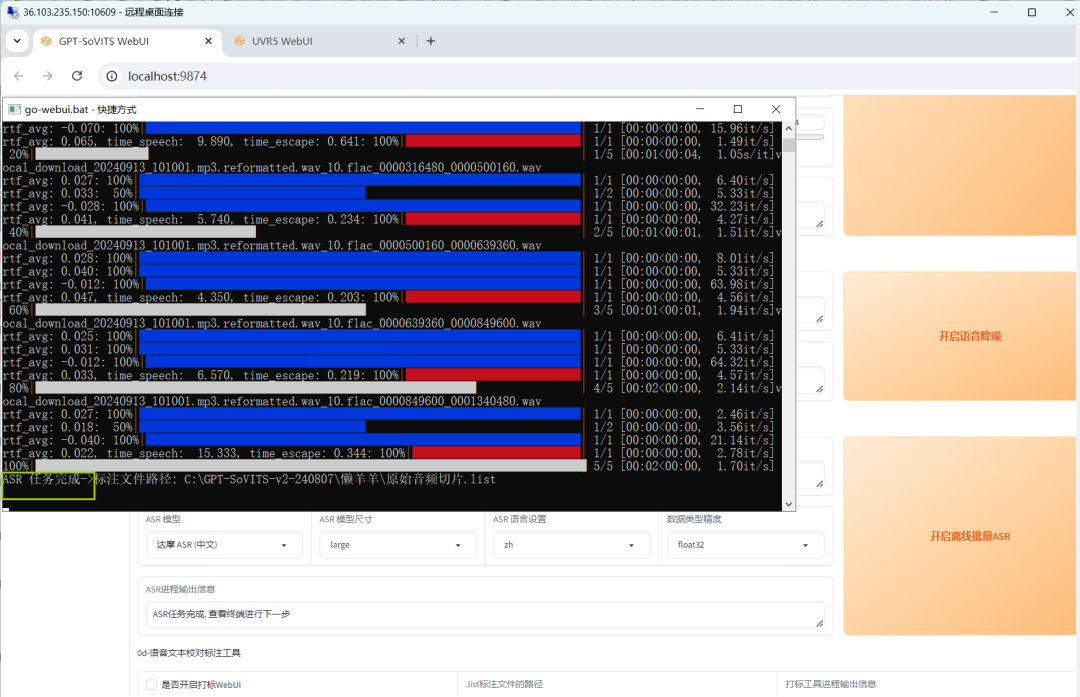
待运行完毕生成的文件将自动保存在输出文件夹中。
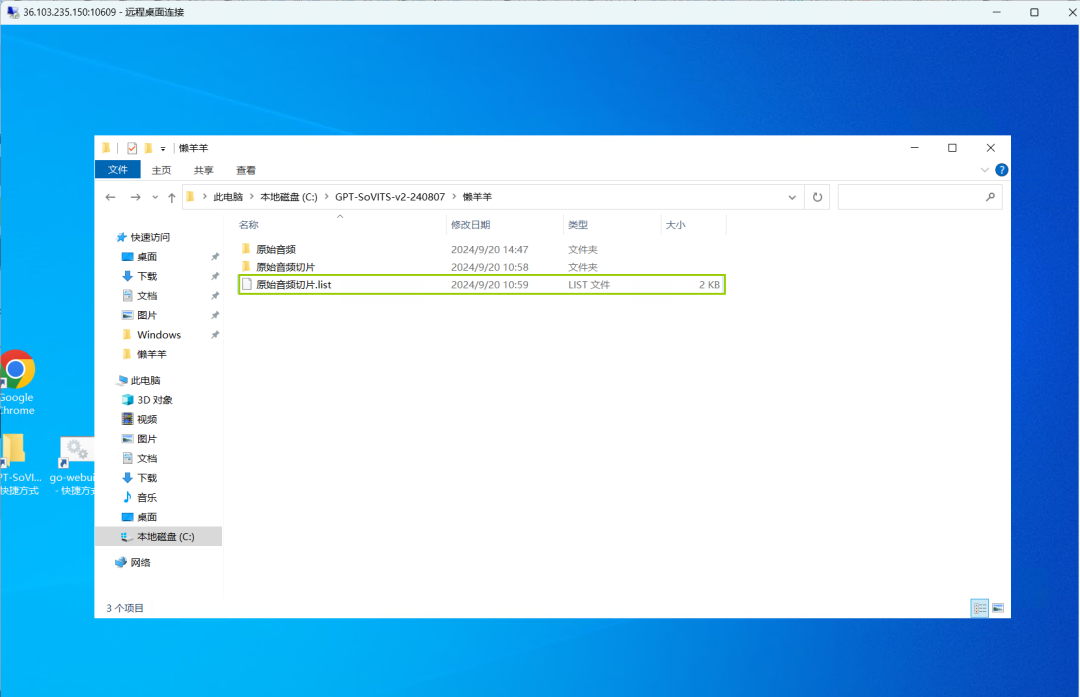
05
下面进行各种训练,点击【1-GPT-SoVITS-TTS】,在【实验/模型名】下栏中输入任务名称,点击【开启一健三连】。
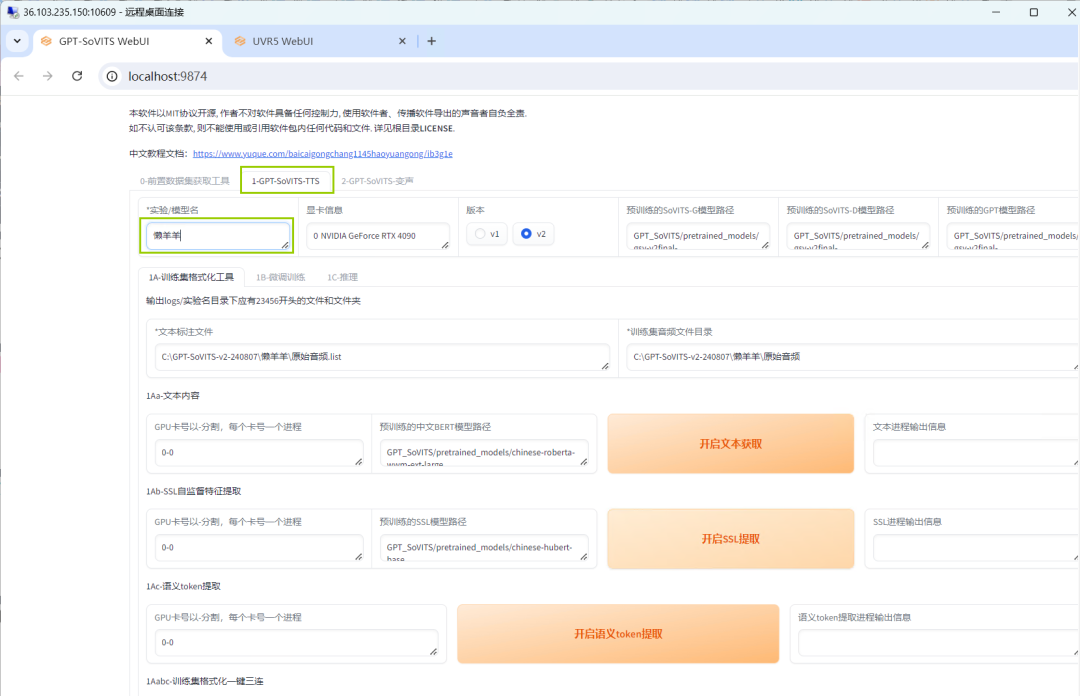
06
待进程完毕后,即可进行下一步操作,点击【1B-微调训练】,先进行SoVITS训练,点击【开启SoVITS训练】,稍等片刻。
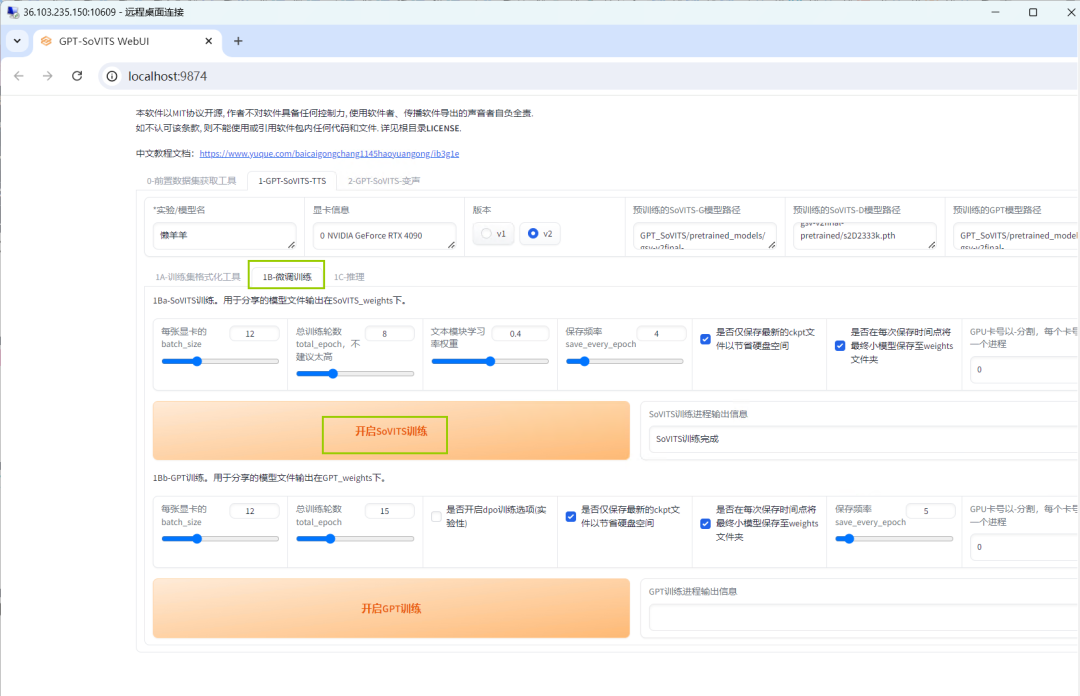
待训练完毕,在【SoVITS训练进程输出信息】下栏中,将会显示【SoVITS训练完成】。
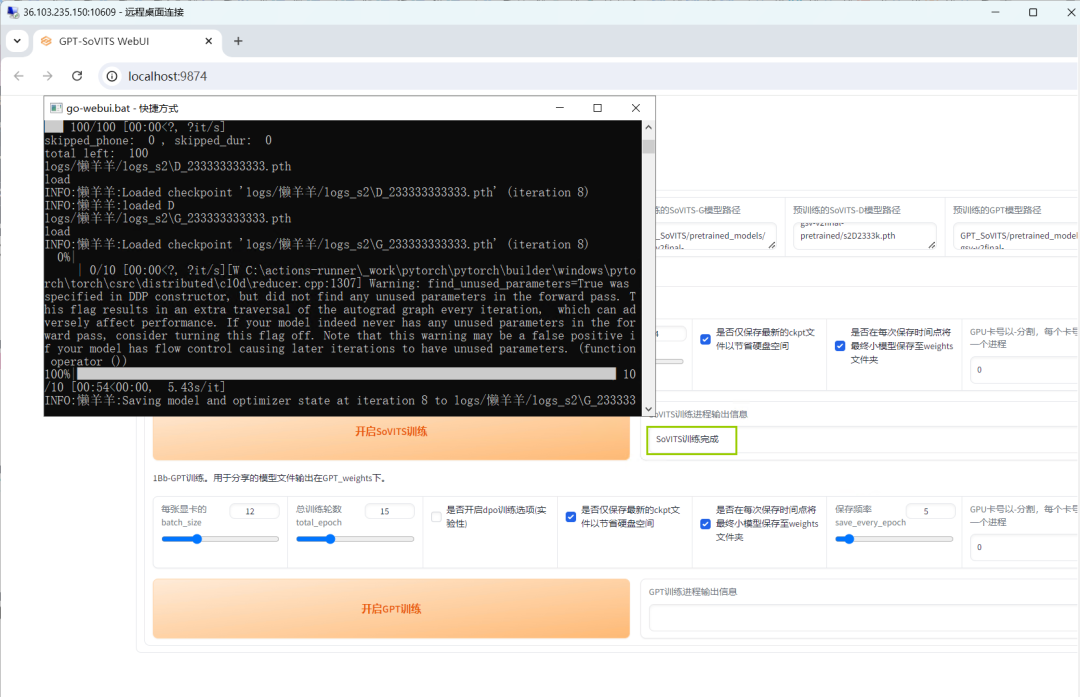
再进行GPT训练,点击【开启GPT训练】,待训练完毕,在【GPT训练进程输出信息】下栏中将会显示【GPT训练完成】。
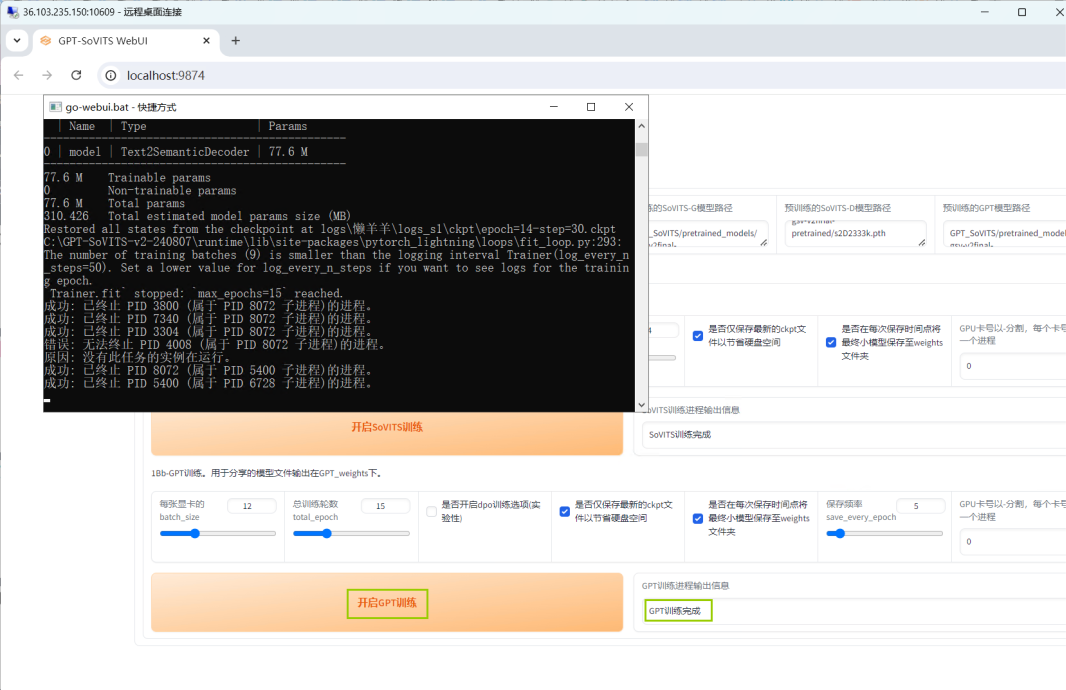
07
进行推理环节,点击【1C-推理】,先刷新路径,在【*GPT模型列表】和【*SoVITS模型列表】下栏中优先选择刚刚训练好数值更大的模型,出图效果会更佳,勾选【是否开启TTS推理WebUI】,进行最后的操作。
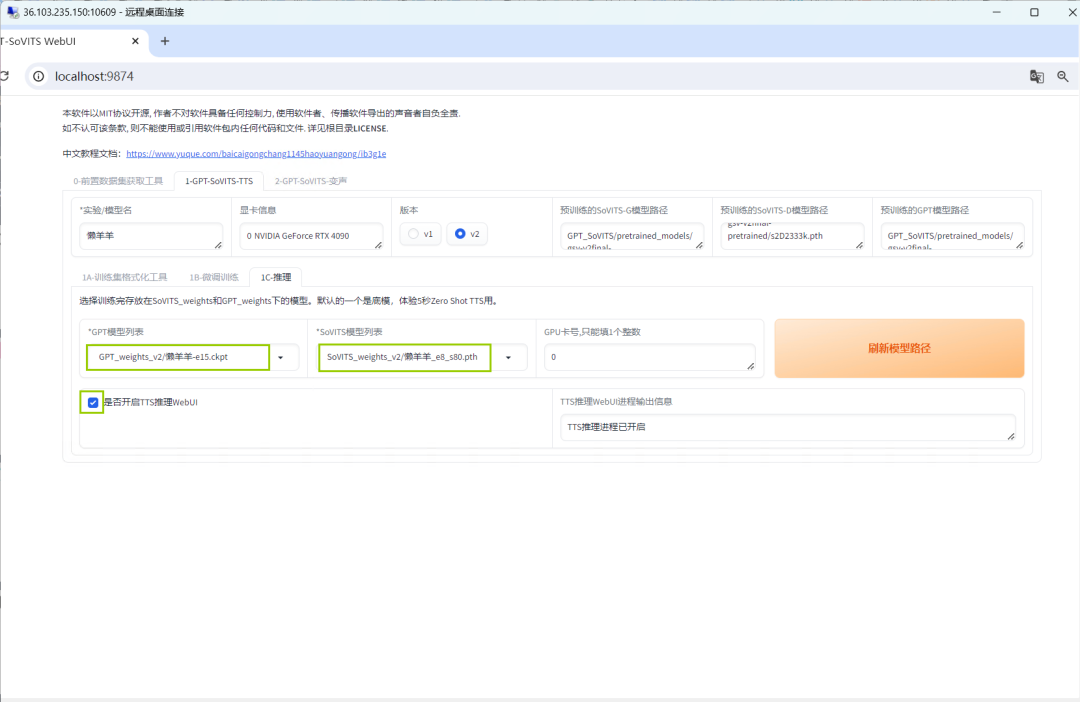
08
从存放原始音频剪切文件夹中上传一个3-10秒的参考音频。
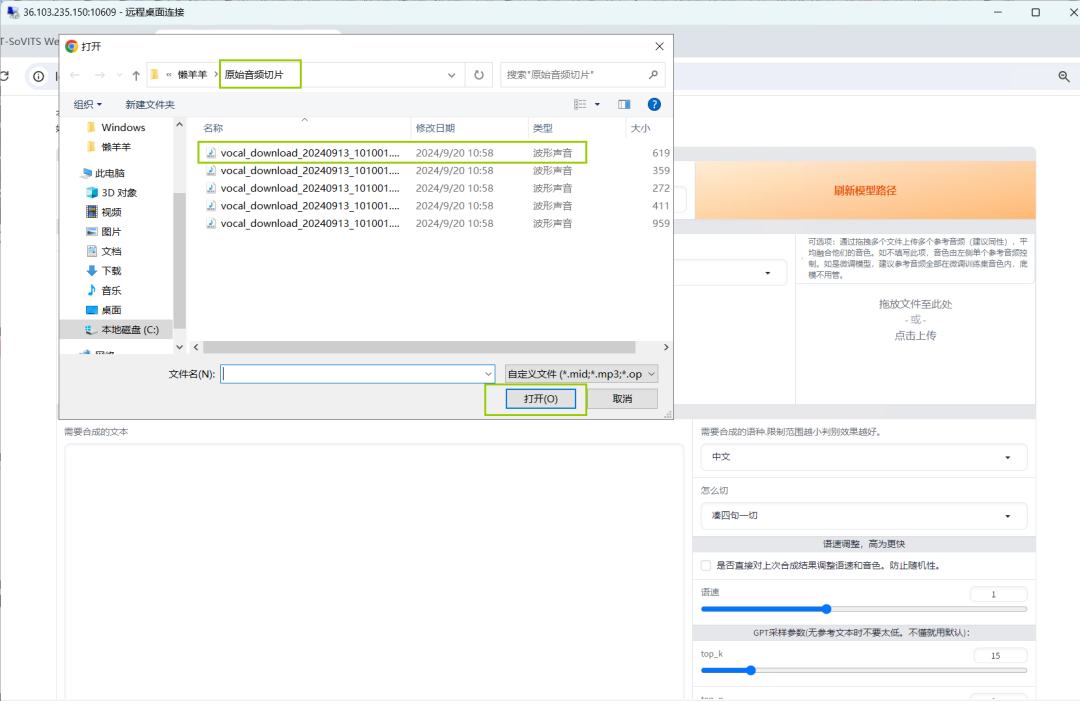
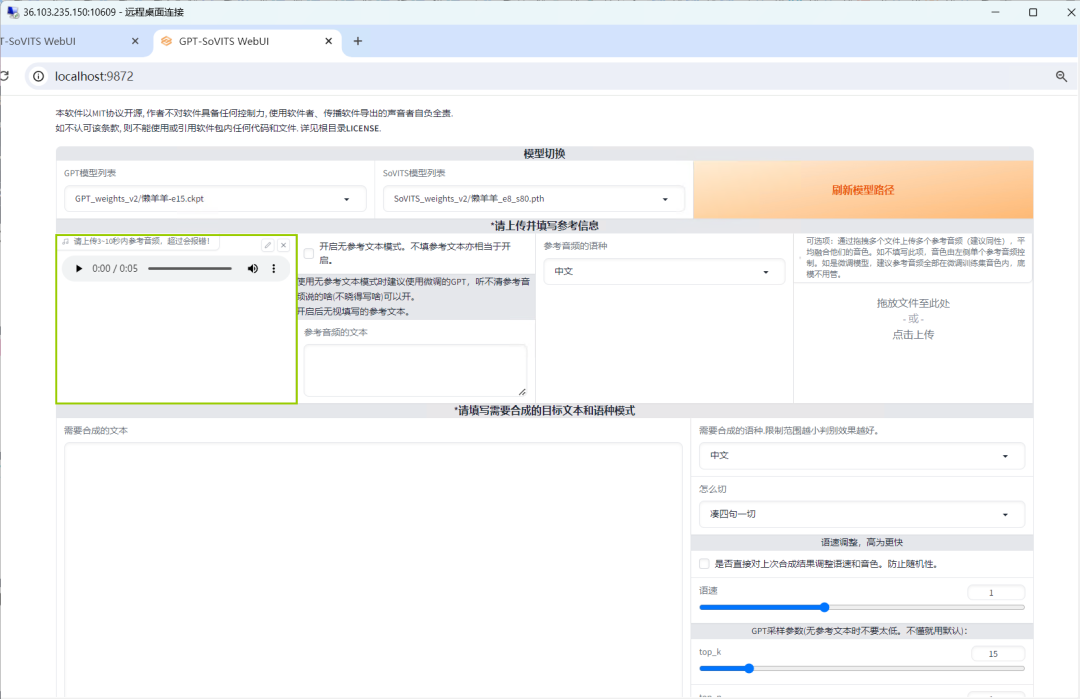
在【需要合成的文本】框内,输入需要合成的目标文本和语种模式,点击【合成语音】,最后的语音效果就呈现出来啦~
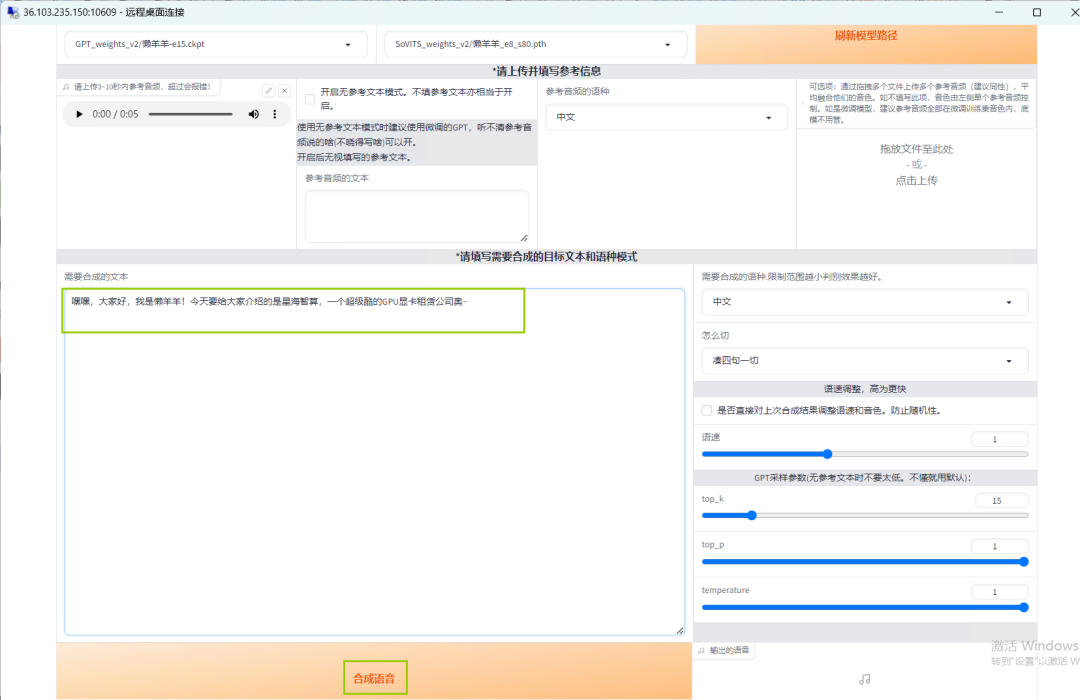
快来星海智算平台使用GPT-SoVITS镜像,让我们一同探索声音的无限可能吧!
关于星海算力云
http:// https://www.spacehpc.com
欢迎使用星海算力云,星海算力云由北京三轴空间科技有限公司开发,由非盈利组织龙游星海算力产业中心运营的高性能GPU算力云平台。
星海团队长期致力于为图像渲染、科研高性能计算等提供服务。星海AI算力服务平台,获超高速增长,团队规模有100余人,服务了国内AI行业的许多一线团队。















 3012
3012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









